
こんにちは。
産婦人科医で人工知能の研究をしているTommy(Twitter:@obgyntommy)です。
本記事ではPythonのライブラリの1つである pandas でDataFrameを結合する方法について学習していきます。
pandasの使い方については、以下の記事に基本から応用までを網羅してまとめていますので参考にしてください。
-

【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
本記事の目標はpandasのDataFrameを結合する方法を完全にマスターする事です。
データを処理するときには、色々なデータリソースから取得することがあります。
その際に、複数の分かれているデータは、処理がしづらいので、1つにまとめる事が多々あります。
この様にpandasを用いてDaataFrameのデータを1つに結合する方法について理解していきましょう。
本記事でpandasのDataFrameのデータを結合する方法を習得しつつ、自由自在にデータを扱えるようになりましょう。
PandasのData Frame の概要と作成方法・変換方法についての記事は、以下になりますので参考にして頂ければ知識がまとまるかと思います。
-

【Python】pandas.DataFrameの概要と作成方法・変換方法
続きを見る
ここで本記事の学習到達目標です。
本記事の学習目標
- データの結合する種類の理解
- データを縦方向に結合する方法の理解(append, concatメソッドを利用)
- データを横方向に結合する方法の種類の理解(内部結合、左外部からの結合、右外部からの結合、完全外部からの結合)
- データを横方向に結合する際に利用するメソッド(merge, joinメソッド)の理解
では早速、学習していきましょう。
データの結合の種類について
データの結合の種類について説明します。
データの結合は縦、横方向があり、columns (列名)や index (行名)などをキー値として結合します。
下記表のように、いくつか種類があります。
よく、ベン図を用いて説明もされるので、結合イメージと一緒にベン図を表にしたものが下記になります。
| 種類 | 説明 | イメージ | ベン図 |
| 縦方向 | 縦方向にデータを結合します。 列名が一致している場合、列名が一部一致していない場合があります。 | 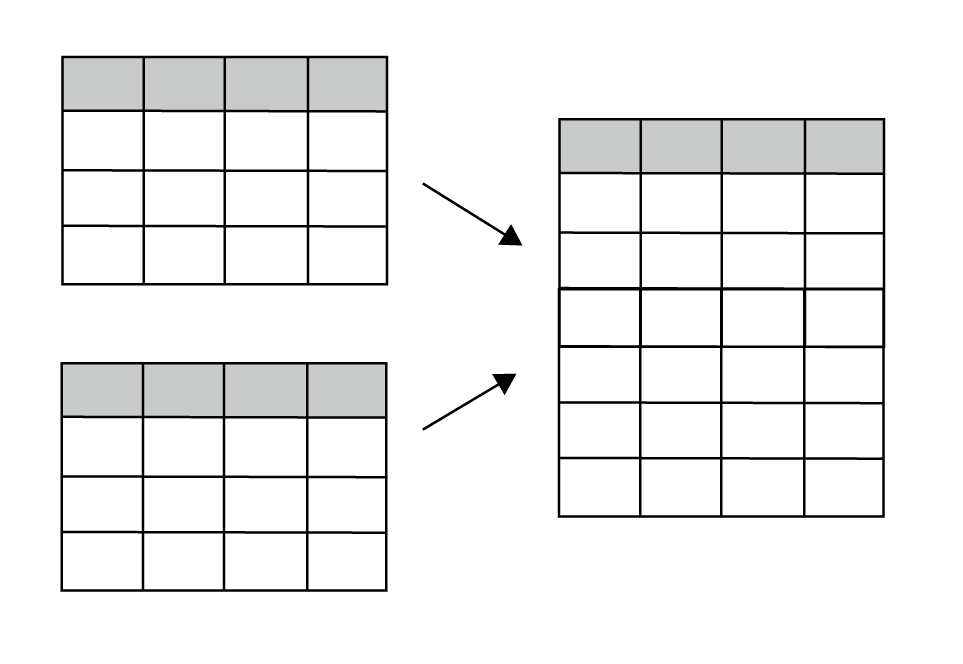 | 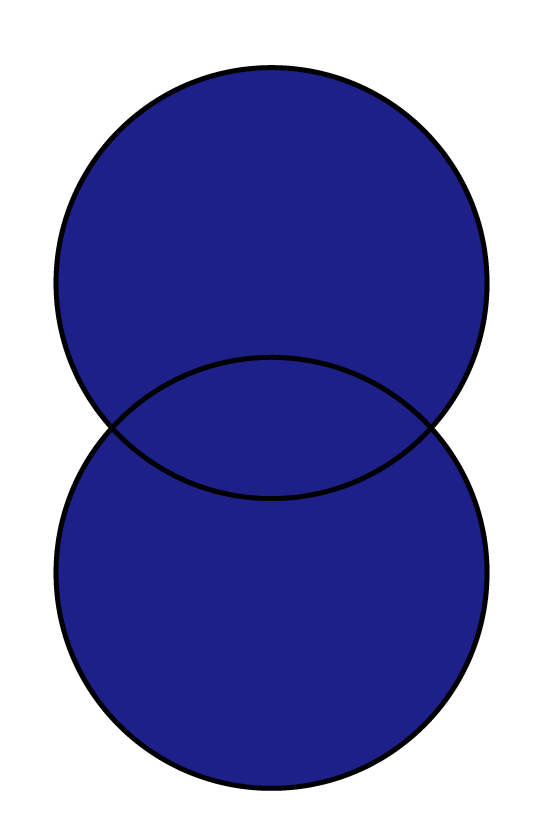 |
| 横方向 内部結合 | 結合するキー値を元に、お互い一致するデータ(右図の場合だと2, 3列)を残します。 | 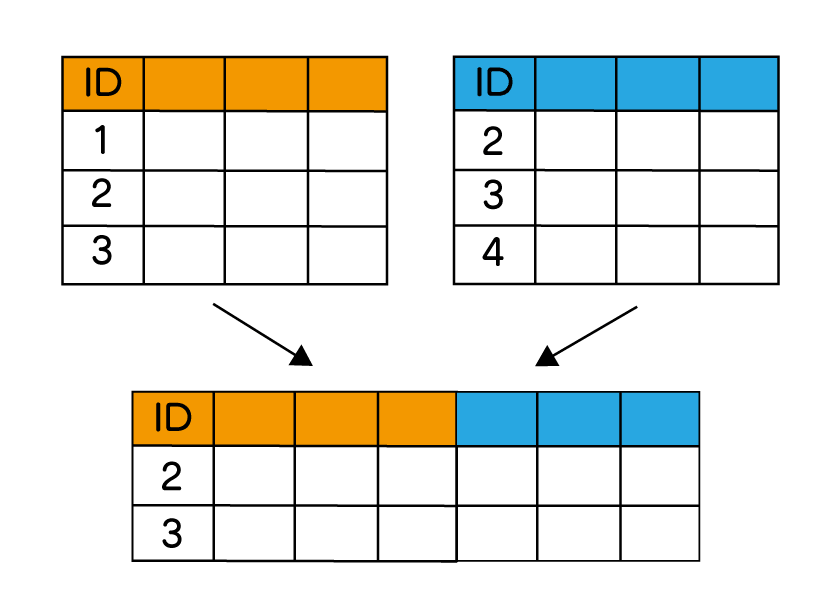 | 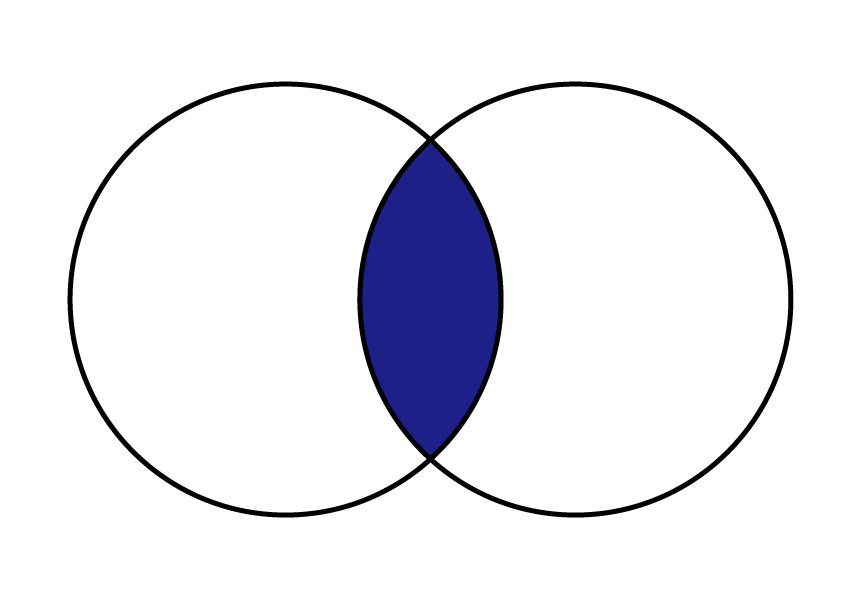 |
| 横方向 左外部結合 | 結合するキー値を元に、左側に一致するデータを残します。 右側にデータがない場合は、NaNとなる。 | 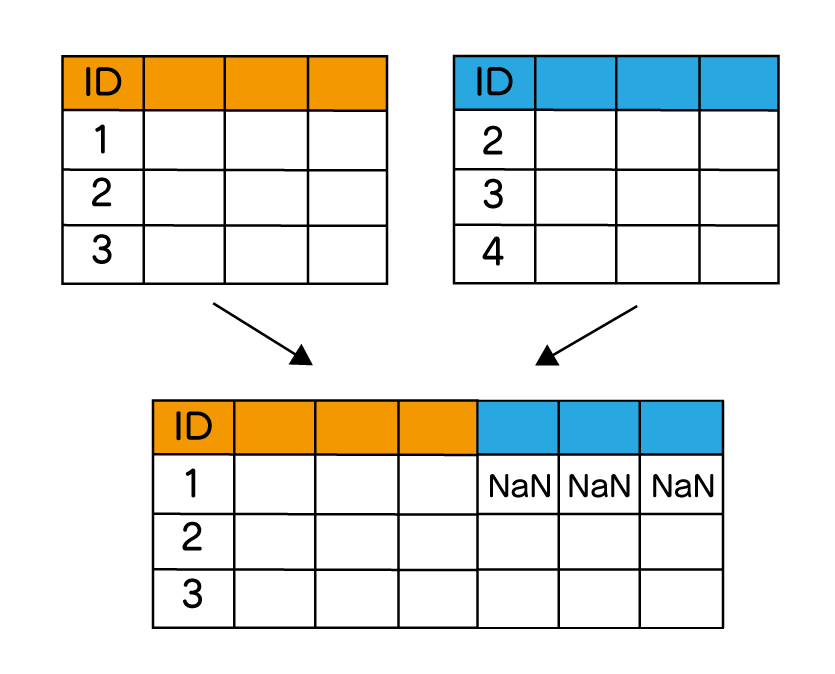 | 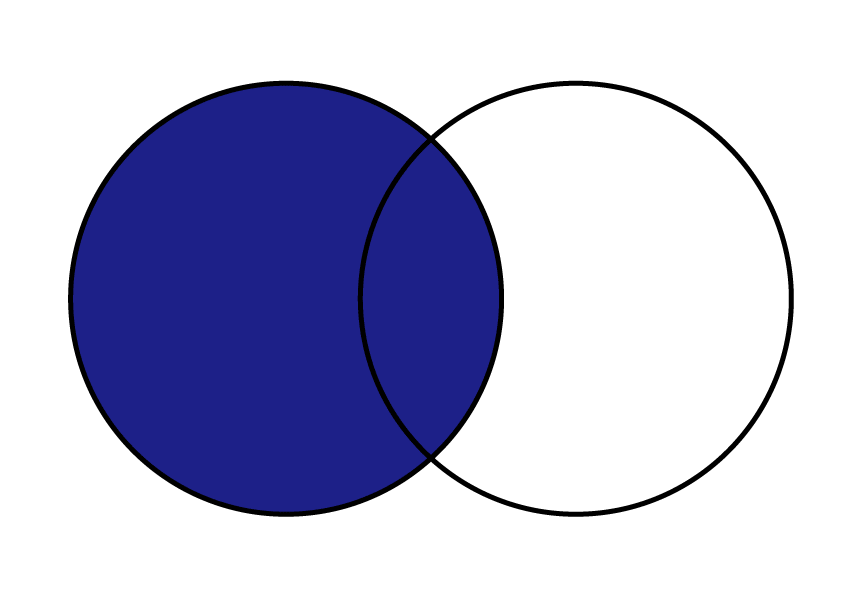 |
| 横方向 右外部結合 | 結合するキー値を元に、右側に一致するデータを残します。 左側にデータがない場合は、NaNとなる。 | 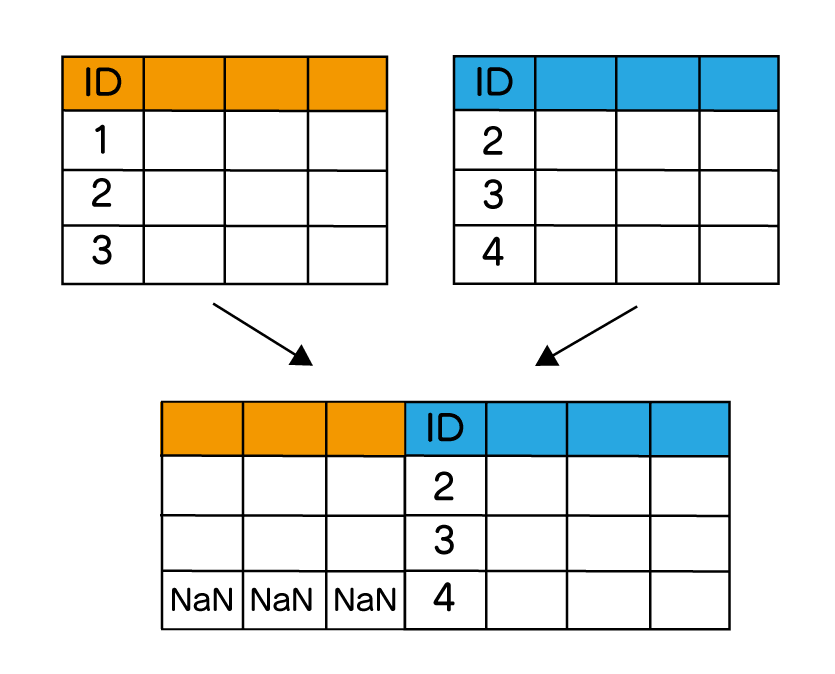 | 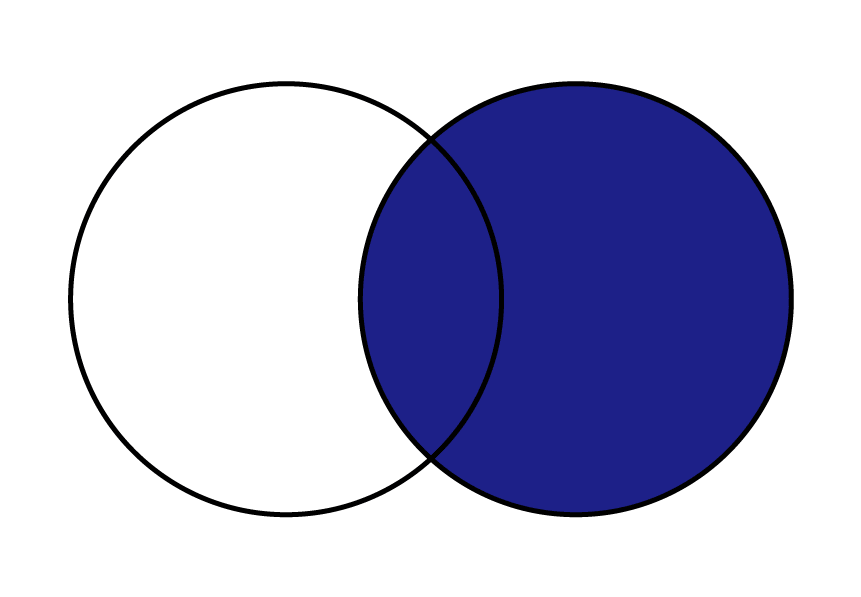 |
| 横方向 完全外部結合 | 結合するキー値を元に、 お互い一致するデータも一致しないデータも残します。 左が一致しない場合、左がNaN、 | 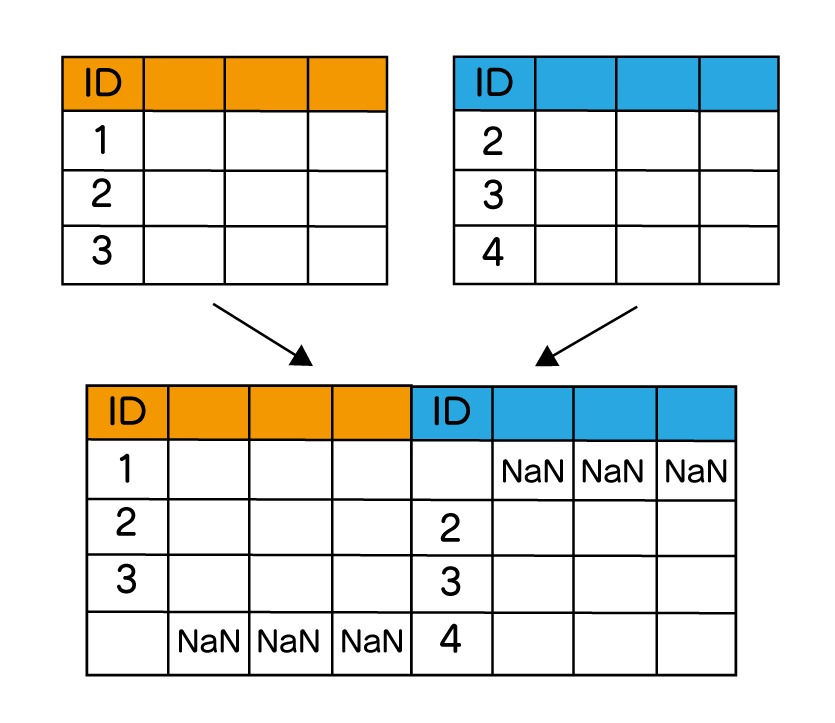 | 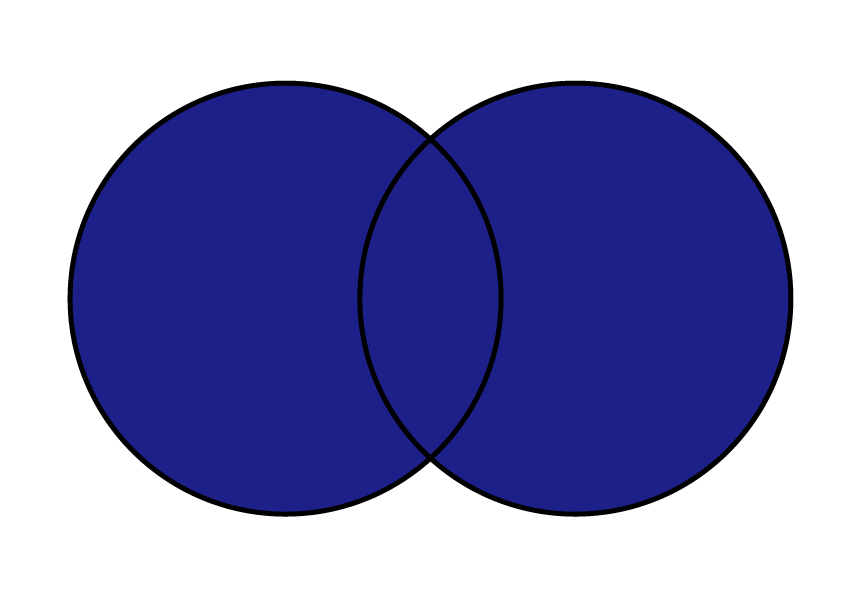 |
この時点では大まかに、結合の種類とそのイメージを掴む事ができれば十分です。
これから、各々の結合の種類について詳しくコードを用いて解説していきます。

縦方向に結合する方法|append(), concat()
縦方向の連結には、append() や concat() メソッドを使います。
以下が縦方向の連結のイメージ図です。
pandas.DataFrame.append の公式メソッドは以下を参照して下さい。
pandas.concat の公式メソッドは以下を参照して下さい。
-
pandas.concat — pandas 3.0.2 documentation
続きを見る

append:新しい行を追加するメソッドconcat:columns(列名)やindex(行名)を参照して結合するメソッド
使用するデータ
理解しやすいように、データ数の少ないデータを用意しましたので、それを使いましょう。
内容は、商品の購入リストが複数あるデータです。
purchase1は商品ID、個数、購入者のラベルpurchase2も商品ID、個数、購入者のラベルpurchase3は商品ID、個数、顧客IDのラベル
この様に、purchase1, 2 は「商品ID」、「個数」「購入者」です。
purchase3 は「購入者」ではなく、「顧客ID」でデータが保存されてています。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import pandas as pd data1 = [['ID1', '2', '山本'], ['ID2', '3', '山本'], ['ID3', '1', '田中'], ['ID4', '2', '鈴木'],] purchase1 = pd.DataFrame(data=data1, columns=['商品ID', '個数', '購入者']) data2 = [['ID2', '5', '佐藤'], ['ID5', '3', '田中'], ['ID6', '1', '佐藤'], ['ID4', '1', '鈴木'],] purchase2 = pd.DataFrame(data=data2, columns=['商品ID', '個数', '購入者']) data3 = [['ID2', '10', 'customer1'], ['ID8', '3', 'customer1'], ['ID9', '4', 'customer3'], ['ID1', '8', 'customer4'],] purchase3 = pd.DataFrame(data=data3, columns=['商品ID', '個数', '顧客ID']) |
Out[]
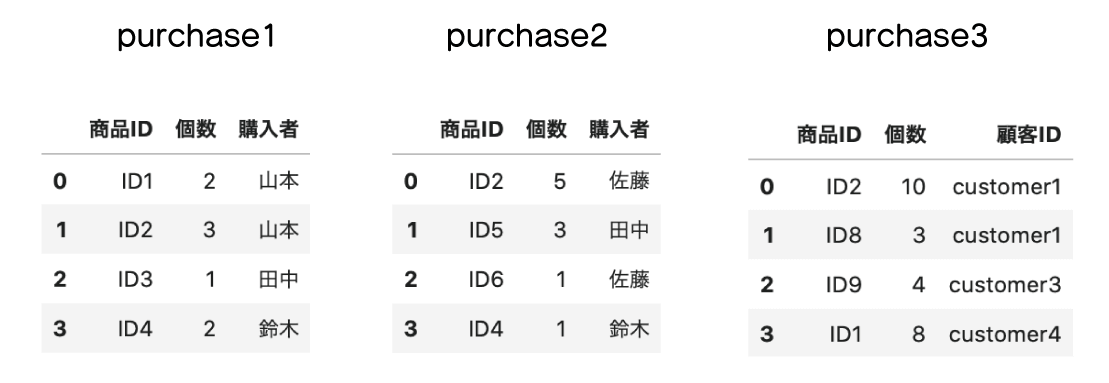
append()メソッド
データを結合する方法としてappend()メソッドを使用しましょう。
append は正確には DataFrame.append です。これは DataFrame のメソッドになります。
DataFrame.append の公式ドキュメントは以下になります。
なので、purchase1 などのDataFrame型の後につけて、引数に、結合したDataFrameを渡します。
列のラベルが同じ場合のデータ結合の仕方
purchase1 と purchase2 のデータを使用して、列のラベルが同じ場合のデータの結合の仕方について確認してみましょう。
In[]
1 2 3 | purchase12 = purchase1.append(purchase2) # データ表示 purchase12.head(8) |
Out[]
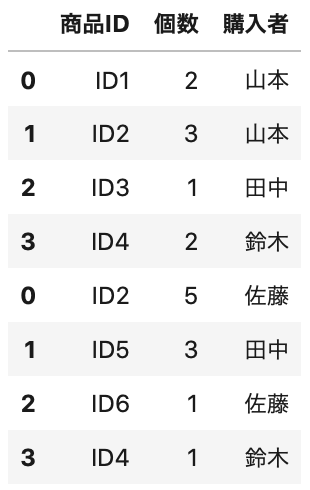
DataFrame の index が、上図の左端の様に 0, 1, 2, 3, 0, 1, 2, 3 となっているのを連番にする場合は、パラメータを ignore_index=True とします。
ignore_index を True にすることで、0, 1, 2, 3, 0, 1, 2, 3 となっているのを、再度数値の連番で割り当て、0, 1, 2, 3, 4,.. としてくれます。
In[]
1 | purchase12 = purchase1.append(purchase2, ignore_index=True) |
列のラベルが一部異なる場合の結合の仕方
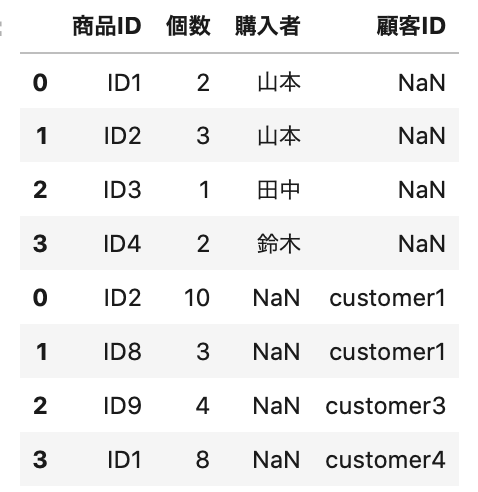
purchase1 と purchase3 を使用して列のラベルが1部異なる場合の結合の仕方について確認しましょう。
列の過不足が DataFrame 間にあっても append() メソッドの使い方は同じです。
どちらかのデータに列が不足している場合は、NaN が割り当てられます。
In[]
1 2 3 | purchase13 = purchase1.append(purchase3) # データ表示 purchase13.head(8) |
Out[]
concat()メソッド
次に、concat() メソッドを使ってみましょう。
concat() は pandasのメソッドになります。
import pandas as pd で pandasをpdと定義しているので、pd の後につけて、pd.concat() と使います。
引数に結合する DataFrame を list型で渡します。
列のラベルが同じ場合の結合の仕方
concat を使って、purchage1 と purchage2 の結合をしてみましょう。
In[]
1 2 3 | purchase12 = pd.concat([purchase1, purchase2]) # データ表示 purchase12.head(8) |
append() メソッドと同じ結果になりますね。
列の値が一部違う場合の結合の仕方について
purchase1 と purchase3 の結合をしてみましょう。
In[]
1 2 3 | purchase13 = pd.concat([purchase1, purchase3]) # データ表示 purchase13.head(8) |
こちらもappend() メソッドと同じ結果ですね。
横方向のデータの結合の方法について

横方向の結合ではconcat()、merge()、join()メソッドを使います。
各々のメソッドの違いについては、以下の様になります。
concat:columns(列名)やindex(行名)を参照して結合するメソッドmerge:キー列を指定して結合するメソッド。indexをキーとすることも可能。join:index(行名)をキーとして結合するメソッド
concat でも結合はできますが、結合するキーが複数 :1 や、相互に対応するキーがない 0:1 がある複雑な結合がではエラーが出ます。
以下の様なイメージです。
その為、merge と join について説明していきます。
join は 下記図のように、キーにしたい列を index にする必要があります。また、必要に応じて index から戻したりと、少しメンドウですよね。
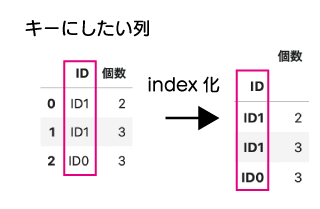 そこでおすすめのメソッドは、
そこでおすすめのメソッドは、merge()メソッドです。
merge() はキーにしたい列を指定して結合できます。
index() にするしないを気にせずに結合でき、コード量少なくすむメリットがあるので、おすすめのメソッドです。
pandas.contact() メソッドの公式ドキュメントは以下になりますので、参考にして下さい。
-
pandas.concat — pandas 3.0.2 documentation
続きを見る
pandas.DataFrame.merge() メソッドの公式ドキュメントは以下になりますので、参考にして下さい。
-
pandas.DataFrame.merge — pandas 3.0.2 documentation
続きを見る

pandas.DataFrame.join() メソッドの公式ドキュメントは以下になりますので、参考にして下さい。
-
pandas.DataFrame.join — pandas 3.0.2 documentation
続きを見る

使用するデータ
理解しやすいように、データ数の少ない用意したデータを使います。
商品の購入リスト(商品ID、個数など)、顧客リスト(購入者)、商品リスト(商品ID)があるイメージです。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | import pandas as pd data1 = [['ID1', '2', '山本'], ['ID2', '3', '山本'], ['ID3', '1', '田中'], ['ID4', '2', '鈴木'], ['ID7', '1', 'ゲスト'],] purchase = pd.DataFrame(data=data1, columns=['商品ID', '個数', '購入者']) data2 = [['customer1', '山本'], ['customer2', '田中'], ['customer3', '鈴木'], ['customer4', '佐藤'], ['customer5', '高橋'],] customer = pd.DataFrame(data=data2, columns=['顧客ID', '顧客名']) data3 = [['ID1', 'りんご', '100'], ['ID2', 'オレンジ', '80'], ['ID3', 'ぶどう', '300'], ['ID4', 'スイカ', '1500'], ['ID5', '桃', '200'], ['ID6', '梨', '150'], ['ID7', 'パイナップル', '400'], ['ID8', 'バナナ', '190'], ['ID9', 'イチゴ', '500'],] product = pd.DataFrame(data=data3, columns=['商品ID', '商品名', '価格']) |
Out[]
indexの設定
join()メソッドはDataFrameの index をキーに結合するメソッドです。
これから、列を index にする方法やリセットする方法について解説していきます。
index は DataFrame の構成要素の行名のようなものです。
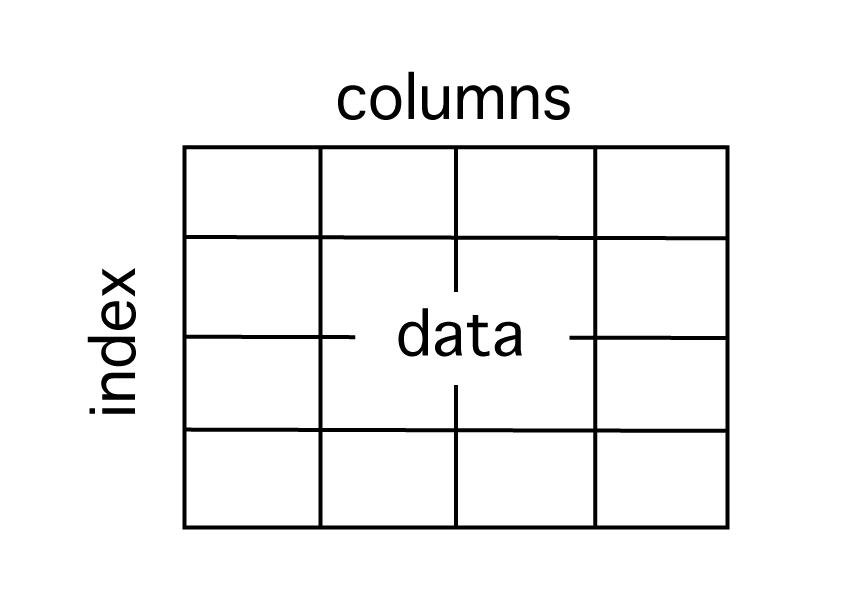
set_index()メソッド
今のデータでは、index は 0, 1, 2, 3… と連番が入っています。
これをキーにして結合したいわけではないので、set_index() メソッドで、indexを変更します。
pandas.DataFrame.set_index() メソッドについての公式ドキュメントは以下になります。
-
pandas.DataFrame.set_index — pandas 3.0.2 documentation
続きを見る

例えば、purchase データの「商品ID」の列を index とする場合は、下記コードを実行します。
In[]
1 2 3 4 | # 商品ID列をindexに purchase_temp = purchase.set_index('商品ID') # データ確認 purchase_temp.head() |
Out[]

reset_index() メソッド
indexを列データから、数値に戻す場合はreset_indexメソッドを使います。
pandas.DataFrame.reset_index() の公式メソッドは以下になります。
-
pandas.DataFrame.reset_index — pandas 3.0.2 documentation
続きを見る

In[]
1 2 3 4 | # indexを数値化 purchase = purchase_temp.reset_index() # データ確認 purchase.head() |
内部結合
内部結合は、二つのデータを指定されたキーで結びつける時、それぞれ存在するデータのみを残します。
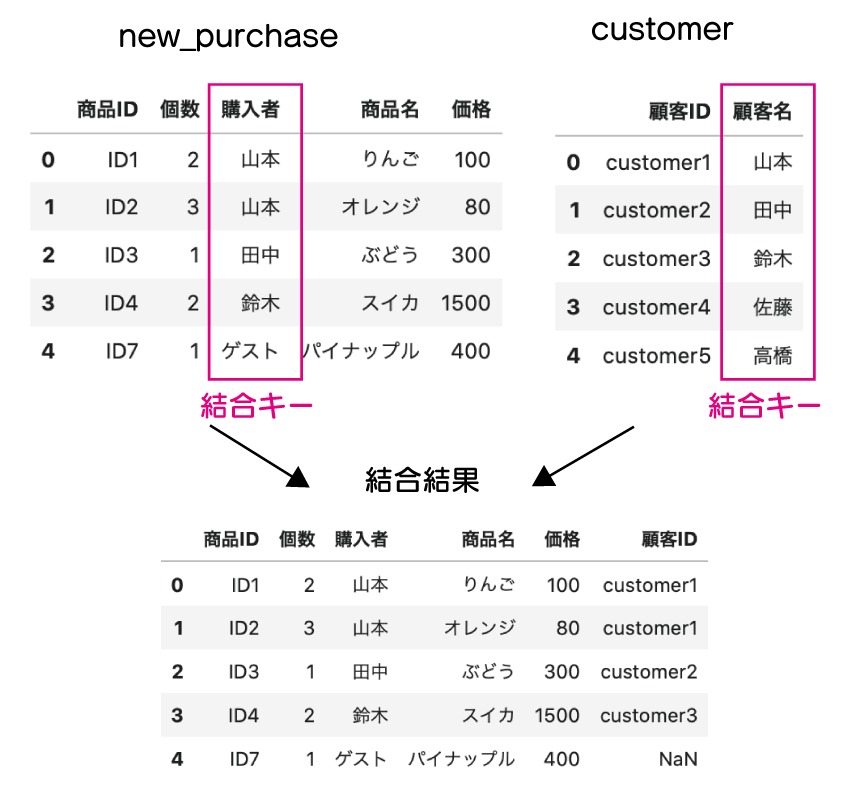
purchase と product の「商品ID」をキーにして結合していきましょう。
次のように結合をして、購入リストにも「商品名」、「価格」が含まれるデータを目指します。
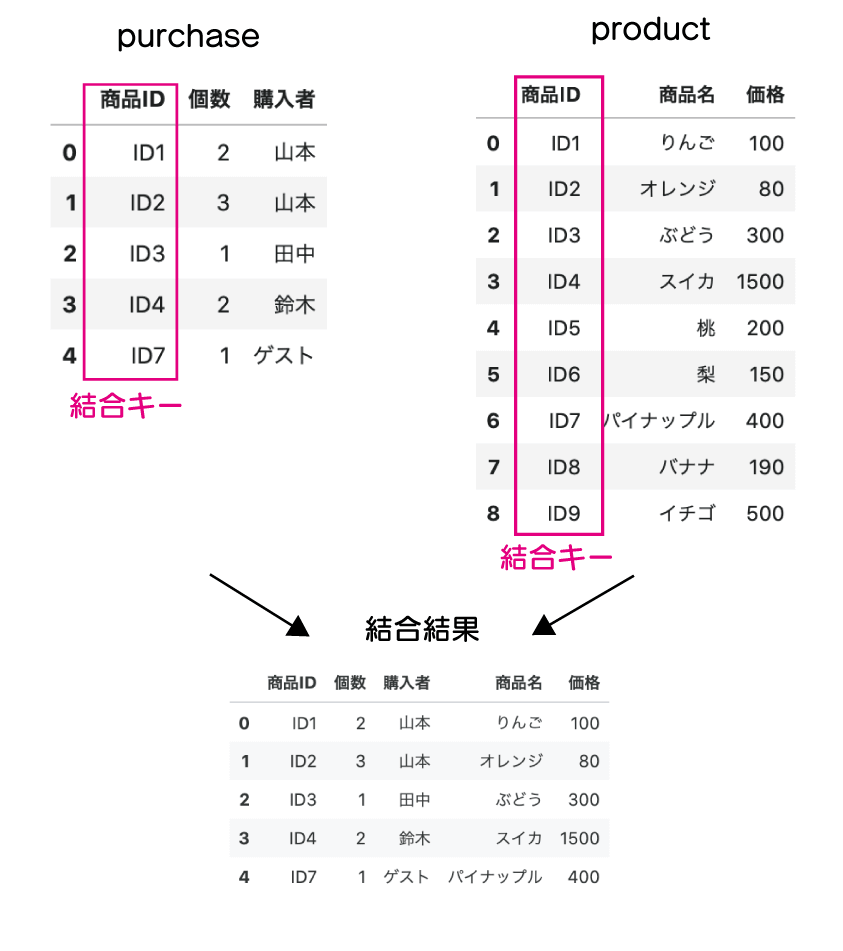
merge() メソッド
merge() メソッドはDataFrameのメソッドなので、DataFrameの後ろにくっ付けて使います。
結合ではデータを左右に並べて、表現します。
下記のコードの様に、メソッドを実行するDataFrameを左のデータ、引数で渡すデータを右のデータとして扱います。

パラメータは次のように設定します。
パラメータの suffixes は今回は使いませんが、 suffixes は結合するデータ同士に同じ列名があると、結合後同じ列が2つできてしまいます。
その為、列名に _x や _y の文字をつけて同じ列になることを防止します。
| パラメータ | 値 | 備考 |
| how | innner | innner: 内部結合(初期値) left:左外部結合 right:右外部結合 outer:完全外部結合 |
| left_on | 商品ID | メソッドを実行するDataFrameのキー列 |
| right_on | 商品ID | 引数で渡すDataFrameのキー列 |
| suffixes | 無し | 左右のデータで重複した列名があったときに 追加する文字列。 tupleで左右の文字列を指定。 初期値(‘ _x ’ , ‘ _y ’) |
それでは、コードを動かしてみましょう。
purchase() のメソッドとして実行します。
In[]
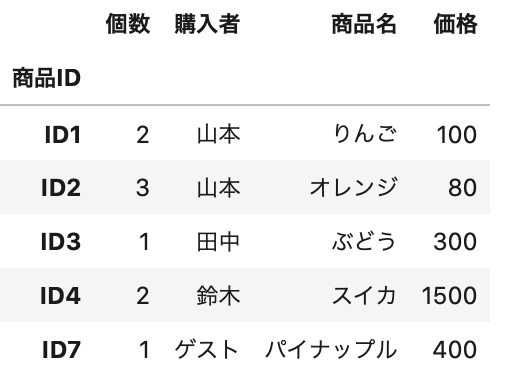
1 2 3 4 | # 結合 new_purchase = purchase.merge(product, how='inner', left_on='商品ID', right_on='商品ID') # データ確認 new_purchase.head() |
Out[]
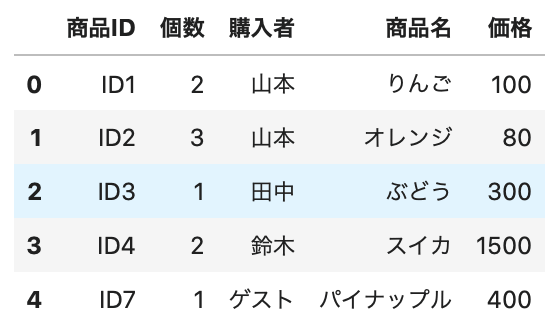
きちんと結合できているのが分かりますね。
left_on 、right_on は今回のように同じ列名で結合する場合は、省略する事も可能です。
初期値が inner なので、how も省略できますが、分かり易さのためにパラメータで指示しておくのが良いでしょう。
省略したコードは下記になります。
In[]
1 2 3 4 | # 結合 new_purchase = purchase.merge(product) # データ確認 new_purchase.head() |
join()メソッド
join() はDataFrameのメソッドなので、DataFrameの後ろにつけて使います。
パラメータは次のようにします。
パラメータの lsuffix 、rsuffix は merge の suffixes と同じ役割です。今回は使いません。
| パラメータ | 値 | 備考 |
| how | innner | innner: 内部結合 left:左外部結合(初期値) right:右外部結合 outer:完全外部結合 |
| lsuffix | 無し | 左右のデータで重複した列名があったときに 左のデータの列に追加する文字 |
| rsuffix | 無し | 左右のデータで重複した列名があったときに 右のデータの列に追加する文字 |
コードを動かしてみましょう。
purchase() のメソッドとして実行します。
In[]
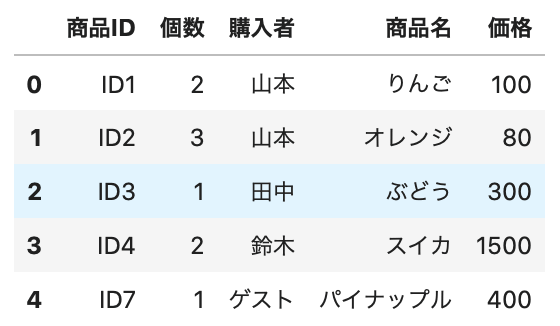
1 2 3 4 5 6 7 | # キー列をindexにする prchase_temp = purchase.set_index('商品ID') product_temp = product.set_index('商品ID') # 結合 new_purchase = prchase_temp.join(product_temp, how='inner') # データ確認 new_purchase.head() |
Out[]
商品IDをキーに、うまく結合できました。
reset_index で index を数値に戻します。
In[]
1 2 3 4 | # indexを数値にする new_purchase = new_purchase.reset_index() # データ確認 new_purchase.head() |
Out[]
左外部結合
左外部結合は、二つのデータを指定されたキーで結びつける時、左のデータは全て残し、右の該当するデータのみを結合します。
以下がイメージ図です。
先ほど作った、new_purchase と customer の「購入者」「顧客名」をキーにして結合していきましょう。
次のように結合して、「顧客ID」が含まれるデータを目指します。
購入者のゲストの箇所は、IDがなく空欄になります。
各メソッド同じ結果を作っているので、ここからはパラメータとコードを紹介していきます。
merge()メソッド
次のパラメータとコードを使います。
| パラメータ | 値 | 備考 |
| how | left | innner: 内部結合(初期値) left:左外部結合 right:右外部結合 outer:完全外部結合 |
| left_on | 購入者 | メソッドを実行するDataFrameのキー列 |
| right_on | 顧客名 | 引数で渡すDataFrameのキー列 |
| suffixes | 無し | 左右のデータで重複した列名があったときに 追加する文字列。 tupleで左右の文字列を指定。 初期値(‘_x’, ‘_y’) |
In[]
1 2 3 4 | # 結合 new_purchase2 = new_purchase.merge(customer, how='left', left_on='購入者', right_on='顧客名') # データ確認 new_purchase2.head() |
Out[]
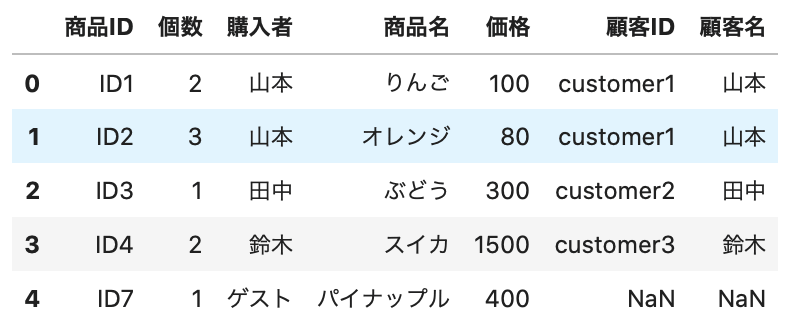
結合列名がそれぞれ違うと、それぞれの列が残るため、「顧客名」列は drop() メソッドで削除します。
pandas.DataFrame.drop() の公式メソッドは以下になりますので、参考にして下さい。
-
pandas.DataFrame.drop — pandas 3.0.2 documentation
続きを見る

In[]
1 2 3 4 | # 顧客名列削除 new_purchase2 = new_purchase2.drop('顧客名', axis=1) # データ確認 new_purchase2.head() |
join()メソッド
次のパラメータとコードを使います。
| パラメータ | 値 | 備考 |
| how | left | innner: 内部結合 left:左外部結合(初期値) right:右外部結合 outer:完全外部結合 |
| lsuffix | 無し | 左右のデータで重複した列名があったときに 左のデータの列に追加する文字 |
| rsuffix | 無し | 左右のデータで重複した列名があったときに 右のデータの列に追加する文字 |
In[]
1 2 3 4 5 6 7 8 9 | # キー列をindexにする new_purchase_temp = new_purchase.set_index('購入者') customer_temp = customer.set_index('顧客名') # 結合 new_purchase2 = new_purchase_temp.join(customer_temp, how='left') # indexを数値化 new_purchase2 = new_purchase2.reset_index() # データ確認 new_purchase2.head() |
Out[]
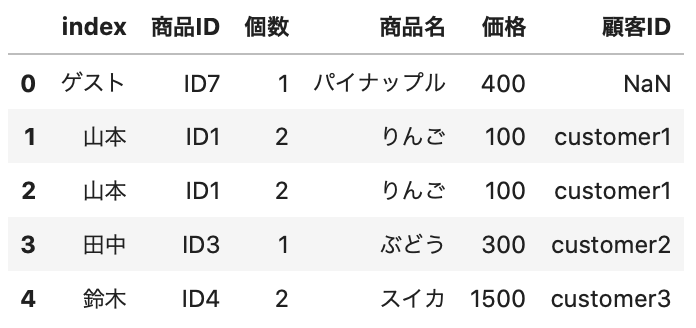
違う列名で結合した場合、reset_index したときに列名が「index」となってしまうので、rename()メソッドを使って、列名を変更します。
pandas.DataFrame.rename() についての公式メソッドについては以下の公式ドキュメントを参考にして下さい。
-
pandas.DataFrame.rename — pandas 3.0.2 documentation
続きを見る

In[]
1 2 3 4 | # 列名を変更 new_purchase2 = new_purchase2.rename(columns={'index': '購入者'}) # データ確認 new_purchase2.head() |
右外部結合
右外部結合は、二つのデータを指定されたキーで結びつける時、右のデータは全て残し、左の該当するデータのみを結合します。
以下の図でイメージを表します。
やっていることは、左外部結合が逆になっただけなので、同じことをデータ入れ替えて行います。
merge や join を実行する DataFrame が new_purchase から customer に変えています。
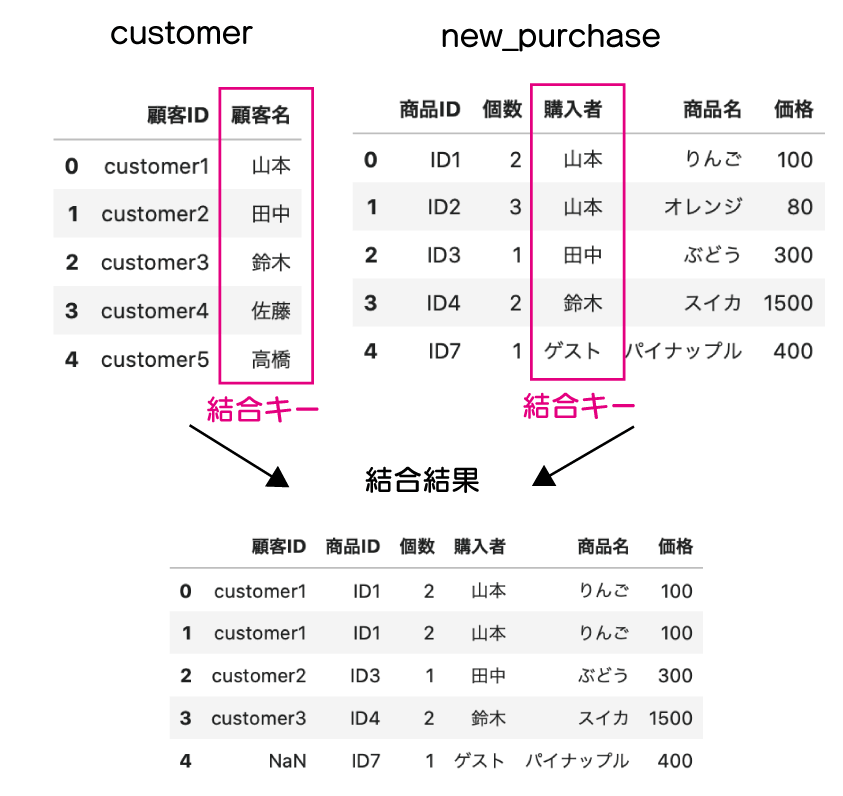
merge()メソッド
次のパラメータとコードを使います。
| パラメータ | 値 | 備考 |
| how | right | innner: 内部結合(初期値) left:左外部結合 right:右外部結合 outer:完全外部結合 |
| left_on | 顧客名 | メソッドを実行するDataFrameのキー列 |
| right_on | 購入者 | 引数で渡すDataFrameのキー列 |
| suffixes | 無し | 左右のデータで重複した列名があったときに 追加する文字列。 tupleで左右の文字列を指定。 初期値(‘_x’, ‘_y’) |
In[]
1 2 3 4 5 6 | # 結合 new_purchase2 = customer.merge(new_purchase, how='right', left_on='顧客名', right_on='購入者') # 顧客名列削除 new_purchase2 = new_purchase2.drop('顧客名', axis=1) # データ確認 new_purchase2.head() |
join()メソッド
| パラメータ | 値 | 備考 |
| how | right | innner: 内部結合 left:左外部結合(初期値) right:右外部結合 outer:完全外部結合 |
| lsuffix | 無し | 左右のデータで重複した列名があったときに 左のデータの列に追加する文字 |
| rsuffix | 無し | 左右のデータで重複した列名があったときに 右のデータの列に追加する文字 |
In[]
1 2 3 4 5 6 7 8 9 10 11 | # キー列をindexにする new_purchase_temp = new_purchase.set_index('購入者') customer_temp = customer.set_index('顧客名') # 結合 new_purchase2 = customer_temp.join(new_purchase_temp, how='right') # indexを数値化 new_purchase2 = new_purchase2.reset_index() # 列名を変更 new_purchase2 = new_purchase2.rename(columns={'index': '購入者'}) # データ確認 new_purchase2.head() |
完全外部結合
完全外部結合は左右のデータをそれぞれ残しつつ、結合します。
今回のデータでは適切な例ではないですが、new_purchase と customer の「購入者」「顧客名」をキーにして結合していきましょう。
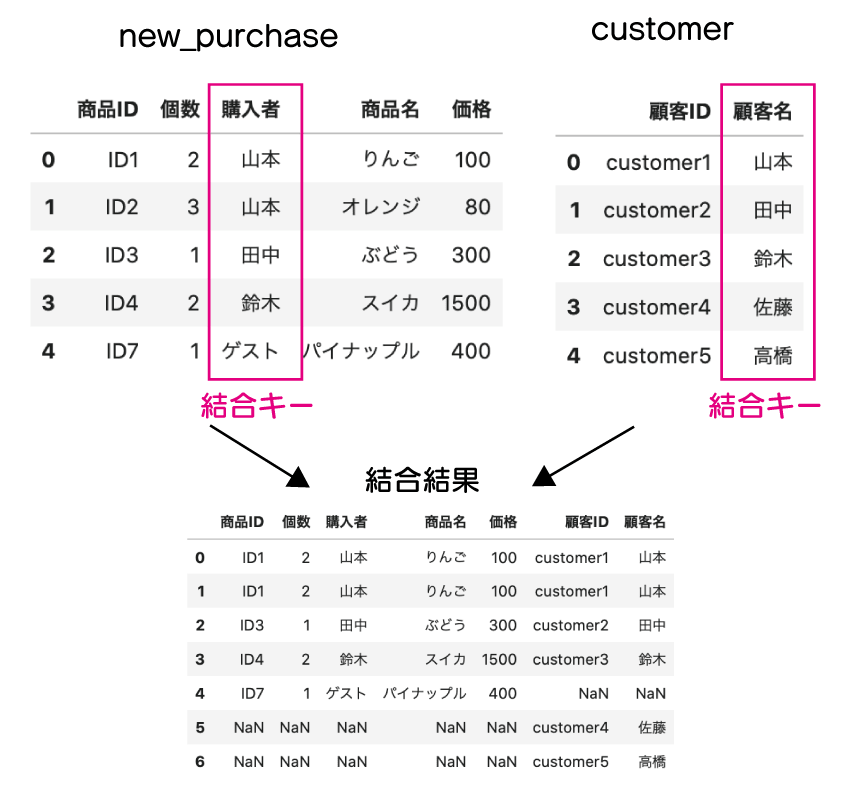
merge()メソッド
次のパラメータとコードを使います。
| パラメータ | 値 | 備考 |
| how | outer | innner: 内部結合(初期値) left:左外部結合 right:右外部結合 outer:完全外部結合 |
| left_on | 購入者 | メソッドを実行するDataFrameのキー列 |
| right_on | 顧客名 | 引数で渡すDataFrameのキー列 |
| suffixes | 無し | 左右のデータで重複した列名があったときに 追加する文字列。 tupleで左右の文字列を指定。 初期値(‘_x’, ‘_y’) |
In[]
1 2 3 4 | # 結合 new_purchase2 = new_purchase.merge(customer, how='outer', left_on='購入者', right_on='顧客名') # データ確認 new_purchase2.head(7) |
join
次のパラメータとコードを使います。
| パラメータ | 値 | 備考 |
| how | right | innner: 内部結合 left:左外部結合(初期値) right:右外部結合 outer:完全外部結合 |
| lsuffix | 無し | 左右のデータで重複した列名があったときに 左のデータの列に追加する文字 |
| rsuffix | 無し | 左右のデータで重複した列名があったときに 右のデータの列に追加する文字 |
In[]
1 2 3 4 5 6 7 8 9 10 11 | # キー列をindexにする new_purchase_temp = new_purchase.set_index('購入者') customer_temp = customer.set_index('顧客名') # 結合 new_purchase2 = customer_temp.join(new_purchase_temp, how='outer') # indexを数値化 new_purchase2 = new_purchase2.reset_index() # 列名を変更 new_purchase2 = new_purchase2.rename(columns={'index': '購入者'}) # データ確認 new_purchase2.head(7) |
join は index にしてから結合するので、merge と違って、購入者、顧客名の両方の列が残らない違いがあります。
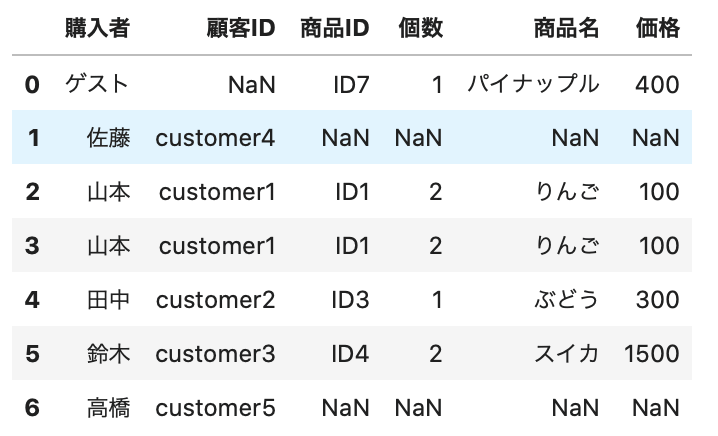
今回は以上となります。
pandas の使用方法については以下の記事にまとめています。
本記事で pandas でDataFrameの結合方法を行う学習が出来た方は再度復習してみましょう。
-
【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
また、PandasのDataFrameについての詳しい記事は、以下の記事にまとめていますので参照してください。
-
【Python】pandas.DataFrameの概要と作成方法・変換方法
続きを見る