
機械学習のアルゴリズム(予測モデル)にはいくつか種類があります。例えば、線形回帰や回帰木、決定木、ランダムフォレストなどがあります。
機械学習アルゴリズムのうち、ランダムフォレストは教師あり学習の分類に属します。
教師あり学習の分類のアルゴリズムには他に、ロジスティック回帰やサポートベクターマシーン(SVM)がありました。
今回は回帰木・決定木を応用したランダムフォレストを用いた予測モデルの作成方法について、具体的な例を用いつつランダムフォレストの特徴〜実装方法まで解説していきます。
決定木、回帰木による機械学習アルゴリズム(予測モデル)の作成方法については以下の記事を参照してください。
-

【機械学習】回帰木・決定木で予測モデルを作成する【手順あり】
続きを見る
では早速、みていきましょう。
ランダムフォレストとは

ランダムフォレストの特徴
決定木モデルは以下の図の様にデータを線で分割していく動作になります。
» 【機械学習】回帰木・決定木で予測モデルを作成する【手順ありで解説】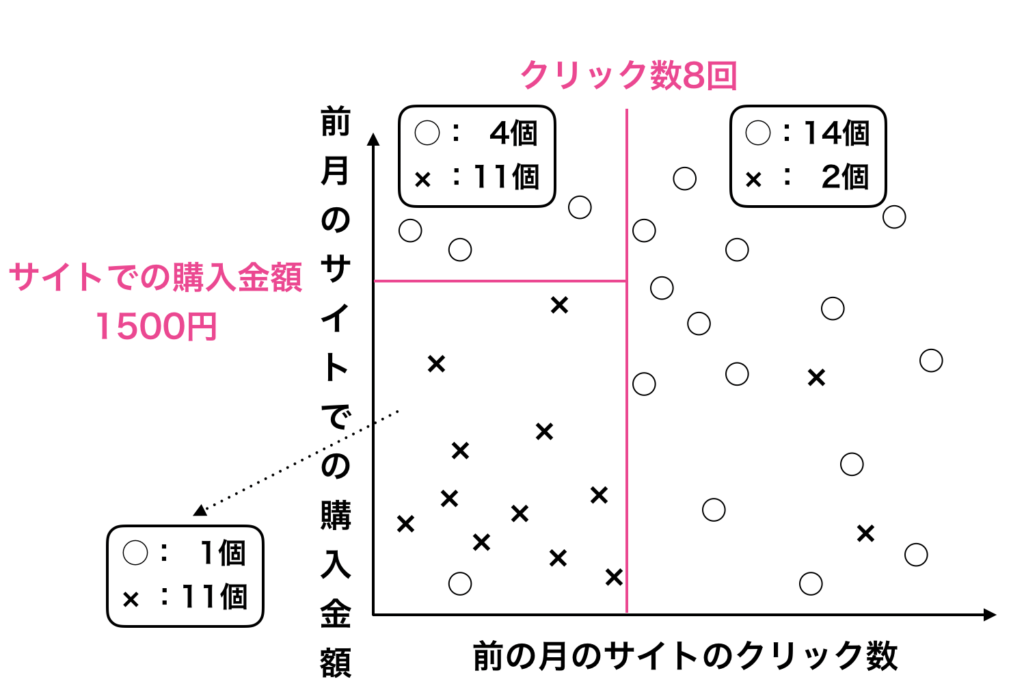
この決定木を用いた予測モデルの作成方法は、過学習がおきやすいアルゴリズムです。
この過学習の問題をクリアにするために使用されるのが今回解説する「ランダムフォレスト」の方法です。
ランダムフォレストは、多様な決定木を多く作り、各々の決定木のアウトプットの多数決を取るアルゴリズムです。
「ランダムフォレスト」の「フォレスト」由来は「森」であり、このアルゴリズムのポイントはいかにして、多数の決定木を重ね合わせて作るか、ということになります。決定木を多く集めることで、ある分類問題をとく方法になります。ランダムフォレストを作る際のポイントは以下の通りです。
ランダムフォレスト作成の際のポイント
- 多様の決定木モデルを用意する。
- 多数の決定木モデルを用意する。
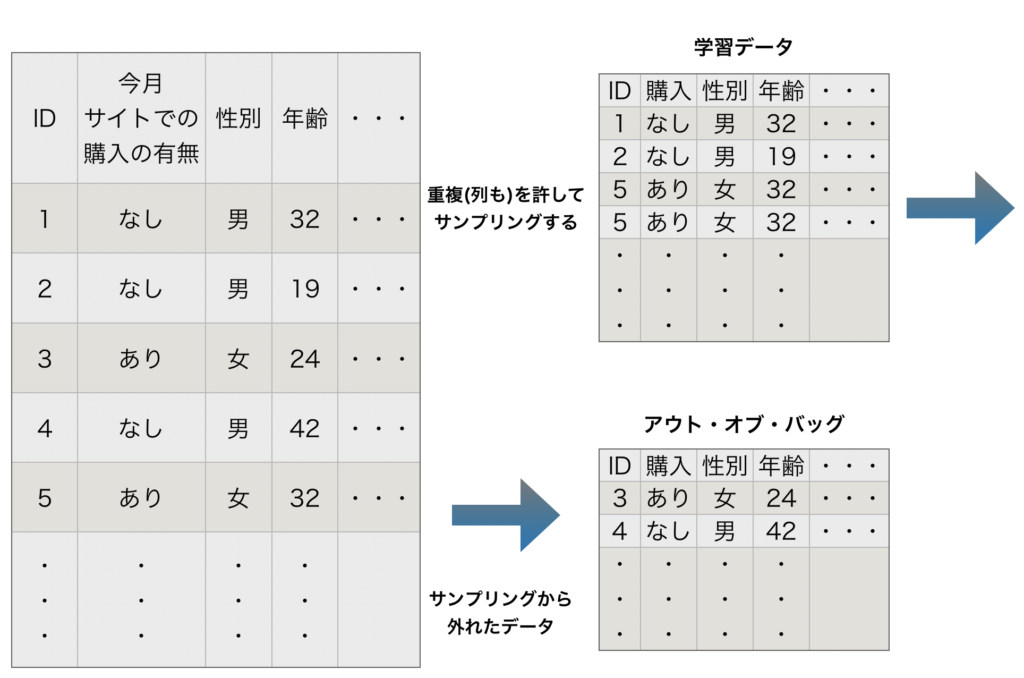
- 同じデータで決定木を多数作成しても、同じ木がたくさんできてしまう。
→ オリジナルのデータセット(訓練データ)から重複を許してランダムにサンプリングする。
→ 同時に列もランダムにサンプリングしたものを作成する。
→ この様にすることで、決定木に多様性が生まれる。(決定木により訓練データに偏りが出る) - 決定木を作る際に学習データとして扱われないデータのことを「アウト・オブ・バッグ(Out-Of-Bag, OOB)」と呼ぶ。
アウト・オブ・バッグのデータは特徴量の重要度の確認や、精度の確認用に使われる。
ランダムフォレストの具体的なイメージ図は以下の様になります。
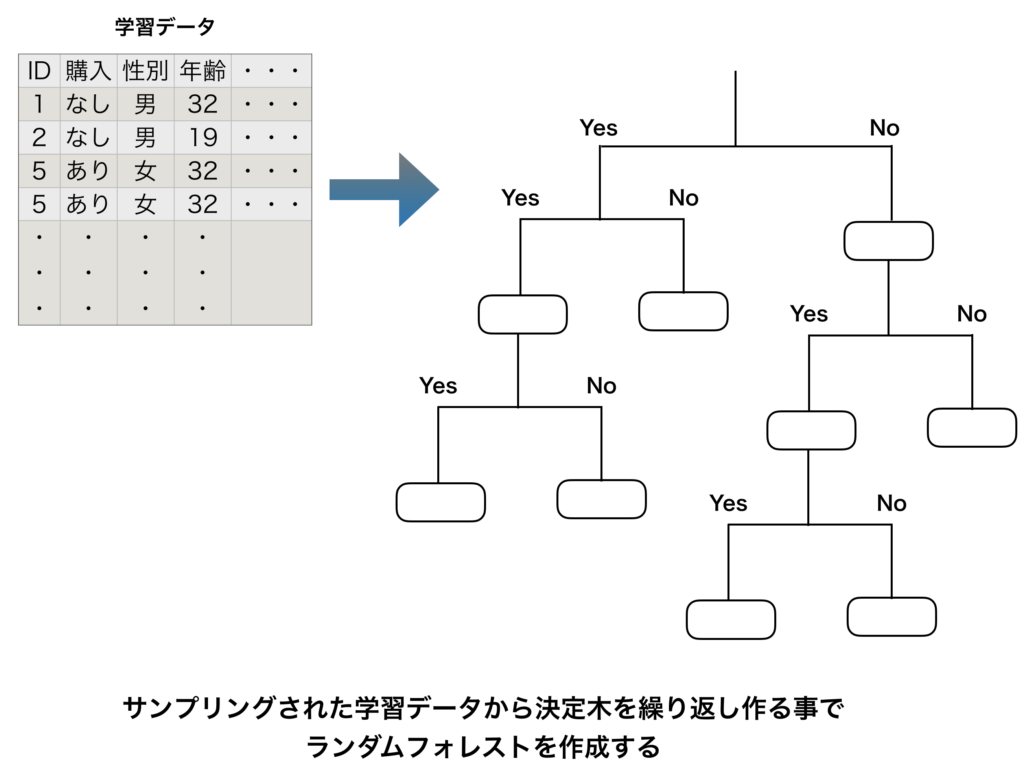
ランダムフォレストの要点
機械学習アルゴリズムを理解する上では(特に教師あり学習のアルゴリズム)、以下の5つのポイントがあります。
教師あり学習を理解する上での5つのポイント
- 予測したい対象の変数(ターゲット変数):連続値やフラグ
- 目的関数
- 関数の形状
- ハイパーパラメーター
- モデルの解釈可能性と予測性能(精度)
この5つのポイントについて、ランダムフォレストでは以下の様に表現する事ができます。
ランダムフォレストでの解釈
- 予測したい対象の変数(ターゲット変数):フラグでも連続変数でもok(※ フラグの場合には決定木、連続限数の場合には回帰木)
- 目的関数:ツリーによって様々
- 関数の形状:ツリーによる多数決が行われる。
すなわち、予測には、各決定木の予測結果の「多数決」が用いられる。
それぞれの決定木が返す結果のうち、最も予測の多かった予測結果のカテゴリが返される。 - ハイパーパラメーター:木(tree)の深さ、木の数、サンプリングする列の数など
- モデルの解釈可能性と予測性能(精度):決定木、回帰木よりも解釈の可能性や予測性能は高い
ランダムフォレストの実装【scikit-learnを利用する方法】

ランダムフォレストは scikit-learn を利用する事で簡単に操作する事ができます。
scikit-learn のうち sklearn.ensemble.RandomForestClassifier が用意されていますので、これを利用しましょう。
» sklearn.ensemble.RandomForestClassifier
In[] ①
1 2 3 4 5 | # ライブラリの読み込み from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_validate from sklearn import datasets iris = datasets.load_iris() |
In[] ②
1 2 3 4 5 6 7 8 9 10 11 12 | # 訓練に使うデータを用意 values = iris['data'][:,2:] labels = iris['target'] # RandomForestClassifierを生成 rfc = RandomForestClassifier(random_state=1) # 5-交差検証 rfc_cv = cross_validate(rfc, values, labels, cv=5) # 正答率を表示 rfc_cv['test_score'].mean() |
Out[]②
1 | 0.9600000000000002 |
まとめ|ランダムフォレストの特徴から実装方法まで
機械学習の教師あり学習のアルゴリズム(予測モデル)にはランダムフォレストの他にも、ロジスティック回帰、線形回帰や回帰木、決定木サポートベクターマシーンがあります。
今回はランダムフォレストの特徴や概念から実装方法までを解説しました。
今回は以上となります。