

Pandasの簡単な使い方を知りたい。
これまでデータ処理を扱う方でも)統計処理の際にexcelで統計処理を行っていた方が多いと思います。
そのほかに使用しているツールとしてはSPSSなどでしょうか。
これからPythonを使う方は統計解析をプログラミングで行なって行く様になります【断言】ので、是非Pandasの使い方をマスターしましょう。
Pandasに関してはこちらのPandas公式サイトを参照にしてください。
Pandasでは基本的にCSVファイルに保存されているデータを扱います。
CSVファイルからは「DataFrame」という型のオブジェクトが作成されますが、これは ndarray とは異なるものです。
そのため、「DateFrame」とndarrayの相互交換についても解説していきます。
本記事での学習内容
- CSVファイルの読み込み方をマスターする
- CSVファイルで取り込んだデータを参照する
- DataFrame を ndarray に変換する(逆も然り)
では早速学習していきましょう。
Pandasによるデータの扱い方【手順あり】

csvファイルを読み込む
CSVファイルは、Excelと同じ様な表として使用できるファイルです。
pandasを使用したcsv/tsvファイルの読み込む方法、書き込む方法については以下の記事で非常に詳しく解説しています。
本記事で理解できない場合には、以下の記事で非常に理解が深まると思います。参考にしてみましょう。
-

【Python】pandasでCSV/TSVファイルを読み込む方法
続きを見る
今回 Machine Learning Repository で無料で配布されているbank.csv を使用します。(この bank.csv からファイルをダウンロードしてください)
ダウンロードしたらjupyter notebook にアップロードしましょう。(私はAWSのcloud9, jupyter notebookを普段使用しています。jupyter notebook は必ず使える環境にしておきましょう)
このbank.csvには、銀行の顧客情報のリストのサンプルが4500件ほど表形式で収納されています。
jupyter notebookにダウンロードしたら次にPandas、Numpy をインポートします。
In[]
1 2 3 | import pandas as pd import numpy as np bank_client = pd.read_csv("bank.csv") |
ここで、Seriest と、DataFrame というデータ型があります。
DataFrame は2次元配列のデータ型で、Seriest は1次元配列のデータ型です。
データを参照・表示する
DataFrameのメリットとして、Jupyter NotebookでDateFrameのデータが綺麗に表として出力されることがあります。
そうするとDataFrame型オブジェクトのメソッドに表示を任せると「綺麗な表」を出力してくれる点です。
pandasのDataFrameのデータを参照する方法としては以下の記事で非常に詳しく解説していますので、参考にして下さい。
-

pandasのdataframeの要素の参照方法をマスターしよう
続きを見る
さっそくJuputer Notebookで bank_client を実行してみましょう。
In[]
1 | bank_client |
すると、このような形で表が出力されます。
Out[]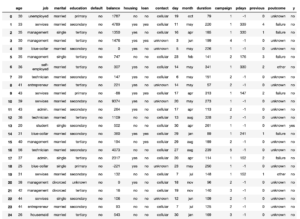
表の下にはまだまだ続きます。
ただ、これだと表示される内容が多すぎるため、CSVをちゃんと取り込めたかどうか確認するだけであれば、bank_client.head() を使います。
そうするとこの様な感じで最初の5行のみが表示されます。
末尾の5行を表示するときは bank_client.tail() を記入します。するとこの様に表示されます。
データのスライスの仕方
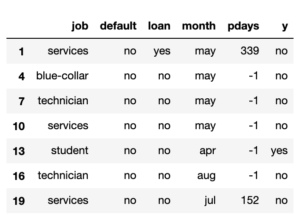
また、iloc[行, 列] を使用することで表の要素をスライスをすることが出来ます。
1 | bank_client.iloc[0:4, 0:4] |

1 | bank_client.iloc[1:20:3, 1:20:3] |
DataFrameを作成
panasはcsvファイルを読み込んで、DataFrame を作ることが多いですが、読み込んだデータを元に新しく、DataFrame を作ることがあります。
なお、Dataframeに関する公式ドキュメントは以下になります。
-
DataFrame — pandas 3.0.1 documentation
続きを見る

なお、pandas.Dataframeに関する公式ドキュメントは以下になります。
-
pandas.DataFrame — pandas 3.0.1 documentation
続きを見る

DataFrame の作り方についてみていきましょう。
DataFrameはエクセルやデータベースのような2次元の表データです。
index(行)、columns(列)、data(データの値)で構成されています。
indexは行名(行ラベル)、columnsは列名(列ラベル)、dataは実際のデータの値を意味します。
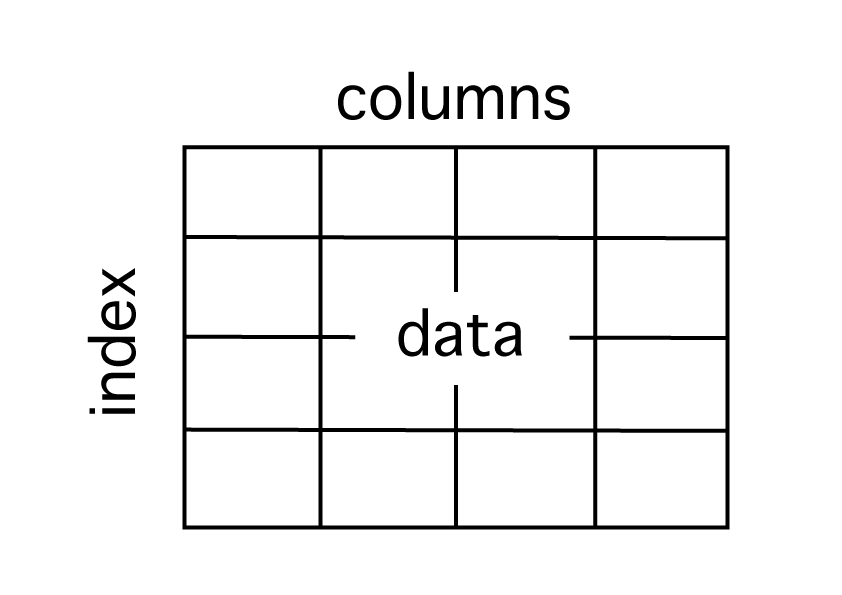
DataFrameを作るときにこれらのデータを引数に渡すことで、簡単に作ることができます。
まず、pandasのライブラリを読み込みましょう。
In
1 | import pandas as pd |
データを用意します。
名前を行名、体重、身長を列名にしたデータです。
In[]
1 2 3 4 5 6 7 | # columnsとindex columns = ['体重', '身長'] index = ['山田', '鈴木', '佐藤'] # data data = [[170, 60], [160, 60], [180, 75],] |
あとは、これらのデータをDataFrameを宣言するときに引数として渡します。
In[]
1 2 3 4 5 6 | # DataFrame作成 df = pd.DataFrame(data=data, columns=columns, index=index) # データ確認 df.head() |
Out[]
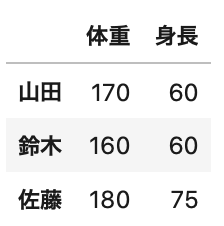
簡単に作れましたね。
下記の記事で詳しく説明しているので、参照してみてください。
-

【Python】pandas.DataFrameの概要と作成方法・変換方法
続きを見る
DataFrame と ndarray の相互変換

DataFrame → ndarray に変換する方法
DataFrame と ndarray の各々のデータ型は相互交換が可能です。
どちらのデータ型を使用するかどうかは、全て使用するライブラリ(PandasやNumpy)に依存します。
使用するライブラリによって適切なデータ型を使用しましょう。
DataFrame から ndarrayへ変換するためにはDataFrameのオブジェクトvalues を使用します。
実際に bank_client を使用してDtataFrame型から ndarray に変換してみましょう。
1 2 3 4 5 | # 入力 ndarray_bank_client = bank_client.values print(type(nd_bank_client)) print(**ndarray**_bank_client) |
1 2 3 4 5 6 7 8 9 | # 出力 <class 'numpy.ndarray'> [[30 'unemployed' 'married' ... 0 'unknown' 'no'] [33 'services' 'married' ... 4 'failure' 'no'] [35 'management' 'single' ... 1 'failure' 'no'] ... [57 'technician' 'married' ... 0 'unknown' 'no'] [28 'blue-collar' 'married' ... 3 'other' 'no'] [44 'entrepreneur' 'single' ... 7 'other' 'no']] |
ここで、なお values プロパティには列見出しの情報は入っていません。
ndarray に直す時に、列の見出しのみが欲しいときは 配列名.columns.values と入力しましょう。
実際に列名を出力してみます。以下の入力をします。
1 2 3 4 | ndarray_bank_columns = bank_data.columns.values print(type(ndarray_bank_columns)) print(ndarray_bank_columns) |
出力した結果はこの様になります。
1 2 3 4 | <class 'numpy.ndarray'> ['age' 'job' 'marital' 'education' 'default' 'balance' 'housing' 'loan' 'contact' 'day' 'month' 'duration' 'campaign' 'pdays' 'previous' 'poutcome' 'y'] |
ndarray → DataFrame に変換する方法
ndarray から DataFrame に変更するためには pd.DataFrame() を実行します。
pd.DateFrame() はコンストラクタの一つです。コンストラクタを忘れた方は以下を参照にしてください。
pd.DateFrame() の引数 () に data と columns に対して各々、ndarray_bank_client, またndarray_bank_colums を指定しましょう。
実際にDateFrame型にオブジェクトを変更してみましょう。
以下の入力を実行してみます。
1 2 3 4 | reverse_bank_client = pd.DataFrame(data = ndarray_bank_client, columns = ndarray_bank_columns) print(type(reverse_bank_client)) reverse_bank_client.head() |
するとこの様な表が出力されて、実際にDateFrame型に変更されたことがわかります。

NaN(欠損値)を処理する方法
現場でデータを扱っていると、必ずしもデータが完全な状態ではなく、データが欠損していることがあります。
欠損がある場合、不備のあるデータを削除したり、置き換えたりします。
その方法について次のデータで確認していきましょう。
まず、下記のコードを入力して下さい。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 | import pandas as pd # columns columns = ['身長', '体重'] # data data = [[100, 20], [110, 22], [110, 23], [120, ], [130, 30], [135, 35], [140, 40],] df = pd.DataFrame(data=data,columns=columns) df.head(7) |
Out[]
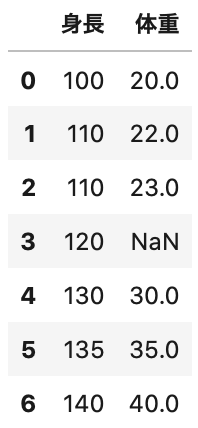
身長・体重の相関表
表を確認すると、身長120のところの体重が欠損している事が分かります。
NaN(欠損値)を削除する方法
NaN(欠損値)を削除する方法について学習していきましょう。
dropna()メソッドを使うとNaNを削除する事ができます。
pandas.DataFrame.dropna の公式ドキュメントは以下になります。
-
pandas.DataFrame.dropna — pandas 3.0.1 documentation
続きを見る

In[]
1 2 | df_drop = df.dropna() df_drop.head(7) |
Out[]

NaN(欠損値)を削除した後の身長・体重の表
NaN(欠損値)を置換する方法
NaN(欠損値)を置換する方法について学習しましょう。
fillna()メソッドを使うとNaNを違うデータに置き換える事ができます。
今まで表示したデータは身長120cmの体重のデータなので、身長110cmと130cmの間くらいの体重27kgでNaN(欠損値)を置き換えてみましょう。
In[]
1 2 | df_fill = df.fillna(27) df_fill.head(7) |
Out[]
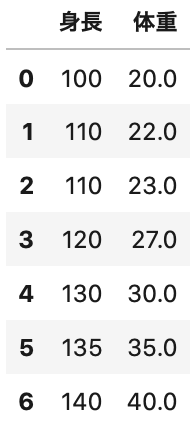
NaN(欠損値)を体重27kgで置換した後の身長・体重の表
NaN(欠損値)の処理の方法については、実務にも対応できる様に以下の記事でかなり詳しく解説しています。
NaN(欠損値)の処理方法について学習したい方は参考にどうぞ。
-

pandasで欠損値(NaN)の値を確認、削除、置換する方法
続きを見る
Pandasの計算処理の方法

データ解析する上では、計算してその特徴を捉えたり、新しい特徴量、指標などを算出する必要があります。
例えば、身長と体重のデータを持っているとします。
例えば、以下の様にコードを打ってみましょう。
In[]
1 2 3 4 5 6 | import numpy as np import pandas as pd df = pd.DataFrame(data=[[170, 60], [165, 60], [180, 75]], columns=['tall', 'weight']) df.head() |
Out[]
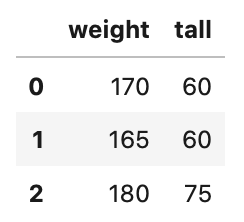
身長と体重があると、新しくBMIを指標として計算することもあるでしょう。
BMIを計算してみましょう。
In[]
1 2 3 4 5 | # BMI = 体重kg ÷ (身長m)2 df['BMI'] = df['weight'] / (df['tall']/100*df['tall']/100) # データ確認 df.head() |
Out[]
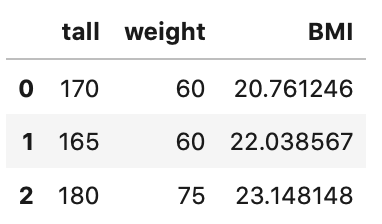
pandasの計算処理の方法には、いろいろな方法があります。
以下の記事で詳しく説明しているので、詳しく学習してみましょう。
-
【Python】pandas, seabornの計算処理のまとめ
続きを見る

pandasで Excelシートに読み込み、書き込みをする方法
Excelはcsvと同様、実務でもよく出てくるデータです。
データ解析時は色々なデータをかき集めて解析するので、 Excelも自由自在に扱えるようにしていきましょう。
Excelを読み込み込むときには、read_excelメソッドを使います。
read_excel にファイルのパスを指定するだけで、簡単に読み込めます。
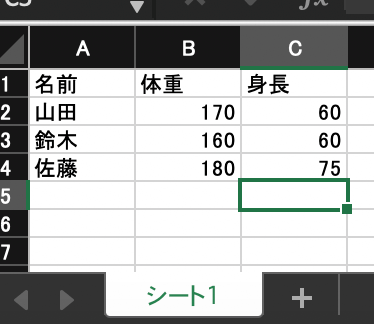
下記のような Excelデータを読み込んでみましょう。
In[]
1 2 3 4 5 6 7 8 | # pandas読み込み import pandas as pd # パス設定 data_path = 'https://obgynai.com/sample.xlsx' # 読み込み df = pd.read_excel(data_path) # データ確認 df.head() |
Out[]
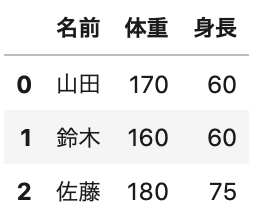
簡単に出力できましたね。
ファイルはウェブにあるファイルを読み込んでいます。
皆さん各自、自分の手元にある Excelのファイルを読み込む場合はdata_pathを変更ください。
下記リンクでpandasを利用した Excelの読み込み方、書き込み方に関する方法について詳しく解説しています。参照してください。
-

【Python】pandasでExcelファイルを読み込む方法
続きを見る
-

【Python】pandasでExcelファイルを書き込む方法
続きを見る
まとめ|Pandasの使い方は簡単

如何でしたでしょうか。
Pandas で表を取り込み、表を描出する方法を解説しました。
これで、ご自身で持っているファイルも描出することがこの通りに実行していけば可能です。
今回はこれで以上とします。