
こんにちは。
産婦人科医で人工知能の研究をしているTommy(Twitter:@obgyntommy)です。
本記事ではPythonのライブラリの1つである pandas で欠損値(NaN)を確認する方法、除外(削除)する方法、置換(穴埋め)する方法について学習していきます。
pandasの使い方については、以下の記事にまとめていますので参照してください。
-

【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
本記事の目標はpandasのNaN(欠損値)の扱い方をマスターする事です。
NaN とは Not a Number の略の事です。
現場でデータを扱っていると、不要なデータや、飛び値、欠損値(NaN)などがあるのがほとんどです。
実務では "綺麗な" データを扱わないことも多いです。
本記事でデータのNaN(欠損値)を対処出来る方法を習得しつつ、自由自在にデータを扱えるようになりましょう。
Pandasの欠損値(NaN)についての公式ドキュメントは、以下になりますので参照してください。
-
Working with missing data — pandas 3.0.5 documentation
続きを見る

ここで本記事の学習到達目標です。
本記事の学習目標
- 欠損値(NaN)についての理解
- 欠損値(NaN)を判定する方法
- 特定の行・列ごとにNaN(欠損値)の数を確認する方法
- NaN(欠損値)を削除する方法
- NaN(欠損値)を置換する方法
では早速、学習していきましょう。
使用するデータを取得する方法

seaborn に入っているデータ seaborn-data から、DataFrameで取得できるデータを使用して学習していきます。
seaborn の公式ドキュメントは以下になります。
-
seaborn: statistical data visualization — seaborn 0.13.2 documentation
続きを見る

まず下記を実行して、seabornをインストールください。
In[]
1 2 3 | pip install seaborn or pip3 install seaborn |
今回使用するデータは、Seabornで用意されている「titanic」という名称のデータに「titanic」という名前を付けます。
下記を実行するとデータを読み込めます。
In[]
1 | titanic = sns.load_dataset("titanic") |
NaN(欠損値)とは

titanic に含まれる。NaNのデータをみてみましょう。
まず、下記を実行してみましょう。

In[]
1 | titanic[titanic['age'].isnull()].head() |
Out[]

titanic に含まれているNaNのデータを確認
青枠に「NaN」と 記載されているのが分かりますよね。これがNan=欠損値です。
csvやエクセルデータ で空欄の場合に、この箇所が、欠損値としてNaNとなります。
NaNは「データがありませんよ」ということを意味しています。
NaN(欠損値)を判定する方法

NaNを含む行や列を抽出したい場合は、要素が欠損値かどうかを判定するisnull()メソッドを使います。
isnull()メソッドの公式ドキュメントは以下になります。
-
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.isnull.html
続きを見る

In[]
1 | titanic.isnull() |
Out[]
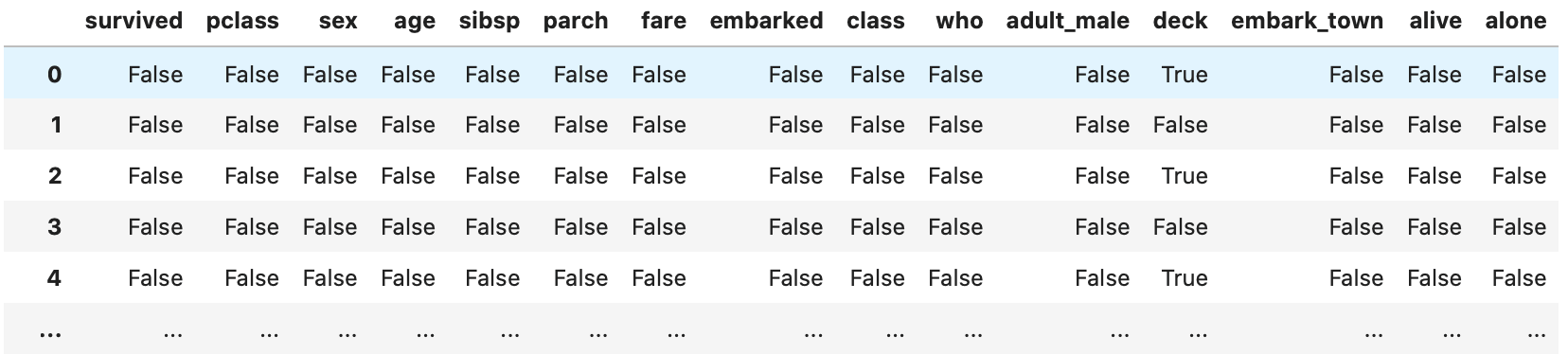
isnull()メソッドを利用して、NaNを含む行や列を抽出し、要素が欠損値かどうかを判定した表
上記の表では、True となっているところが、NaN になります。
実務で処理をする際には、この True の箇所を数えたり、削除したり、別のデータに置き換えたりします。
特定の列ごとにNaN数を確認する方法
NaNの数を確認していきましょう。
その数によって、実務では下記の様に色々判断することがあるためです。
- NaNが少ない:データ削除するか判断
- NaNが多い:データを使わないか判断
- NaNがそこそこ:データを埋めるか判断
あとは、データの特性も考慮して、どう処理するか判断していきます。
自由なメモ
- 「NaNが少ない:データを削除するか判断」
とありますが、
「ある列にNaNが少しある程度なら、そのNaNがある行ごと削除しても、データの質にはそこまで影響しないだろう」
この様な考えで、「データを削除=行データを削除する」といった認識でOKです。
NaNの数の数え方(欠損値の数のカウント方法)
NaNの数を数えるためには、sum()メソッドを使います。
sum() メソッドの公式ドキュメントは以下になります。
-
pandas.DataFrame.sum — pandas 3.0.5 documentation
続きを見る

isnull() メソッドで判定した NaN と NaN でないものを、True を 1 、False を 0 として数えてくれます。
引数に何も渡さない場合には axis=0 となり列ごとの足し算、axis=1 を渡すと行ごとに足し算がされます。
In[]
1 | titanic.isnull().sum() |
Out[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | survived 0 pclass 0 sex 0 age 177 sibsp 0 parch 0 fare 0 embarked 2 class 0 who 0 adult_male 0 deck 688 embark_town 2 alive 0 alone 0 dtype: int64 |
NaNの占める割合の考え方(欠損値の割合のカウント方法)
NaNの数を数えるためには、sum()メソッドだけでは、NaNの占める割合がわかりません。
ですので、len(titanic) でデータ数を取得し、割ることで、その割合を確認しましょう。
In[]
1 | titanic.isnull().sum() / len(titanic) * 100 |
Out[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | survived 0.000000 pclass 0.000000 sex 0.000000 age 19.865320 sibsp 0.000000 parch 0.000000 fare 0.000000 embarked 0.224467 class 0.000000 who 0.000000 adult_male 0.000000 deck 77.216611 embark_town 0.224467 alive 0.000000 alone 0.000000 dtype: float64 |
age は19%と割合として少なく、deck は77%と多いことがわかります。
embarked は少ないので、データを消しても予測精度に影響がないかもしれません。
特定の行ごとのNaN(欠損値)数の確認方法

特定の行ごとの NaN の数の確認方法も見ていきましょう。
NaN(欠損値)数の確認方法
NaNの数を数えるためには、sum()メソッドを使うところは同じですが、axis=1 、すなわち行ごとの足し算を行う様に指定します。
axis=0で縦方向に足し算axis=1で横方向に足し算- デフォルトは
axis=0です
実際に試してみましょう。
In[]
1 | titanic.isnull().sum(axis=1) |
Out[]
1 2 3 4 5 6 | z0 1 1 0 2 1 3 0 4 1 .. |
NaNの占める割合の確認方法(欠損値の割合のカウント方法)
今回は列数で割りたいので、len(titanic.columns) で列数を取得します。
In[]
1 | titanic.isnull().sum(axis=1)/len(titanic.columns)*100 |
Out[]
1 2 3 4 5 6 | 0 6.666667 1 0.000000 2 6.666667 3 0.000000 4 6.666667 ... |
NaN(欠損値)の削除方法

Nan(欠損値)を削除する際には、dropna()メソッドを使って、NaNを削除します。
dropna()メソッドの公式アカウントは以下になります。
-
pandas.DataFrame.dropna — pandas 3.0.5 documentation
続きを見る

NaNの削除方法には、対象の行、対象の列を削除する方法があるのでみていきましょう。
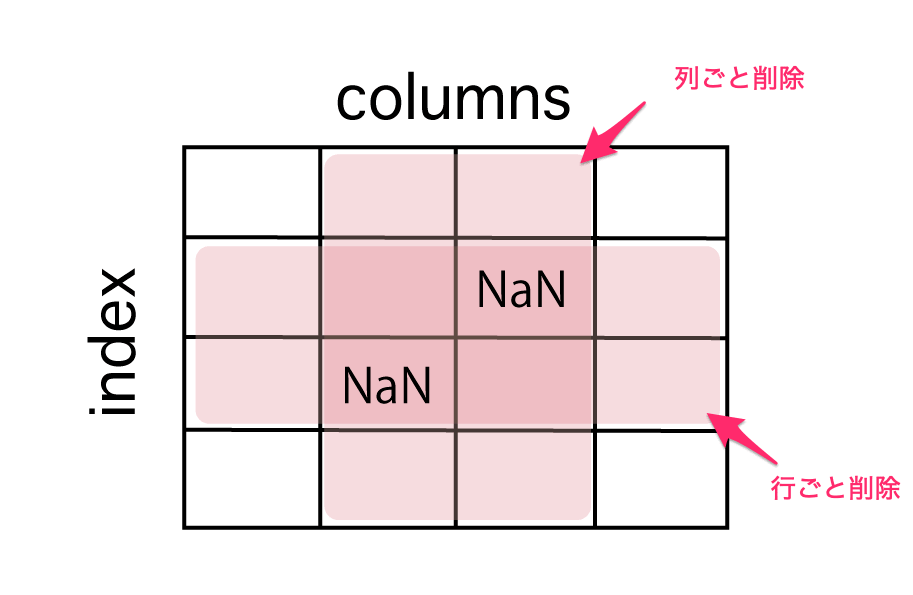
dropnaメソッドを使って、NaNの削除のうち、対象の行、列を削除する方法
NaN(欠損値)がある列の削除の方法
NaNがある列の削除はパラメータ axis=1 として、引数に渡します。
削除した後のDataFrameは、新しく titanic_dropna に格納して、削除されたか確認していきましょう。
In[]
1 | titanic_dropna = titanic.dropna(axis=1) |
列が削除されたか、columnsを確認してみましょう。
In[]
1 | titanic_dropna.columns |
Out[]
1 2 3 | Index(['survived', 'pclass', 'sex', 'sibsp', 'parch', 'fare', 'class', 'who', 'adult_male', 'alive', 'alone'], dtype='object') |
age、deck 列などが削除されていますね。
「列ごとのNaN数確認」で使った方法で、NaNの数も見てみましょう。
In[]
1 | titanic_dropna.isnull().sum() |
Out[]
1 2 3 4 5 6 7 8 9 10 11 12 | survived 0 pclass 0 sex 0 sibsp 0 parch 0 fare 0 class 0 who 0 adult_male 0 alive 0 alone 0 dtype: int64 |
出力でNaN(欠損値)がなくなっていることが分かります。
NaN(欠損値)がある行を削除する方法
次にNaNがある行を削除していきましょう。
axis=0 とすれば良いですが、引数に何も渡さなければ、axis=0 が初期となっています。
引数を渡さず、dropna() メソッドを実行してみましょう。
In[]
1 | titanic_dropna = titanic.dropna() |
NaNのある行が削除されたか、データ数をlen(titanic_dropna)で確認していきましょう。
In[]
1 | len(titanic_dropna) |
Out[]
1 | 182 |
891行あったのが、182行になっています。
「列ごとのNaN数確認」で使った方法で、NaNの数も確認してみましょう。
In[]
1 | titanic_dropna.isnull().sum() |
Out[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | survived 0 pclass 0 sex 0 age 0 sibsp 0 parch 0 fare 0 embarked 0 class 0 who 0 adult_male 0 deck 0 embark_town 0 alive 0 alone 0 dtype: int64 |
列の削除と違って、行の削除をしたので、age、deck などの列は残ったまま、NaNがゼロになっています。
NaN(欠損値)の置換の方法

次は、NaNを何かしらの値に置換していく方法を学習していきましょう。
NaNの置換の方法には、fillna()メソッドやloc()メソッドを使っていきます。
filla()メソッドやloc()メソッドの公式ドキュメントは以下になります。
-
pandas.DataFrame.fillna — pandas 3.0.5 documentation
続きを見る

-
pandas.DataFrame.loc — pandas 3.0.5 documentation
続きを見る

NaN をどんな値で置き換えるかは、データの質からエンジニアが考えます。
例えば、この titanic のデータでは age に欠損値がありますが、シンプルに全データの中央値で置き換える必要はありません。
例えば、pclass (チケットクラス)列があり、高いチケットでは年齢が高くて、安いチケットでは年齢が低いかもしれません。
その場合、各チケットクラスの中央値に置き換えるとよりデータとしては有用になります。
中央値やPythonでの実装方法については、基本統計量の基本からPythonの実装方法までで解説していますので、参考にしてください。
NaN(欠損値)の数値列を置換する方法
下の画像は titanic のデータのNaNの数をカウントしたものです。
「列ごとのNaN数確認」で確認した、赤線箇所の結果によると,titanic のデータにはageの列には177つのNaNがあり、age(年齢)なので数値データになります。
赤線で引いてあるのは、age 列に177つNaNがありますよという結果です。
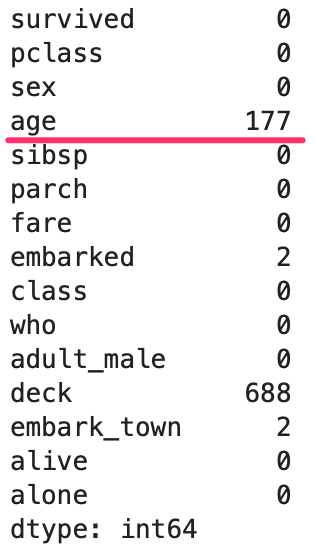
titanic のデータの表。age にNaN が177個あります。
ここで、fillna()メソッドを使って、NaN を 0 に置き換えます。filla() の引数に置き換えたい値を渡します。
なお、pandas.DataFrame.fillna の公式ドキュメントは以下になります。
-
pandas.DataFrame.fillna — pandas 3.0.5 documentation
続きを見る
In[]
1 | titanic['age'] = titanic['age'].fillna(0) |
ここで、NaNの数を確認してみましょう。
In[]
1 | titanic.isnull().sum() |
Out[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | survived 0 pclass 0 sex 0 age 0 sibsp 0 parch 0 fare 0 embarked 2 class 0 who 0 adult_male 0 deck 688 embark_town 2 alive 0 alone 0 dtype: int64 |
数値列の age にNaNがなくなり、0 に置き換わっていることがわかります。
なぜ入力したコードに、titanic[‘age’] = titanic[‘age’].fillna(0) と「=」を使っているのでしょうか?
pandasで扱う他のメソッドでも同じことが言えますが、fillna()メソッドを実行しただけでは、元のDataFrameの値は変わりません。
元のDataFrameの値を変える為には、NaNを処理した列を = を使って置き換えるか、新規のDataFrameを作る必要があります。
若しくは、inplace=True とすることで、置き換え処理をする必要があります。
以下の様なイメージですので、DataFrameが fillna() メソッドでどの様に変わるのかを図でイメージしてみましょう。
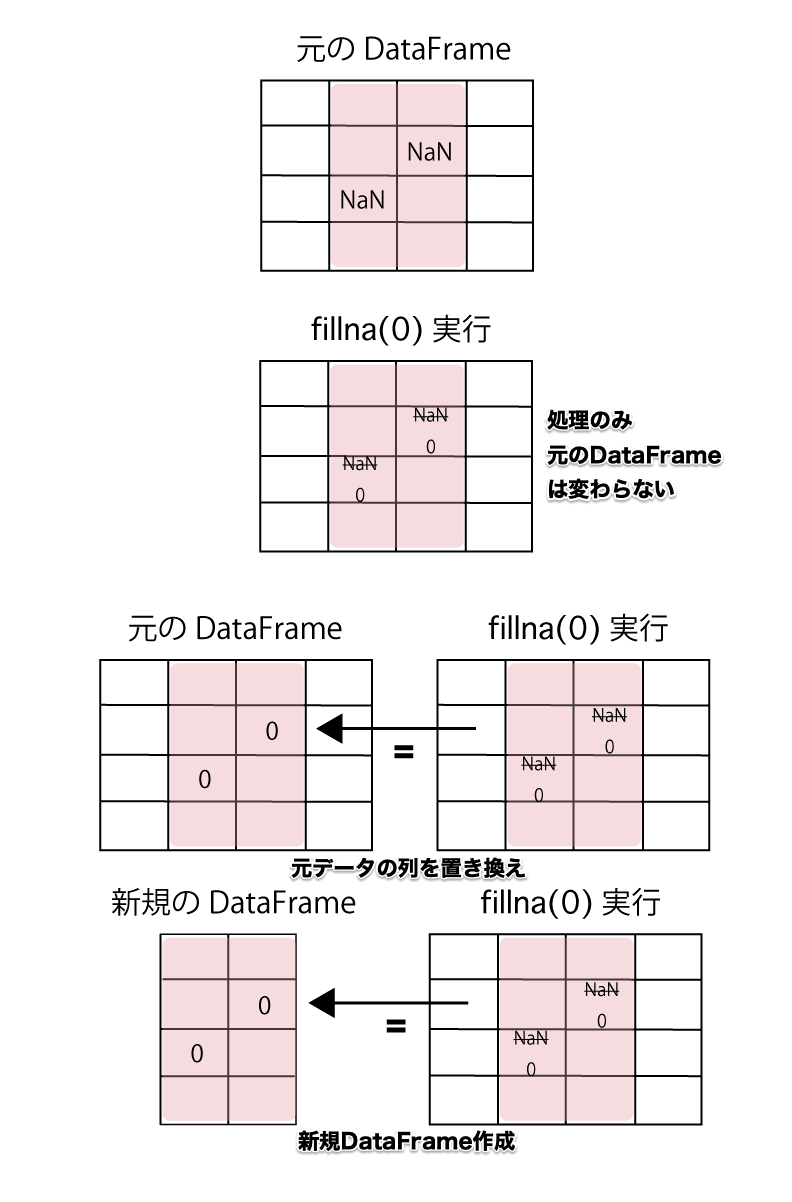
元のDataFrameの値を変える為には、NaNを処理した列を = を使って置き換えるか、新規のDataFrameを作る必要がある。
もしくは、inplace=True とすることで、NaN(欠損値)の置き換え処理もしてくれます。
In[]
1 | titanic['age'].fillna(0, inplace=True) |
実際には、0 で置き換えるのは適切ではありません。
詳しくは、後で「計算値を埋める」で説明していきます。
簡単に説明すると、age (年齢)を0歳で一律で置き換えると、titanic 号に異常に0歳児が多いことになりますし、age は生き残るかどうかを予測する上で重要な特徴量と捉えるのが適切ですので、適当に0とするのはよくないでしょう。
NaN(欠損値)のカテゴリ列を置換する方法
次は、カテゴリ列(category型の列)の置換(置き換え)をしてみましょう。
カテゴリ列は、sex 列の「Male」「Female」のようにグループ分けできる列です。
イメージとしては下記の様な図になります。
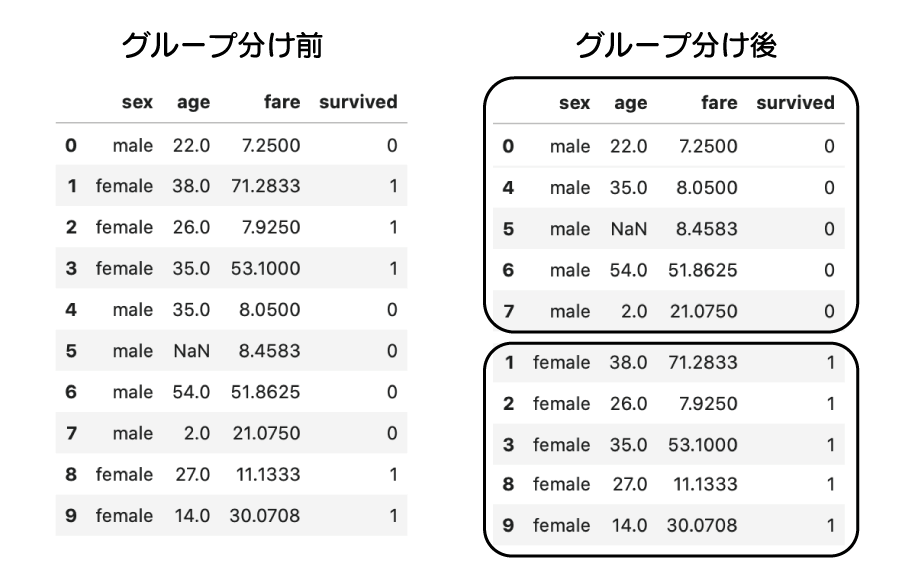
titanicをsex列の「Male」「Female」のようにグループ分けする前と後のイメージ図
「列ごとのNaN数の確認」で各列のNaNの数を確認しました。
下の表の赤線の deck 列にはNaNがあるのが確認出来ますよね。
また、deck (デッキ)には A, B, C, … とグループ分けできるカテゴリ列になっています。
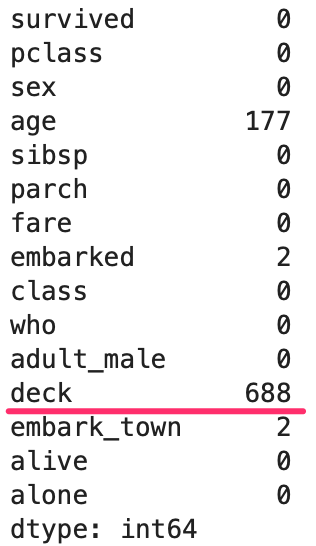
titanic の列ごとのNaN数を確認すると、deck には688個のNaNがある事が確認出来る。
この表を、カテゴリ列に沿って A, B, C, … とグループ分けしてみましょう。
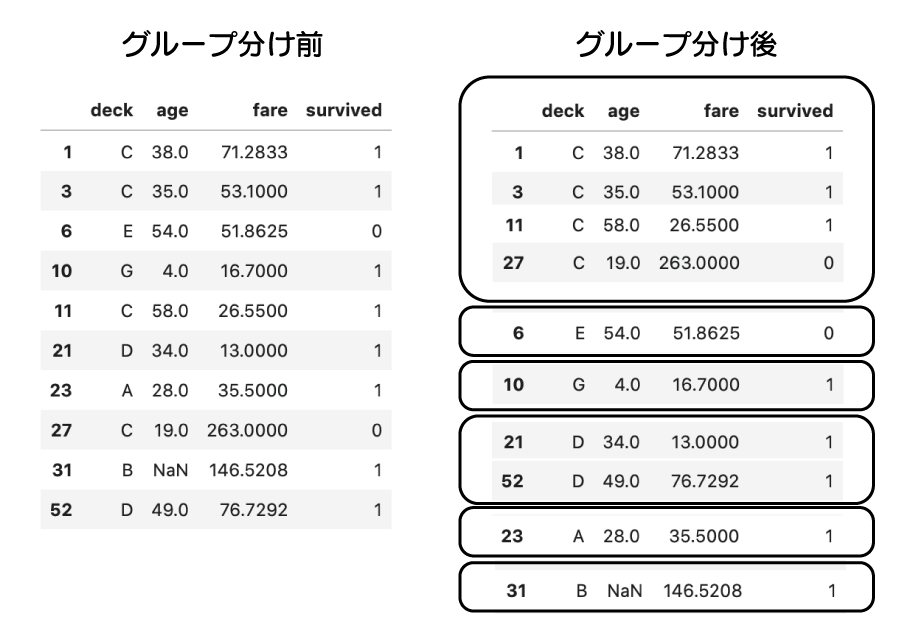
titanic の列ごとのNaN数を確認すると、deck には688個のNaNがある事が確認出来る。それを、カテゴリに沿って A, B, C, … とグループ分けしたイメージ図。
試しに、NaNを「UnKnown」で置き換えてみましょう。
In[]
1 | titanic['deck'].fillna('UnKnown' ,inplace=True) |
Out[]
1 | ValueError: fill value must be in categories |
エラーが出ましたね。
「UnKnown」は deck 列に一つもないので、置き換えできません。
deck 列にはどんなデータがあるのでしょうか?
unique()メソッドで確認してみましょう。
In[]
1 | titanic['deck'].unique() |
Out[]
1 | [NaN, C, E, G, D, A, B, F] |
deck 列で使われているデータが確認できました。
「C」で置き換えてみましょう。
In[]
1 | titanic['deck'].fillna('C' ,inplace=True) |
置換(置き換え)をすることができましたね。それでは、NaNの数を確認してみましょう。
In[]
1 | titanic.isnull().sum() |
Out[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | survived 0 pclass 0 sex 0 age 0 sibsp 0 parch 0 fare 0 embarked 2 class 0 who 0 adult_male 0 deck 0 embark_town 2 alive 0 alone 0 dtype: int64 |
deck の列にNaNがなくなったのが分かりますね。
どうしても、UnKnown のように無いデータに置き換えたい場合は、cat.add_categoriesを使うことで、置き換えができます。
pandas.Series.cat.add_categories の公式ドキュメントは以下になりますので、参考にして下さい。
-
pandas.Series.cat.add_categories — pandas 3.0.5 documentation
続きを見る

In[]
1 2 3 4 5 6 | # データ読み直し titanic = sns.load_dataset('titanic') # UnKnownを追加できるようにする titanic['deck'] = titanic['deck'].cat.add_categories('UnKnown') # NaNをUnKnownに置き換える titanic['deck'].fillna('UnKnown' ,inplace=True) |
ココに注意
NaNになっているのがデータ上明確に理由がある場合の注意点です。
既存のデータで置き換えるのが不適切な場合には、「UnKnown」などの既存のデータにない文字列に置き換える必要があります。
データサイエンティストの視点
「列ごとのNaN数の確認」で確認した titanic のデータに deck 列のNaNがありましたよね。
deck (デッキ)にはA,B,C,と文字列が入っており、これはカテゴリ列になります。
ここでNaNの置換をする為に、上記の解説を行った訳です。
しかし、この辺りは「必ずNaNの置換を行う必要がある」というよりかは、データサイエンティストがデータを確認した際に、
データの特性からNaNの置換をするべきか、各自判断するところです。
詳しく解説していきますね。
特徴量(列)の deck というものがあって、そのデータはA, B, C, D, E, F, G の値になっています。
AデッキやGデッキという船の場所があるということです。
表で確認出来る様に、deck はNaNが多い特徴量でもあります。
データサイエンティストはこのNaNを埋める際に、何をもって置換するのが良いかということを考えます。
例えば、どのデッキにいたかわからない人(NaN値の人)以外で、どのデッキにいたか分かっている人では、下記のようになっています。
- C 59
- B 47
- D 33
- E 32
- A 15
- F 13
- G 4
では、どのデッキにいたかわからないNaNの人は、どこにいた確率が高いのでしょうか?
こんな事を考えたときに、Gデッキが一番確立が高い!という人はいないですよね。
少なくとも、現状出力した表の中で分かっている事で、Cデッキにいた人が多いのであれば、Cで置き換えておけば良いという考えです。
※ 勿論、データサイエンティストの中には異論のある方もいらっしゃるかもしれません。
そのほかにも、例えば、女性はこのデッキにいる確率が高かったとか、
チケットクラスごとに分けて、このチケットのクラスの人はこのデッキにいる確率が高いなど、
データサイエンティストは各々のデータを見て置換するべき値を判断していきます。
NaN(欠損値)を複数列まとめて置換する方法
「age」と「deck」列をまとめて置換したい場合は、dict 型で {‘対象列’: 置き換える値} と指定することで複数列を置換することができます。
一旦、データを読み直してみましょう。
In[]
1 2 | # データ読み直し titanic = sns.load_dataset('titanic') |
置換したい列と値を dict 型、すなわち {‘対象列’: 置き換える値} で作ります。
In[]
1 | values = {'age': 0, 'deck': 'C'} |
次に、fillna()メソッドで置き換えます。
In[]
1 | titanic.fillna(values, inplace=True) |
NaNの数を確認して、きちんと置換することが出来たか確認してみてください。
NaN(欠損値)に計算値を埋める方法
先ほどは、age 列を適当に 0 で置き換えました。
しかしその結果、タイタニック号に乗っている乗客の0歳児がとんでもなく多いことになってしまいますね。
では、age が空欄になっている乗客は何歳にする(置換する)のが適切なのでしょうか。
こういう所が、データを処理するエンジニアが色々考えるところでもあり、腕の見せ所です。
平均、中央、最大、最小について
まずは、平均値で置換しましょう。
平均値はmean() メソッドで計算することができます。
pandas.DataFrame.mean の公式ドキュメントは以下になりますので、参照にして下さい。
-
pandas.DataFrame.mean — pandas 3.0.5 documentation
続きを見る

In[]
1 2 3 | # データ読み直し titanic = sns.load_dataset('titanic') titanic['age'].mean() |
Out[]
1 | 29.69911764705882 |
あとは、0 の代わりにこの値を fillna() で置き換えればOKです。
ただ、出力結果の年齢が 29.699… でも良いのですが、区切りよく 30 で置き換えましょう。
In[]
1 | titanic['age'].fillna(30, inplace=True) |
これで少しは良いデータになったと思いますが、一律30歳で置き換えてしまうというのはおかしな話ですよね。
そこで、pclass ごとの年齢をみてみましょう。下記をそのまま実行してみてください。
In[]
1 2 3 4 | import seaborn as sns sns.set() titanic = sns.load_dataset('titanic') sns.boxplot(data=titanic, x='pclass', y='age') |
Out[]

titanicでpclass ごとの年齢を見た表
pclass (チケットクラス)ごとに年齢差が一目瞭然で分かります。
その為、pclass などの列データを使って置き換えた方が、良いデータになりそうです。
ここで、pclass ごとの age の平均値をみてみましょう。
groupby()メソッドを使うことで、pclassのグループ分けできます。pandas.DataFrame.groupby の公式ドキュメントは以下になります。
-
pandas.DataFrame.groupby — pandas 3.0.5 documentation
続きを見る

さらにmean()メソッドを使うことで、pclassごとの平均値を確認することができます。
groupby() メソッドにグループ化したい列名を入れるとその列をグループ分けしてくれます。
pclassなので、1, 2, 3 でグループ分けします。
In[]
1 | titanic.groupby('pclass').mean() |
Out[]
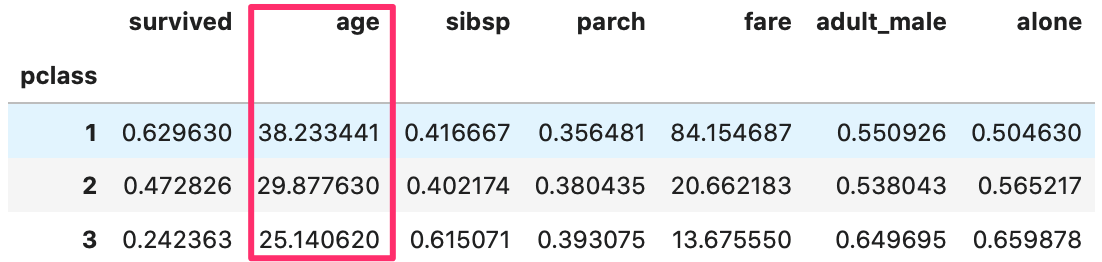
titanicをgroupbyメソッドにグループ化したい列名を入れて、各列をグループ分けした表。 pclassでは、1、2、3でグループ分けしている。
下記の様に、[‘age’]をつけて、age だけの平均値を表示してもOKです。
In[]
1 | titanic.groupby('pclass')['age'].mean() |
上記で出力した表からは、pclasss の 1 は 38、2 は 30、3 は 25 に置換すると、ほぼ適切な値を反映しそうな事が分かります。
置き換えるには、loc() メソッドを使い、対象のデータ参照して置換します。
pandas.DataFrame.loc については以下の公式メソッドを参照にして下さい。
-
pandas.DataFrame.loc — pandas 3.0.5 documentation
続きを見る
例えば上記の表の様に、 pclass が 1 の条件で、38に置換したい場合について考えましょう。
すなわち、まずは「pclassが 1 、 age が NaN となっている行で、ageの列」を参照したいですね。その上で、NaN を38に置換しましょう。
「pclass が1で age が NaN となっていないものは age が平均38なので、pclass が1で age が NaN のものを38に置き換えしたい」という事です。
以下のイメージとして捉えてください。

pclassが1 と age がNaNとなっている行は下記コードで取得できます。
In[]
1 2 3 4 | # データ読み直し titanic = sns.load_dataset('titanic') # pclassが1 と ageがNaNとなっている行 age_nan_and_pclass1 = (titanic['age'].isnull()) & (titanic['pclass']==1) |
取得した、age_nan_and_pclass1 を使って、loc(‘行’, ‘列’) の行に age_nan_and_pclass1 、列に’ age ’を指定して、データを参照します。
In[]
1 | titanic.loc[age_nan_and_pclass1, 'age'] |
Out[]
1 2 3 4 5 6 | 31 NaN 55 NaN 64 NaN 166 NaN 168 NaN .... |
これで、「pclassが1 と ageがNaNとなっている行で、ageの列」が参照できました。
全部NaNになっているのが確認できますね。
あとは、このデータを38で置換しましょう。
In[]
1 | titanic.loc[age_null_and_pclass1, 'age'] = 38 |
わかりやすく、段階を分けてコードを記載しましたが、まとめて記載すると次のようになります。
In[]
1 2 3 4 5 6 7 | titanic = sns.load_dataset('titanic') # pclass 1 titanic.loc[(titanic['age'].isnull()) & (titanic['pclass']==1), 'age'] = 38 # pclass 2 titanic.loc[(titanic['age'].isnull()) & (titanic['pclass']==2), 'age'] = 30 # pclass 3 titanic.loc[(titanic['age'].isnull()) & (titanic['pclass']==3), 'age'] = 25 |
ここでは、参考程度に載せておきますが、1行で平均値を割り当てることも可能です。
In[]
1 | titanic['age'] = titanic.groupby(['pclass'])['age'].apply(lambda x: x.fillna(int(x.mean()))) |
あとは、中央値、最大値、最小値値を求めましょう。
各々は計算するメソッドによる違いですので、それぞれ試してみてください。
結果は以下になります。
| mean | 平均値 |
| median | 中央値 |
| max | 最大値 |
| min | 最小値 |
今まで使っていた、mean() を各メソッドに変更するだけになります。
参考までに中央値、最大値、最小値を導き出す実行コードは下記になります。
In[]
1 2 3 4 5 6 | # 中央値 titanic['age'].median() # 最大値 titanic['age'].max() # 最小値 titanic['age'].min() |
最頻値について
次はカテゴリ列である deck のNaNについて置換をしていきましょう。
deck は何に置換すれば良いでしょうか?
考えられる方法としては、一番よく出てくる値(最頻値)に置き換えることです。
最頻値はmode()メソッドで取得できます。
pandas.DataFrame.mode の公式ドキュメントは以下になります。
-
pandas.DataFrame.mode — pandas 3.0.5 documentation
続きを見る

In[]
1 2 3 4 | # データ読み直し titanic = sns.load_dataset('titanic') # 最頻値 titanic['deck'].mode() |
Out[]
1 2 3 | 0 C Name: deck, dtype: category Categories (7, object): [A, B, C, D, E, F, G] |
1行目に出ている、「C」が最頻値となります。
また、value_counts メソッドで各値の出現数を確認する事も出来ますので、実際に実行してみましょう。
In[]
1 | titanic['deck'].value_counts() |
Out[]
1 2 3 4 5 6 7 8 | C 59 B 47 D 33 E 32 A 15 F 13 G 4 Name: deck, dtype: int64 |
C が最頻値であることがわかったので、fillna にて欠損値を置き換えます。
In[]
1 | titanic['deck'].fillna('C', inplace=True) |
前後のデータを利用する方法
fillna() メソッドにパラメータメソッドを使うことで、前後のデータを割り当てることができます。
method=’ffill’ で前のデータ、method=’bfill’ で次のデータを使って、置き換える事が出来ます。
まず、age と deck のデータを10個確認してみましょう。
In[]
1 2 | titanic = sns.load_dataset('titanic') titanic[['age', 'deck']].head(10) |
Out[]
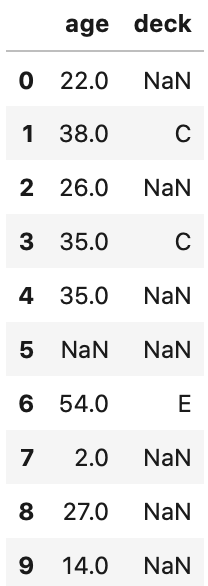
titanicのデータでageとdeckのデータを10個表示させた表。
method=’ffill’ を使って置き換えてみます。
In[]
1 2 3 4 | # ffillで置き換え titanic['age'].fillna(method='ffill', inplace=True) titanic['deck'].fillna(method='ffill', inplace=True) titanic[['age', 'deck']].head(10) |
Out[]

titanicのデータでageとdeckのデータを10個表示させた後、method=’ffill’を使って置換した表。
NaNの値がある前の行の赤枠のデータを使って置き換えられていますね。
次に、method=’bfill’ を使って置き換えてみます。
In[]
1 2 3 4 5 6 | # データ読み直し titanic = sns.load_dataset('titanic') # bfillで置き換え titanic['age'].fillna(method='bfill', inplace=True) titanic['deck'].fillna(method='bfill', inplace=True) titanic[['age', 'deck']].head(10) |
Out[]

titanicのデータでageとdeckのデータを10個表示させた後、method=’bfill’を使って置換した表。
上記の表を確認すると、NaNの値がある次の行の赤枠のデータを使って置換されているのが分かりますね。
このtitanicのデータでは、適切な置換方法ではありませんが、データの順番に意味がある時系列データでは使えるメソッドなので、修得しておきましょう。
今回は以上となります。
pandas の使用方法については以下の記事にまとめています。
本記事で pandasで 欠損値(NaN)の値を確認、削除、置換する方法を学習できた方は再度復習してみましょう。
-
【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
また、PandasのDataFrameについての詳しい記事は、以下の記事にまとめていますので参照してください。
-

【Python】pandas.DataFrameの概要と作成方法・変換方法
続きを見る
人気記事 【入門から上級レベルまで】人工知能・機械学習の独学におすすめの本25選
人気記事 無料あり:機械学習エンジニアの僕がおすすめするAI(機械学習)特化型プログラミングスクール3社