
こんにちは。
産婦人科医で人工知能の研究をしているTommy(Twitter:@obgyntommy)です。
本記事ではPythonのライブラリの1つである pandas の計算処理について学習していきます。
pandasの使い方については、以下の記事にまとめていますので参照してください。
-

【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
また、pandasで Excelファイルを書き込む方法については以下の記事を参考にしてください。
-

【Python】pandasでExcelファイルを書き込む方法
続きを見る
データ解析をする際にはCSV、データベースなどのデータを扱いますが、Excelもその一つです。
pandasでExcelデータを取り扱えうようになれれば、普段、エクセルでデータを扱っている多くのユーザーとデータを共有できるようになります。
本記事では pandas を利用して Excel の読み込み方を習得してを使いこなせるようになりましょう。
なお、pandas.read_excel に関する公式ドキュメントは以下になります。
-
pandas.read_excel — pandas 3.0.5 documentation
続きを見る

ここで本記事の学習到達目標です。
本記事の学習目標
- pandasのインストール方法を学習する
- Excelのシートを指定する方法を学習する
- Excelを1つずつ、又はまとめてデータを読み込む方法を学習する
- Excelの列名、行名がある場合、ない場合についての対応を学習する
今回は、これらのテーマに沿って Excelを読み込む方法についてしっかり学習していきましょう。
データの準備とpandasの実行

pandasのインストール方法
pandasでエクセルを取り扱うときには、xlrd をインストールしておきましょう。
In[]
1 2 3 4 5 | pip install xlrd or pip3 install xlrd |
pandasをインポートする
まず、pandas を読み込みます。
下記を実行してください。
In[]
1 2 | # pandasの読み込み import pandas as pd |
本記事で扱う対象データ
データは適当に用意した下記のデータを使います。
Sheet1, 2, 3, 4 にデータが入っているExcelファイルです。
実行して、パスを設定しておきましょう。
In[]
1 2 3 | # データパス data_path = 'https://obgynai.com/sample.xlsx' Sheet1 |
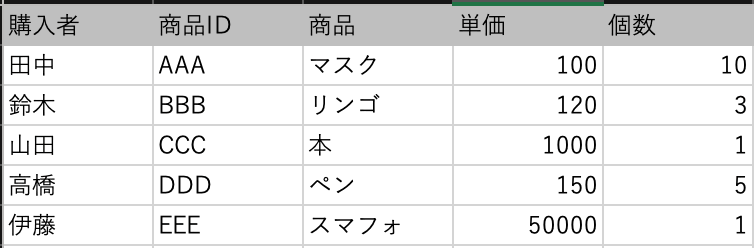
Sheet1
1列目に列名があるデータです。
Sheet2
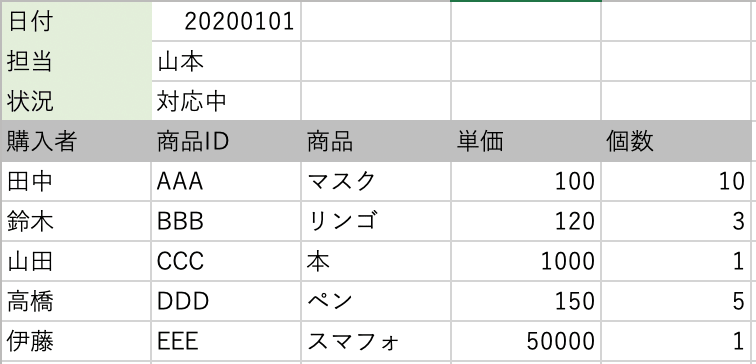
Sheet1に3行ほど、他のデータが混じっていて、4行目からデータが始まっている場合です。
Sheet3
以下の表がSheet1の列名がない場合です。

Sheet4
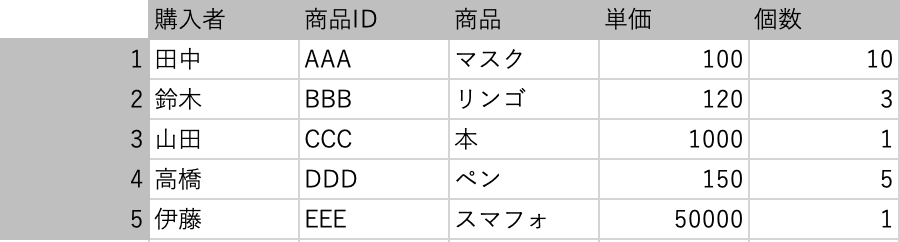
Sheet1に index(行名)をつけたもの
行名は 1, 2, 3, 4, 5 としています。
index は数値に限らず、文字列でもOKです。
読み込み

pandasでエクセルを読み込むときには、read_excelメソッドを使います。
さっそく、読み込んでみましょう。
read_excel メソッドにエクセルのパスを渡します。
In[]
1 2 3 4 | # エクセル読み込み df = pd.read_excel(data_path) # データ確認 df.head() |
Out[]
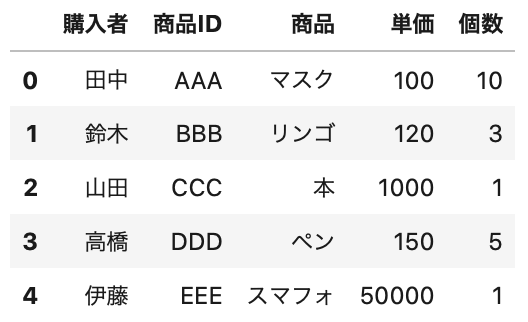
引数にファイルのパスだけ渡すと、1つ目のシートを読み込みます。
Excelシートを指定する方法
Excelのファイルとcsvファイルが明確に違うところは、Excelにはシートの概念があるということですね。

どのシートを読み込むかは、パラメータの「sheet_name」で指定できます。
指定方法は、左から順に 0, 1, 2, 3 と指定するか、シート名で指定します。
指示しない場合は、sheet_name=0 となっているので、ファイル名だけ渡すと1つ目のシートを読み込みます。
1つずつ Excelデータを読み込む方法
まず、数値で指定して2番目のSheet2を読んでみましょう。
In[]
1 2 3 4 | # Sheet2を読み込み df = pd.read_excel(data_path, sheet_name=1) # データ確認 df.head() |
Out[]
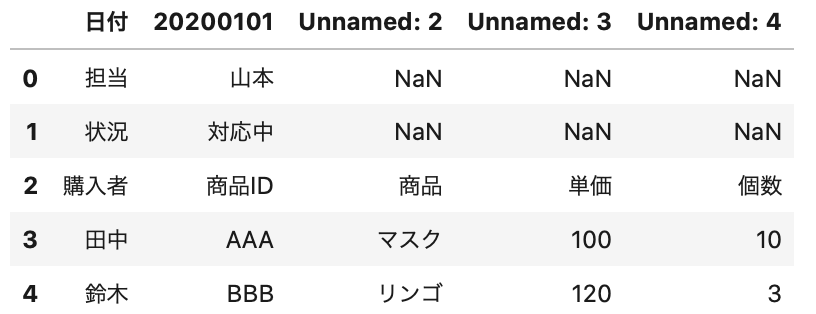
きちんとファイルを読み込めているのが分かりますね。
列名が、Unnamed2, 3になっているのは、データの開始位置がずれているためです。
後で読めるように調整していきましょう。
次に、シート名を指定して、Sheet2を読み込みましょう。
In[]
1 2 3 4 | # Sheet2を読み込み df = pd.read_excel(data_path, sheet_name='Sheet2') # データ確認 df.head() |
Sheet1と同様に、Sheet2が読み込めた事が分かりました。
まとめて Excelデータを読み込む方法
sheet_name は list で複数のシートを指定することができます。
指定は数値によるシートの並び順でも、シート名でも指定でき、混在して指定することができます。
sheet_name=[‘Sheet2’, 0] でSheet2とSheet1を読み込みましょう。
読み込んだ後、型を確認します。
In[]
1 2 3 4 | # Sheet2,1を読み込み df_dict = pd.read_excel(data_path, sheet_name=['Sheet2', 0]) #型の確認 print(type(df_dict)) |
複数指定した場合は、dict で返ってきます。
DataFrame を取り出すには、sheet_name で指定した値を使います。

DataFrame で取り出して、データを確認しましょう。
「0」のSheet1を確認
In[]
1 | df_dict[0].head() |
「Sheet2」のSheet2を確認
In[]
1 | df_dict['Sheet2'].head() |
全ての Excelシートを読み込む方法
全てのシートを読み込む場合には、sheet_name=None を使用します。
この場合は、シート名の「Sheet1」「Sheet2」…がキー値となります。
In[]
1 2 3 4 | # 全シートを読み込み df_dict = pd.read_excel(data_path, sheet_name=None) # Sheet1の確認 df_dict["Sheet1"].head() |
Excelにheader(列名)がある場合

列名を指定して読み込んだり、データの開始位置がずれているデータについてもみていきます。
Excelの列名を指定して読み込む方法
次は、Sheet1を列名を指定して読み込みます。
データはなんでも詰め込まれて入っている場合が多いです。
read_csv でパラメータ「usecols」を指定することで、必要な列のみを取得できます。
対象の列名は、usecols に [‘列名’, ‘列名’, …] とリスト型で指定します。
In[]
1 2 | df = pd.read_excel(data_path, sheet_name='Sheet1', usecols=['購入者', '商品ID']) df.head() |
Out[]

Excelの列名の位置がずれている場合
データを取り扱うと色々なフォーマットに出会います。
「Sheet2」では最初の3行に日付などのデータが入っており、使いたいデータは4行目から始まっています。
この場合は開始位置をパラメータ「header」で開始行を指定します。
開始行は0から数えるので、今回は header=3 を指定します。
In[]
1 2 | df = pd.read_excel(data_path, sheet_name='Sheet2', header=3) df.head() |
Out[]
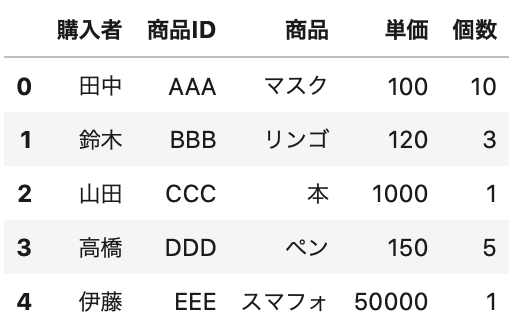
最初の3行を飛ばして、読み込めているのが分かりますね。
Excelのheader(列名)がない場合

列名がないデータもよくあるので、その際の対処法について見ていきましょう。
列名のない「Sheet3」を読み込んでみます。
列名ない場合は、パラメータ「header」を None とします。
In[]
1 2 | df = pd.read_excel(data_path, sheet_name='Sheet3', header=None) df.head() |
この場合、列名は0,1…と自動で数字が割り当てられます。
Out[]

列を指定して読み込む方法
header がなくても、usecols を使うことで、読み込む列を指定できます。
指定する列は、自動で割り振られる数値を [0, 1] のように指定します
In[]
1 2 | df = pd.read_excel(data_path, sheet_name='Sheet3', header=None, usecols=[0, 1]) df.head() |
Out[]

Excelの列名を付与する方法
列名がただの数値では、何の列だか分かりにくいですよね。
そんな時は、パラメータ「names」に列名をタプルやリスト型で指定できます。
In[]
1 2 3 | df = pd.read_excel(data_path, sheet_name='Sheet3', header=None, names=['購入者', '商品ID', '商品', '単価', '個数']) df.head() |
Out[]
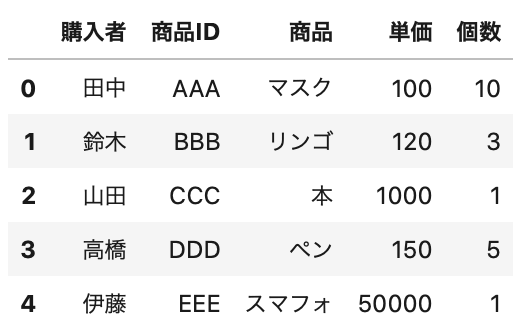
Excelでindex(行名)がある場合の読み込む方法

次に、Sheet4の index がついているデータを読み込みます。
1行目は自動で header とされますが、1列目は列データとして取り扱われます。
これでは、1列目を index として使えません。
In[]
1 2 | df = pd.read_excel(data_path, sheet_name='Sheet4') df.head() |
Out[]
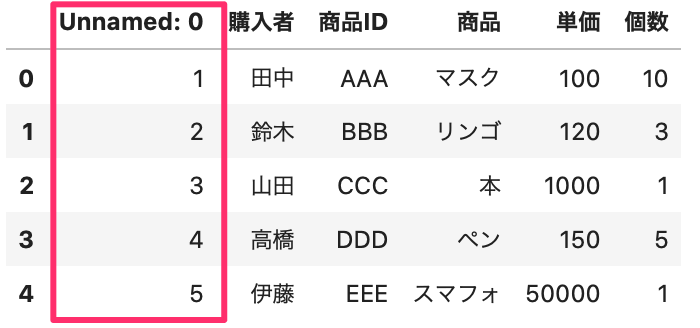
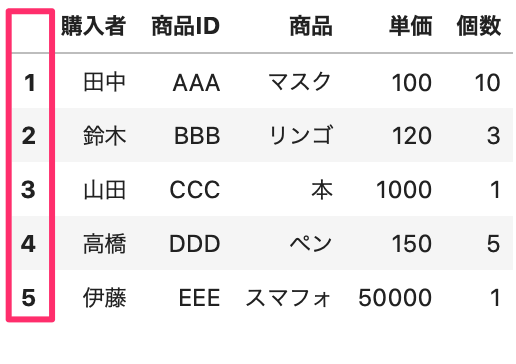
これを、index と指定するには、パラメータ「index_col」を使用します。
1, 2, 3 列目は 0, 1, 2 とカウントするので、index_col=0 として1列目を index とします。
In[]
1 2 | df = pd.read_excel(data_path, sheet_name='Sheet4', index_col=0) df.head() |
Out[]
Excelのindex(行名)を指定して読み込む方法

指定した列のデータを取得したい場合、列名を指定していましたが、
指定した行のデータを取得したい場合では、読み込みたくない行名を指定します。
その場合、パラメータ「skiprows」に除外したい行名をタプルやリストにして渡します。
今回は、index が 1, 2, 3, 4, 5 と指定されている状態で確認していきましょう。
まず、index が 1 のもの以外を読み込む場合。
In[]
1 2 | df = pd.read_excel(data_path, sheet_name='Sheet4', index_col=0, skiprows=[1]) df.head() |
Out[]
これでは、実用性がないので、1つとびでデータを取得したい場合もやってみましょう。
range メソッドで、(1, 3, 5) というタプルを作って、偶数行の 2, 4 だけ読み込みます。
In[]
1 2 3 | skip_rows = range(1,6,2) # (1, 3, 5) df = pd.read_excel(data_path, sheet_name='Sheet4', index_col=0, skiprows=skip_rows) df.head() |
pandas の使用方法については以下の記事にまとめています。一通り本記事でpandasで Excelを使用する方法を学習できた方は再度復習してみましょう。
-
【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
また、pandasで Excelファイルを書き込む方法については以下の記事を参考にしてください。
-
【Python】pandasでExcelファイルを書き込む方法
続きを見る