
こんにちは。
産婦人科医で人工知能の研究をしているTommy(Twitter:@obgyntommy)です。
本記事ではPythonのライブラリの1つである pandas のDataFrame を用いたデータ参照方法に利用できる、様々なメソッドを学習していきます。
pandasの使い方については、以下の記事にまとめていますので参照してください。
-

【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
本記事の目標はPythonのデータフレームpandasを利用してDataFrameを用いたデータ参照をマスターする事です。
CSVなどのデータをDataFrameに読み込んだら、DataFrameから自由自在にデータを取得できなければ、データ解析ができません。
慣れ親しんでいるデータであれば、データを使用する事もそれほど困難ではありません。
しかし、初見の慣れ親しんでいないデータであれば、データの取得に難渋する場合があります。
本記事でデータを参照する方法を習得しつつ、自由自在にデータを取得できるようになりましょう。
PandasのDataFrameについての記事は、以下の記事にまとめていますので参照してください。
-

【Python】pandas.DataFrameの概要と作成方法・変換方法
続きを見る
ここで本記事の学習到達目標です。
本記事の学習目標
- pandasのDataFrameで簡単なデータの参照・取得方法を修得する。
- pandasのDataFrameから列や行を指定してデータを取得する方法を修得する。
- pandasのDataFrameからiloc, やlocを使用してデータを取得する方法を修得する。
- pandasのDataFrameからqueryメソッドを利用してデータを取得する方法を修得する。
- pandasのDataFrameからループ処理を用いてデータを取得する方法を修得する。
では早速、学習していきましょう。
使用するデータを取得する

seaborn に入っているデータ seaborn-data から、DataFrameで取得できるデータを使用して学習していきます。
seaborn の公式ドキュメントは以下になります。
-
seaborn: statistical data visualization — seaborn 0.13.2 documentation
続きを見る

まず下記を実行して、seabornをインストールください。
In[]
1 2 3 | pip install seaborn or pip3 install seaborn |
今回使用するデータは、Seabornで用意されている「tips」という名称のデータに「tips」という名前を付けます。
下記を実行するとデータを読み込めます。
In[]
1 | tips = sns.load_dataset("tips") |
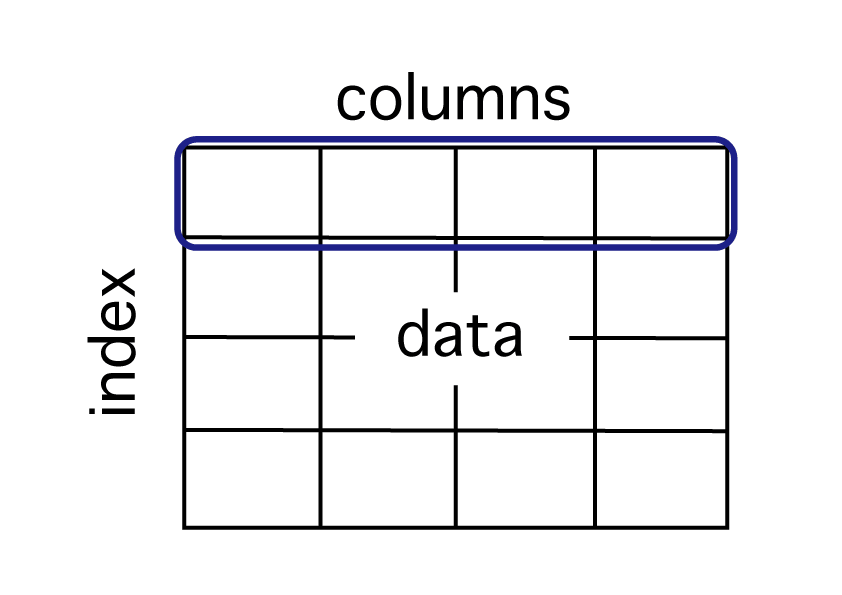
DataFrame におけるデータの参照方法には、色々な方法があります。
しかし基本的には DataFrameの構成である、下記の columns、index、dataを参照していくことになりますので、まずはこの方法をおさえましょう。
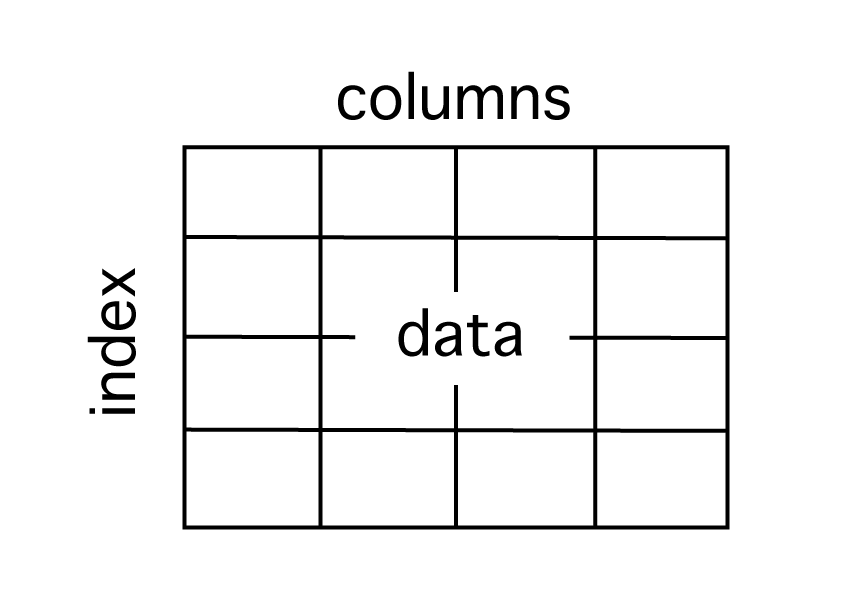
データの概要・基本的なデータの取得方法、参照方法を取得しよう

データの情報を取得する方法
まずはデータの情報を取得しましょう。
データの情報は info メソッドで簡単に取得できます。
pandas.DataFrame.info の公式ドキュメントは以下になります。
-
pandas.DataFrame.info — pandas 3.0.3 documentation
続きを見る

In[]
1 | tips.info() |
Out[]

データ数、列数を確認する方法
infoメソッドでも上図の様にデータ情報を取得する事ができますが、場合によって数値のデータを取得したい場合があります。
データ数(行数)、列数の取得は下記のコードで取得する事ができます。
In[]
1 2 | # データ数 len(tips) |
Out[]
1 | 244 |
In[]
1 2 | # 列数 len(tips.columns) |
Out[]
1 | 7 |
データの最初と最後の数行を参照する方法
データの最初と最後の数行を参照する場合は、head メソッド、tail メソッドを使います。
pandas.DataFrame.head 、pandas.DataFrame.head の公式ドキュメントは以下になります。
-
pandas.DataFrame.head — pandas 3.0.3 documentation
続きを見る

-
pandas.DataFrame.tail — pandas 3.0.3 documentation
続きを見る

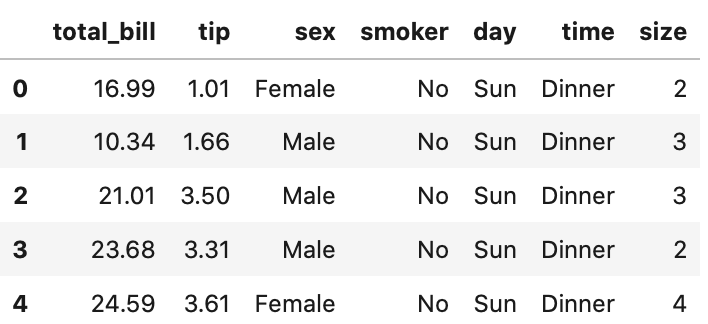
引数を何も渡さず実行すると5行取得できます。
In[]
1 2 | # 最初の5行 tips.head() |
Out[]
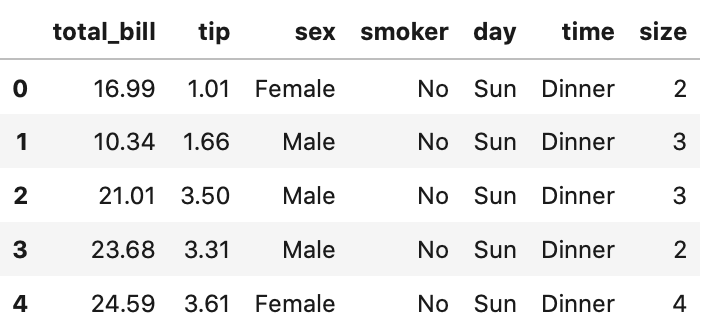
In[]
1 2 | # 最後の5行 tips.tail() |
Out[]
取得したいデータ数を引数に渡すこともできます。
In[]
1 2 | # 最初の7行 tips.head(7) |
Out[]

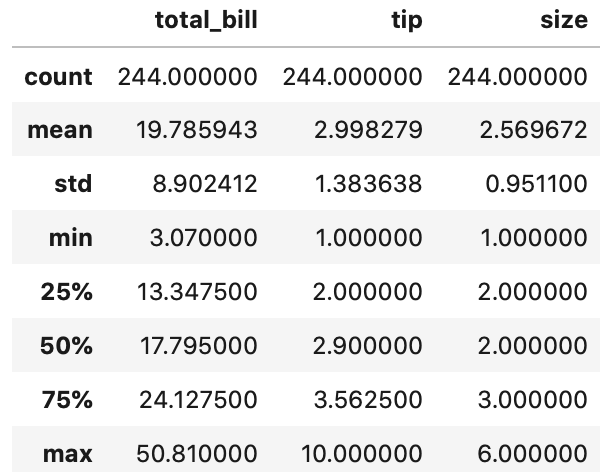
データの統計量を参照する方法
数値データの統計量を簡単に参照することができます。
describeメソッドを使います。
pandas.DataFrame.describe の公式ドキュメントは以下になります。
-
pandas.DataFrame.describe — pandas 3.0.3 documentation
続きを見る

In[]
1 | tips.describe() |
Out[]
列名(columns)、行名(index)を取得する方法
たいていは、行(index)は0,1,2…なので、大事なのは列名。
列名を指定して、データを参照するので、列名を取得できる必要があります。
下記で取得できます。
In[]
1 | tips.columns |
Out[]
1 | Index(['total_bill', 'tip', 'sex', 'smoker', 'day', 'time', 'size'], dtype='object') |
indexも見ておきましょう。
In[]
1 | tips.index |
数値の0から244の1ずつ割り当てられているということです。
Out[]
1 | RangeIndex(start=0, stop=244, step=1) |
列(columns)の型を取得する方法
列の型に応じて、数値はこの処理、カテゴリはこの処理と分けたいので、データの型も取得できるようになりましょう。
データの型、すなわち pandas の dtypes については以下のドキュメントを参照して下さい。
下記で取得できます。
In[]
1 | tips.dtypes |
Out[]

pandasから一意の値を取得する方法
各列の値では、重複のない一意の値を取得したい場合があります。
ここで「一意の値」はあまり聴き慣れない言葉かもしれませんが、「一意の値」=「重複のない値」と捉えて下さい。
例えば、カテゴリ変数の一意の値を取得して、その値を取得して、カテゴリごとに計算する場合などです。
tips のカテゴリデータである、time の一意の値を取得しましょう。
先ほど、tips.dtype で列ごとの型を取得しましたが、そのうちカテゴリ(category)は以下の4つです。
そのうち time 列の一意の値を取得しましょう。
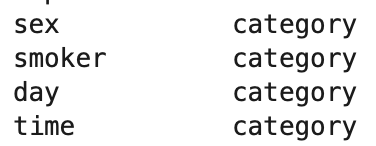
取得には、uniqueメソッドを使います。
In[]
1 | tips['time'].unique() |
Out[]
1 2 | [Dinner, Lunch] Categories (2, object): [Dinner, Lunch] |
time列には Dinnerと Lunch のデータがあることがわかります。
データの出現頻度の確認方法
一意の値がわかると、同様に、それぞれの数の出現頻度も気になるところです。
value_counts メソッドでそれぞれの出現頻度を知ることができます。
value_conunts の公式ドキュメントについては以下を参照にして下さい。
-
pandas.Series.value_counts — pandas 3.0.3 documentation
続きを見る

In[]
1 | tips['time'].value_counts() |
Out[]
1 2 3 | Dinner 176 Lunch 68 Name: time, dtype: int64 |
Lunch のデータ数の方が少ないですね。
これで、Lunch が10だと統計量を算出しても、信頼できる値にはならないでしょう。
今回は大丈夫そうです。
参照するデータを並び替える方法
並べ替える方法も見ていきましょう。
並び替えは、sort_valuesメソッドでできます。
sort_values メソッドの公式ドキュメントは以下になります。
-
pandas.DataFrame.sort_values — pandas 3.0.3 documentation
続きを見る

引数に列名とascendingで昇順(True)、降順(False)を渡します。
total_bills を昇順で並び替えてみましょう。並び替えたものは tips_sort にいれています。
In[]
1 2 | # total_billを昇順、降順はFalseにする tips_sort = tips.sort_values('total_bill', ascending=True) |
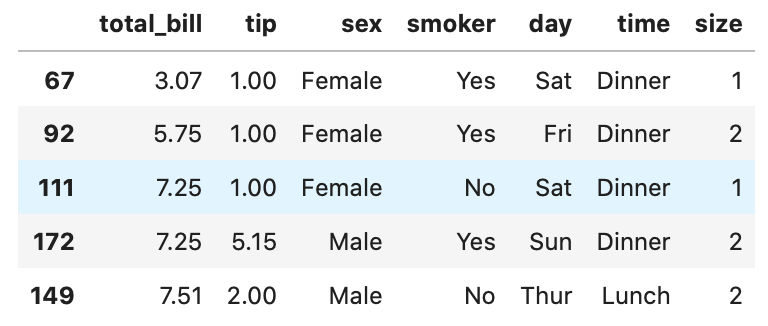
head メソッドを使用すると、total_billの列が並び替えれていることがわかります。
In[]
1 | tips_sort.head() |
Out[]
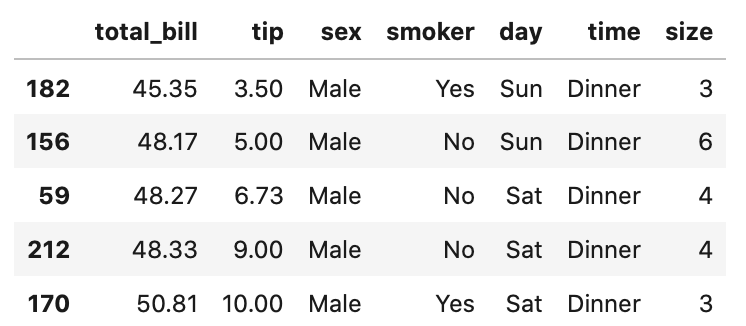
tail メソッドを使用すると、total_billの列が並び替えれていることがわかります。
In[]
1 | tips_sort.tail() |
Out[]
データを取得する方法

必要なデータをしっかり取得できるようになりましょう。
列(columns)を指定してデータを取得する方法
下図の青枠のように列単位でデータを取得してみましょう。
ここで、列単位でデータを取得する際に、1列を取得するのか、複数列を取得するのかで方法が異なってきます。
各々についてのデータ参照の方法について確認していきましょう。
1列のみを参照する方法
1列の行(column)のみを参照する方法は、tips の後に[‘列名’] を記載するだけです。
それでは、表のうちのtotal_bill 列のみを取得します。
In[]
1 | tips['total_bill'] |
Out[]
1 2 3 4 5 6 | 0 16.99 1 10.34 2 21.01 3 23.68 4 24.59 ... |
複数列を参照する方法
複数列を参照する場合、[[‘列名1’, ‘列名2’, ‘列名3’]] と列名をリストで渡します。
複数列を参照する場合、[] が一つ多くなります。
In[]
1 | tips[['total_bill', 'tip', 'size']] |
Out[]
![python pandas dataframe データ参照 複数列のデータ参照の場合に、[[‘列名1’, ‘列名2’, ‘列名3’]]と列名をリストで渡した事を示す表](https://obgynai.com/wp-content/uploads/2020/05/ref10-min.png)
表の行(index)のみを指定してデータを取得する方法
図の青枠のように表のうち行単位でデータを取得する方法を学習しましょう。
In[]
行単位でデータを取得する方法は numpy と同じく、[開始行:終了行] で取得できます。
numpyについては以下の記事で復習しましょう。
-

NumPyの入門【基礎から解説】
続きを見る
注意ポイント
- 表から行単位のデータを取得する場合には、
numpyと違い、1行でも、[開始行:終了行]の指定が必要です。 終了行で指定した行の1つ手前までの行を取得します。- 行数は0から数える事にも注意です。
では早速、表のうち1行のみのデータを取得してみましょう。
In[]
1 | tips[0:1] |
Out[]

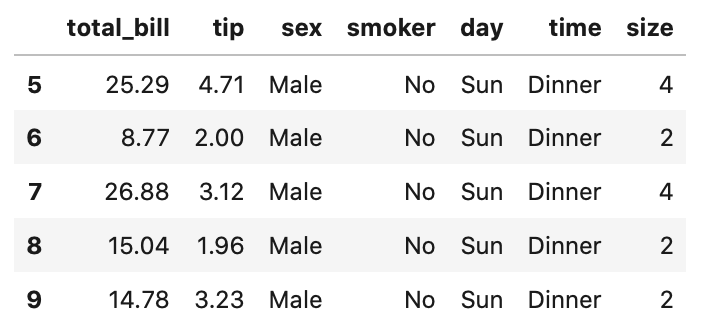
次に、表のうち5行目から9行目のデータを取得してみましょう。
In[]
1 | tips[5:10] |
Out[]
iloc, locを使って取得するデータを指定する方法
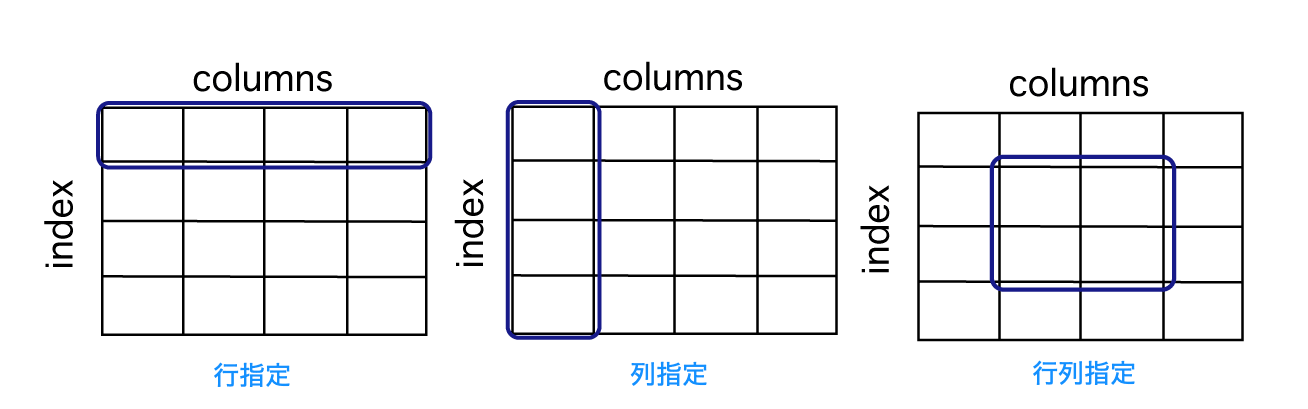
ilocとlocを使うと、自由に行と列を組み合わせてデータを取得する事が可能になります。
iloc とloc の違いは以下の図の様になります。
iloc:行列の番号で指定loc:行列のラベルで指定
iloc
iloc は integer-locationの略で「数値で場所を指定する」ということを意味します。
iloc[行、列] で指定することができ、列は省略が可能です。
行、列の指定にはコードとしては「:」を使います。
普段5行〜10行という風に使用する様な、「〜」と捉えて頂ければOKです。
例えば、下記のような使い方です。
[3] | 3行目 *列を省略 |
[:3] | 0〜2(3手前まで)行 *列を省略 |
[1:5] | 1〜4行 *列を省略 |
[:, 3] | 全行、2列目 |
[:, :2] | 全行、0-1列 |
[:, 2:] | 全行、2列以降 |
[:10, 1:4] | 0-9行、1-3列 |
[:100, :] | 0-99行、全列 |
[10:, :] | 10行以降、全列 |
上記の表のうち、行列を指定してデータを取得する方法についていくつか試してみましょう。
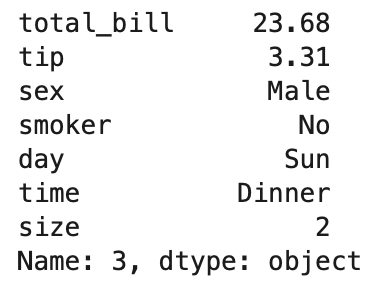
まずは3行目のデータを取得してみましょう。
In[]
1 | tips.iloc[3] |
Out[]
次に、0-9行、1-3列のデータを取得してみましょう。
In[]
1 | tips.iloc[:10, 1:4] |
Out[]

loc
locではデータを参照する際に、列、行名で指定します。
コードを記載する方法としては loc[行名, 列名] もしくは、loc[True/Falseのlist] で指定する事ができます。
True/Flase は iloc でも使用できます。
まず、取得したいデータを行名列名で指定してみましょう。
例として、行名が 0, 2, 4, 6 で、かつ列名が tip, sex, smoker を選択してみます。
*行(index) は数値なので、” で囲う必要はありません。ただし、文字列なら列名のように ” で囲って指定する必要がある事に注意です。
loc iloc のTrue/False の使い方について
loc, iloc は通常ラベルもしくは番号で指定しますが、両者の共通指定方法として True/Flase で指定する事も可能です。
例えば、下記は4つ全部同じデータを取得できます。
最後の2つは特に、ラベルでも番号指定でもなく True/False で指定しています。
loc、iloc両方で True/False が使う事が出来ているのが分かると思います。
1 2 3 4 5 | # ラベル、番号指定 tips.loc[:, ['total_bill', 'tip']]tips.iloc[:,[0, 1]] # True/False指定 tips.loc[:,[True,True,False,False,False,False,False]] tips.iloc[:,[True,True,False,False,False,False,False]] |
In[]
1 | tips.loc[[0,2,4,6], ['tip','sex','smoker']] |
Out[]
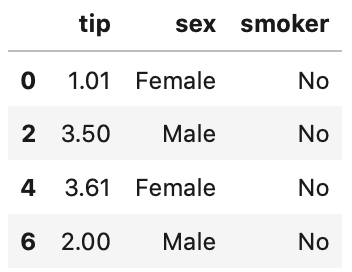
True/False による指定をみていきましょう。
偶数列をTrue 、奇数列を False となるリストを内包表記で作ってみましょう。
「内包表記の仕方を忘れてしまった」という方は、【python入門】list(リスト)の使い方の総まとめ【後編】の『内包表記』 の箇所を参照にしてください。
In[]
1 | row_list = [True if i % 2 == 0 else False for i in range(len(tips))] |
このコードの書き方を、loc で指定して行いましょう。
参照列の指定は行われず、全列のデータを参照出来る様に取得しましょう。。
In[]
1 2 | # row_listの偶数行、全列 tips.loc[row_list] |
上記のコードでは、偶数が True となるように取得する行のリストを作りました。
その他の方法として、各列の値を、「tip 列が2以上という条件」を指定して取得することも可能です。
tip 列が2以上という条件を作ってみます。
In[]
1 | row_list = tips['tip']>=2 |
Out[]
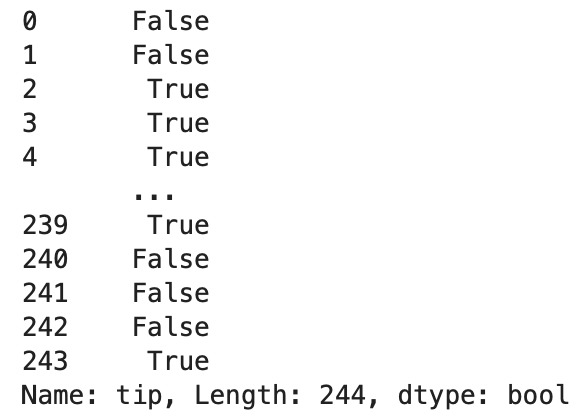
これを loc で指定することで、tip が2以上の行だけを取得することができます。
In[]
1 | tips.loc[row_list] |
わかりやすさのためにコード分けましたが、通常は、下記のように1行のコードにします。
In[]
1 | tips.loc[tips['tip']>=2] |
&(and) 、|(or) で複数条件も指定可能です。
注意ポイント
下記のコード例のような、if文の条件式で使う and 、or ではないので注意が必要です。
In[]
1 2 3 | a = 10 if a>=10 and a<20: print('10以上、20未満') |
pandas の条件式では、下記のコードのように「&」や「|」を使います。
In[]
1 | tips.loc[(tips['tip']>=2) & (tips['sex']=='Male')] |
Out[]
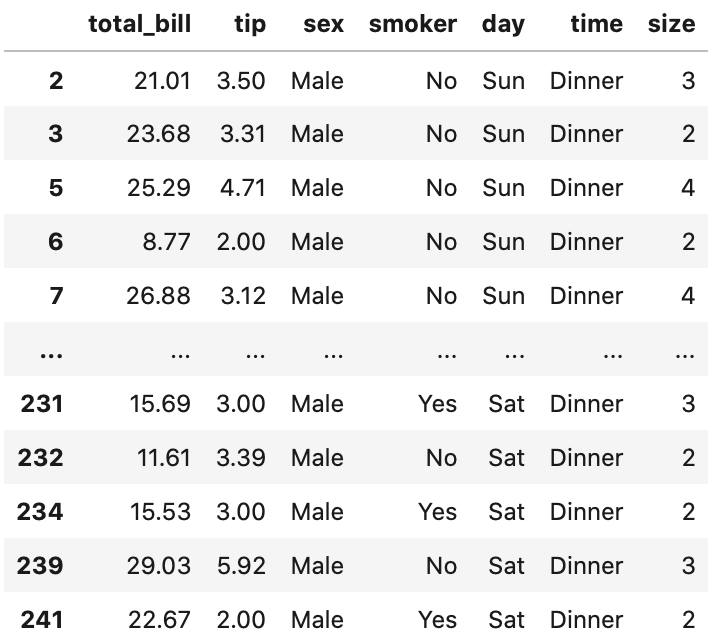
全列を対象にしてきましたが、全列を指定する場合は、loc を省略しても同じです。
In[]
1 2 | # loc使わず tips[(tips['tip']>=2) & (tips['sex']=='Male')] |
loc を使うと、列も指定できるという違いがあります。
全列を対象にする場合は、locを使わない方法をよく使います。
queryメソッドを使用してデータを取得する方法
queryメソッドでも、参照したいデータの行列の条件を指定する事でデータを取得できます。
queryメソッドの場合には、条件の指定の仕方は、文字列で表現するので、いくつか紹介します。
| tip>=2 | tipが2以上 |
| not tip>=2 | tipが2以上でないもの |
| 2<=tip<4 | tipが2以上、4未満 |
| sex==”male” | sexがmale |
| sex!=”male” | sexがmaleでないもの |
| day in [“Sun”, “Fri”] | dayがSunとFriのもの |
| day not in [“Sun”, “Fri”] | dayがSunとFri以外のもの |
query メソッドを利用して、いくつか例としてコードの記載を試してみましょう。
まずは、tipsのcolums の tip が2以上かつ、4未満のものについて見ていきましょう。
In[]
1 | tips.query('2<=tip<4') |
Out[]
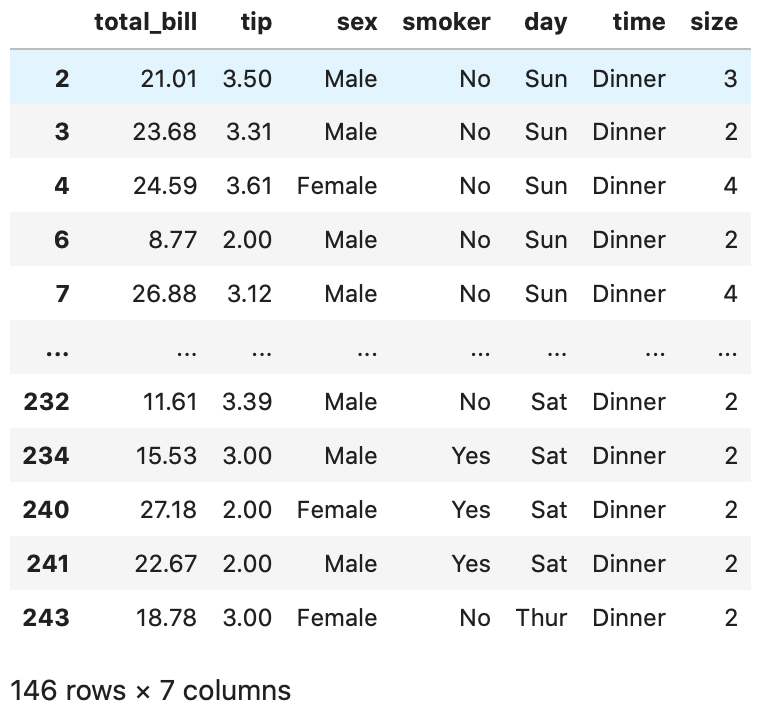
次にtipのcolums の day のうち、 Sun と Fri のものについて見ていきましょう。
In[]
1 | tips.query('day in ["Sun", "Fri"]') |
Out[]
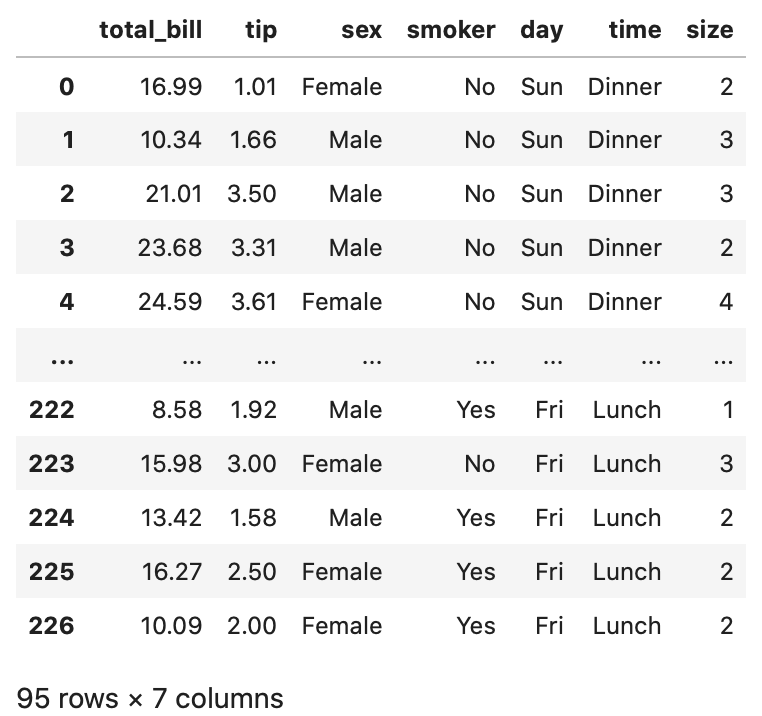
如何でしょうか。
その他にも、上記のqueryメソッドの場合に条件の指定の仕方によって、文字列を指定して表現できる表の表し方が多くありますので、色々と試してみましょう。
型を指定してデータを取得する方法
データを取得したい表によっては数値の列だけの場合や、カテゴリの列だけの場合があります。
その様な表の場合に、数値やカテゴリーの型によってデータを取得したい場合があります。
その場合は、select_dtypes が有用です。pandas.DataFrame.select_dtypes の公式ドキュメントは以下の様になります。
-
pandas.DataFrame.select_dtypes — pandas 3.0.3 documentation
続きを見る

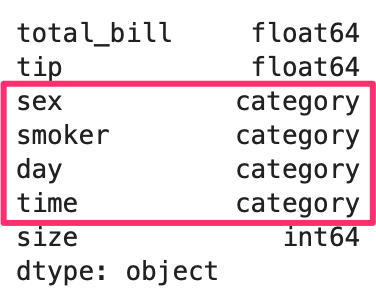
まず再度、tips のデータの型を確認してみましょう。
In[]
1 | tips.dtypes |
Out[]

select_dtypes を使い方
- 引数に、
include=型で対象の型の列を指定 - 引数に、
exclued=型で対象の型の列の列以外を指定
型について
pandasの型には下記の表のものがあります。
列番号や、ラベルではなくこれらの型うちから参照していきます。
| 型 | 説明 |
| object | テキストまたは数値と非数値の混合 |
| bool | 真偽 |
| int64 | 64ビット符号付き整数 |
| float64 | 64ビット浮動小数点 |
| datetime64 | 日時 |
| category | 有限のテキストリスト |
category列の取得
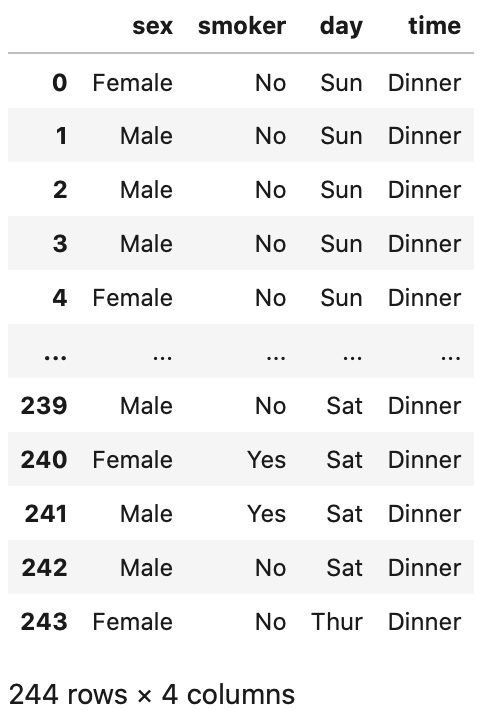
まず、category の列を指定してデータを参照してみましょう。
型の category を指定すると、category 型の列全てを参照できます。
In[]
1 | tips.select_dtypes(include='category') |
Out[]
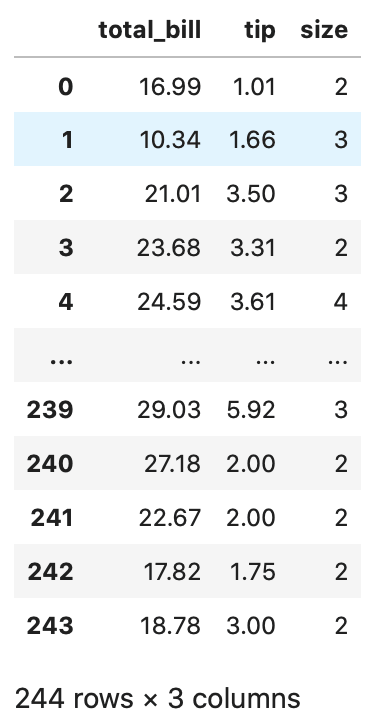
次に、数値である int64 と float64 を指定します。
In[]
1 | tips.select_dtypes(include=['int64', 'float64']) |
number を指定して、表から数値のみで抽出してデータの取得を行う事ができます。
In[]
1 | tips.select_dtypes(include='number') |
Out[]
tips のデータはカテゴリの列以外は数値なので、exclude を使っても同じ結果が得られます。
繰り返しになりますが、「exclued=型」のコードを記載する事で対象の型の列以外が選択できます。
試しに下記コードを実行してみてください
In[]
1 | tips.select_dtypes(exclude='category') |
Out[]
ループ処理でデータを取得する方法
最後に、ループ処理で順番にデータを取得する方法についてです。
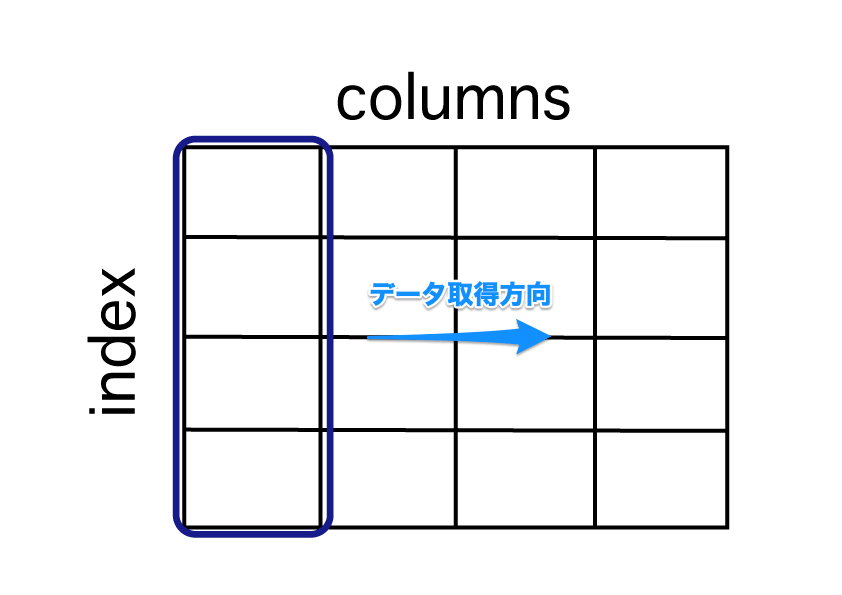
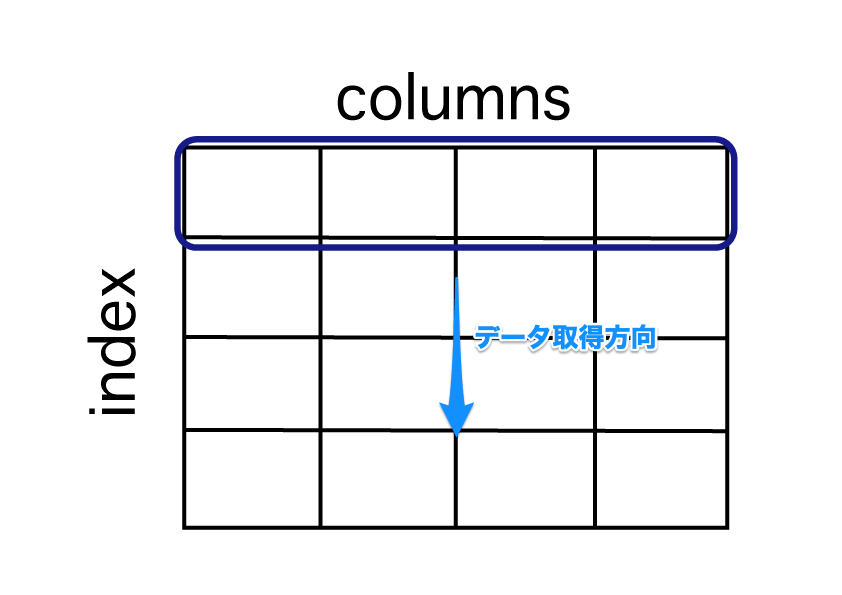
ループは列方向か、行方向でループをします。具体的には以下の図の様なイメージです。
ループ処理で列方向でデータを取得するイメージ
ループ処理で行方向でデータを取得するイメージ
それでは、各々の取得方法について具体的なメソッド iteritemsメソッド を用いて学習していきましょう。
ループ処理で列方向にデータを取得する方法
列方向へのループは iteritems メソッドを使います。イメージ図は以下です。
pandas.DataFrame.iteritems の公式ドキュメントは以下になります。
使い方は、次のようになります。
1列ずつ処理され、col_name に列名、col に1列分のデータが取得できます。
In[]
1 2 | for col_name, col in tips.iteritems(): # ループ処理 |
1列ずつ処理され、col_name に列名が取得できます。
col には、1列分のデータが取得できます。
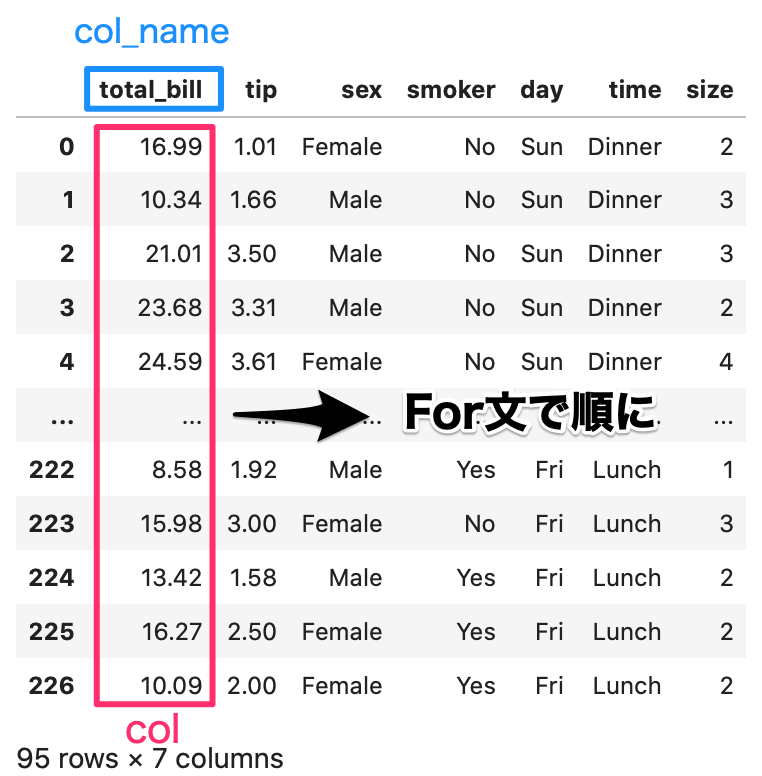
実際に使ってみましょう。
In[]
1 2 3 | for col_name, col in tips.iteritems(): print(col_name, '列: 1行目のデータ', col[0]) print(col_name, '列: 100行目のデータ', col[99]) |
Out[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | total_bill 列: 1行目のデータ 16.99 total_bill 列: 100行目のデータ 12.46 tip 列: 1行目のデータ 1.01 tip 列: 100行目のデータ 1.5 sex 列: 1行目のデータ Female sex 列: 100行目のデータ Male smoker 列: 1行目のデータ No smoker 列: 100行目のデータ No day 列: 1行目のデータ Sun day 列: 100行目のデータ Fri time 列: 1行目のデータ Dinner time 列: 100行目のデータ Dinner size 列: 1行目のデータ 2 size 列: 100行目のデータ 2 |
列でループすることはあまりなく、次の行のループの方がよく使います。
ループ処理で行方向にデータを取得する方法
行方向のループは、itterrowsメソッドを使います。イメージ図は以下です。
itterrowsメソッドの公式ドキュメントは以下になります。
-
pandas.DataFrame.iterrows — pandas 3.0.3 documentation
続きを見る

使い方は、次のようになります。
In[]
1 2 | for ind, row in tips.iterrows(): # ループ処理 |
ind に index の行名、今回だと 0,1,2,… が取得されます。
row には行のデータが入ります。

実際に使ってみましょう。
In[]
1 2 | for ind, row in tips.iterrows(): print(ind+1, '行目 tipのデータ ', row['tip']) |
Out[]
1 2 3 4 5 6 7 | 1 行目 tipのデータ 1.01 2 行目 tipのデータ 1.66 3 行目 tipのデータ 3.5 4 行目 tipのデータ 3.31 5 行目 tipのデータ 3.61 6 行目 tipのデータ 4.71 .... |
今回は以上となります。
pandas の使用方法については以下の記事にまとめています。一通り本記事でpandasで Excelを使用する方法を学習できた方は再度復習してみましょう。
-
【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
また、PandasのDataFrameについての詳しい記事は、以下の記事にまとめていますので参照してください。
-
【Python】pandas.DataFrameの概要と作成方法・変換方法
続きを見る