
こんにちは。産婦人科医で人工知能の研究に従事しているTommy(Twitter:@obgyntommy)です。
本記事はPythonのライブラリであるseabornについて学習するための記事になります。【前編】【後編】に分けて解説しますが、今回はそのうち【後編】となります。
前編を読んでいない方は、まず以下の記事で学習して下さい。
-

PythonのライブラリSeabornの使い方【前編】
続きを見る
本記事の学習到達目標
- 様々なグラフの表示方法を修得する
- グラフを複数表示する方法を修得する
では早速、学習していきましょう。
※ "seabornとは" についてはPythonのライブラリseabornの使い方【前編】で解説したので省略させて頂きます。
seabornのインストール方法と本記事で使用するデータ一覧については、【前編】でも解説しましたが、再度掲載させて頂きます。
seabornのインストール方法

インストールは pip で行いましょう。
ライブラリをインストールする際には、pip 、pip3 のどちらかを使うことになりますが、どちらでもOKです。
普段使っている方で、インストールして下さい。
In[]
1 2 3 4 5 | pip install seaborn 若しくは pip3 install seaborn |
本記事で使用するデータ一覧

本記事では乱数ではなく、データ解析入門で使われる実データを使います。
実際に、仕事をしている中で実データを解析していくイメージで学習を進めていきましょう。
注意ポイント
seabornではDataFrame型をよく使います。numpyでも使えるグラフもありますが、DataFrameで統一すると良いでしょう。
DataFrameはCSVやデータベースをなどの表データです。
iris
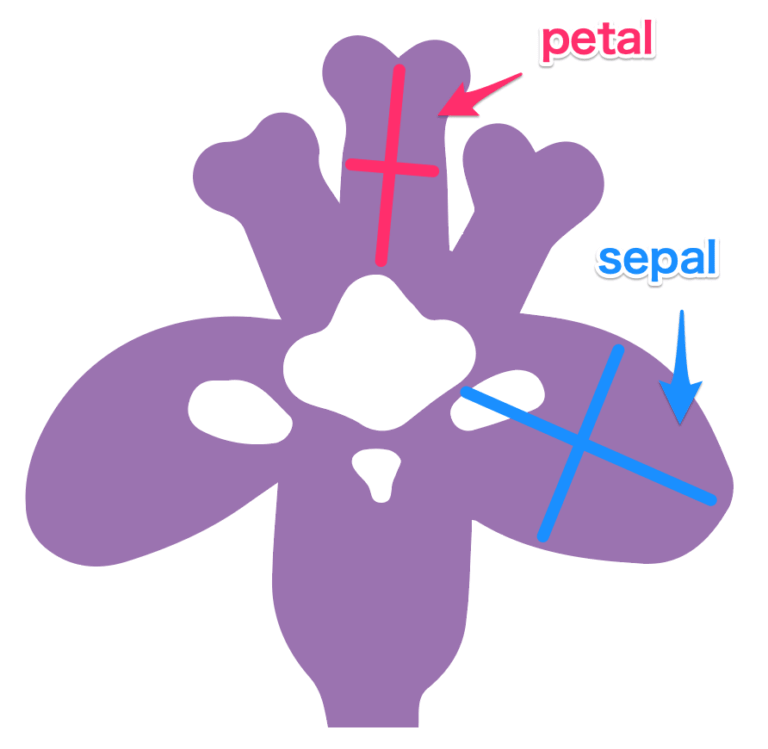
irisデータはアヤメ3種類それぞれのがく片(sepal)、花弁(petal)の幅と長さのデータセットです。
| sepal length | 花弁長さ |
| sepal width | 花弁幅 |
| petal length | がく片長さ |
| petal width | がく片幅 |
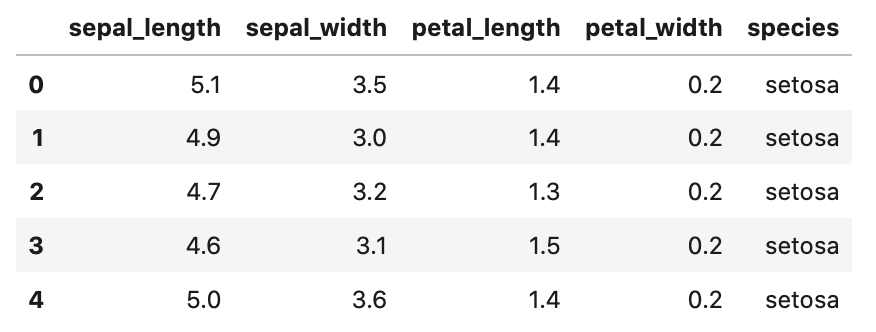
データの取得の仕方は簡単、sns.load_dataset(“iris”) で欲しいデータが手に入ります。
データのtype(型)はpandasのDataFrameです。
In[]
1 2 3 4 5 | import seaborn as sns # データの型: pandas.core.frame.DataFrame iris = sns.load_dataset("iris") # データ最初の5行表示 iris.head() |
Out[]
タイタニック
このデータはグラフ表示で使用します。
タイタニックのデータはどういった人が生存できたかを予測する問題です。
| survived | 0:死亡 1:生存 |
| pclass | チケットクラス 1:上級 2:中級 3:初級 |
| sex | 性別 |
| age | 年齢 |
| sibsp | 同乗の兄弟配偶者の数 |
| parch | 同乗の親子供の数 |
| fare | 料金 |
| embarked | 出港地(C=Cherbourg、Q=Queenstown、S=Southampton) |
| class | チケットクラス |
| who | 男性 / 女性 |
| adult_male | 成人男性かどうか |
| deck | 乗船していたデッキ |
| embark_town | 出港地 |
| alive | 生存したかどうか |
| alone | 一人であったかどうか |
In[]
1 2 3 | import seaborn as sns taitanic = sns.load_dataset("titanic") taitanic.head() |
Out[]

様々なグラフの表示方法

グラフの表示では、irisとtitanicのデータを使用していきます。
グラフは簡単にデータの特徴を伝えることができますが、間違ったグラフを選ぶとわかりにくい場合もあります。
適切なグラフを選択できるよう練習していきましょう。
countplot(棒グラフ)
countplotはカテゴリ変数の数を見るときに使用します。
よく使いそうなパラメータは6つ。
| x / y | カウントする列名。x指定で縦方向。y指定で横方向。 |
| hue | カウントした軸をさらにカテゴリで分ける列名 |
| data | 対象データ |
| order | グラフの並び順をlistで指定 |
| hue_order | hueで指定したカテゴリの並び順をlistで指定 |
titanicの生存者の数を確認
まず、生存者数をカウントした棒グラフを描画します。
xに survived の列を表示させ、data に titanic を使用します。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() titanic = sns.load_dataset("titanic") sns.countplot(x='survived', data=titanic) |
Out[]
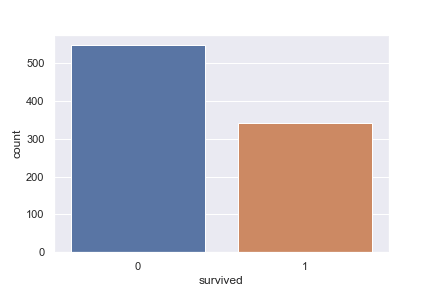
titanicの生存者の数【棒グラフ】
alive 列の1(生存者)、0(死亡者)の数が比較できました。
これでわかりやすくなったでしょうか。皆さんはどう感じられましたか?
| 1(生存者) | 342人 |
| 0(死亡者) | 546人 |
なんだか、表の方がわかりやすいようにも思えます。
titanicの生存者の数をclass(チケットクラス)に分けて確認
次はclass(チケットクラス)に分けて確認してみましょう。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() titanic = sns.load_dataset("titanic") sns.countplot(x='survived', hue='class', data=titanic) |
classごとのカウント数にすることで、それぞれの死亡者、生存者数の比較ができます。
Out[]
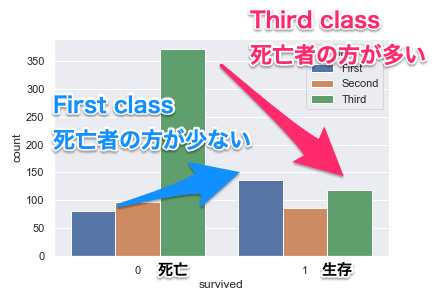
titanicの生存者の数を死亡者、生存者で分ける
生存率を確認したい時には、下記の表でも良いかもしれません。
| 乗客数 | 生存者数 | 生存率 | |
| First | 216 | 136 | 63% |
| Second | 184 | 87 | 47% |
| Third | 491 | 119 | 24% |
表現方法を変えて、次のbarplotでも見ていきます。
barplot(棒グラフ)
barplotでは、データの平均値とエラーバーをグラフにします。
よく使いそうなパラメータは8つあります。
| x | X軸で使用するデータの列名 |
| y | Y軸で使用するデータの列名 |
| hue | 軸をさらにカテゴリで分ける列名 |
| data | 対象データ |
| order | グラフの並び順をlistで指定 |
| hue_order | hueで指定したカテゴリの並び順をlistで指定 |
| ci | confidence intervals(信頼区間)の幅 |
| n_boot | 信頼区間算出のブートストラップ数 |
他のパラメータはグラフの見た目などに関係してくる項目となります。
class(チケットクラス)ごとの生存率を確認する
class(チケットクラス)ごとの生存率を見てみます。
- $x$ 軸にclass(チケットクラス)
- $y $ 軸にsurvived(0:死亡,1:生存)
この様に定義します。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() titanic = sns.load_dataset("titanic") sns.barplot(x='class', y='survived', data=titanic) |
Out[]
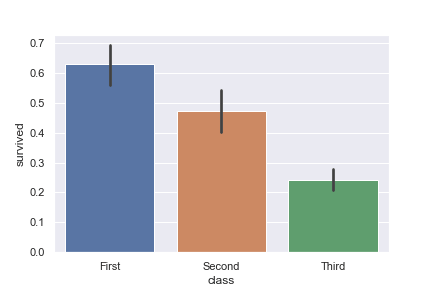
classごとの生存率を棒グラフで比較する
coutplot のところでも確認しましたが、classごとで生存率が大きく違います。
barplot はデータの平均値を表示するグラフですがが、なぜ、$y$ (縦軸)=survived(0:死亡,1:生存)で、生存率になるのでしょうか?
例えば4人分のデータで 0(死亡), 1(生存), 0(死亡), 0(死亡)があったときに、この平均を算出すると(0+1+0+0)/4=0.25となるので、この値が生存率になりますよね。
class(チケットクラス)ごとの生存率をsex(性別)で分ける
class(チケットクラス)とsex(性別)の生存率を見ていきましょう。
hue=sex とします。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() titanic = sns.load_dataset("titanic") sns.barplot(x='class', y='survived', hue='sex', data=titanic) |
Out[]
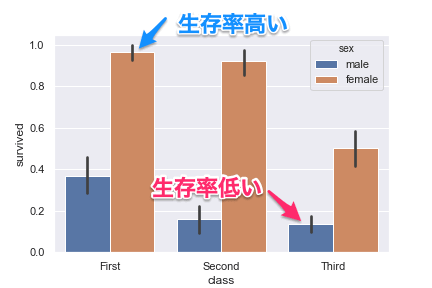
classのsex別の生存率
このグラフでは生存率の高い人の条件が class=First で sex=female であることが一目でわかります。
当時、特に女性を優先して助けたのがわかりますね。
表にするより圧倒的にこのグラフの方がわかりやすいでしょう。
ヒストグラム
ヒストグラムはどのデータを区間ごとに分け、多い少ないを把握することができるグラフです。
その分布が正規分布かどうかなどを確認します。
seabornではdistplotを使用します。
よく使いそうなパラメータは5つあります。
kde, hist, bin, rugplot の違いについては以下の図で把握しましょう。
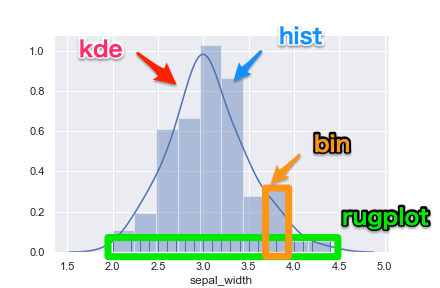
distplotを使用したヒストグラム
distplot では DataFrame の1行、1列分にあたる Series 型をデータとして与えます。
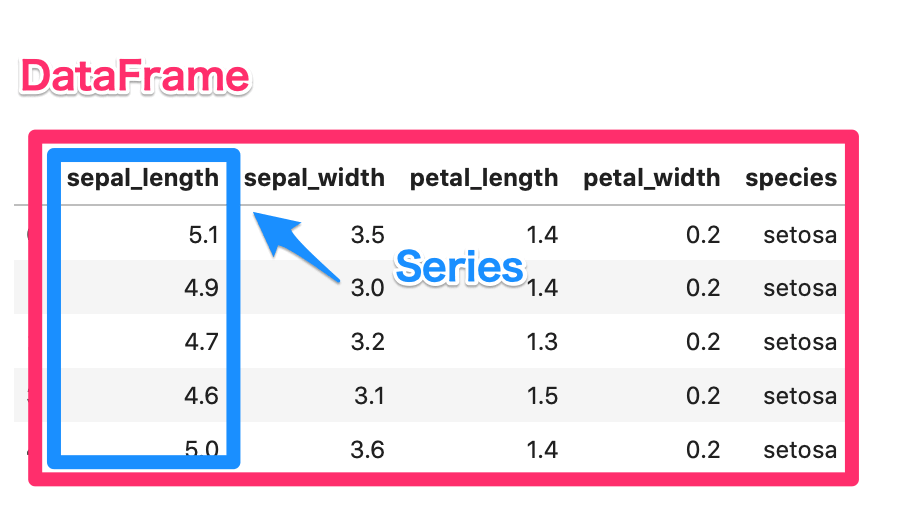
DataFrameの1行、1列分にあたるSeries型をデータとして与える
1列のデータの取得は、DataFrame(‘列名’)で取得ができます。
irisデータの sepal_width 列を取得してみましょう。
合わせて、型も確認しています。
【SeriesとDataFrameの型の違い】
DataFrame(表)、Series(行 or 列)として捉えましょう。
In[]
1 2 | iris_sepal_w = iris['sepal_width'] type(iris_sepal_w) |
sepal_widthの分布
irisデータの sepal_width の分布を確認しましょう。
distplotに iris[‘sepal_width’] を与えます。
その際に、a=iris[‘sepal_width’] としても良いですし、a=を省略しても良いです。
In[]
1 2 3 4 5 6 | import seaborn as sns sns.set() iris = sns.load_dataset("iris") # sns.distplot(a=iris['sepal_width']) sns.distplot(iris['sepal_width']) |
Out[]
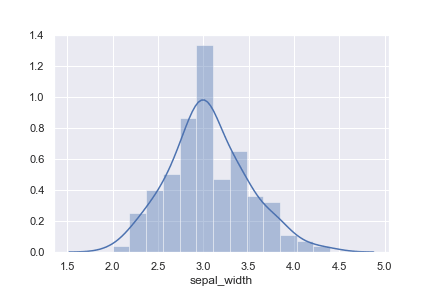
irisデータのsepal_widthの分布
3を中心に2〜4.5までの範囲で値が広がっています。
このグラフで簡単に、どこのデータが多いかなどのデータの分布が確認することができます。
sepal_widthをspecies(品種)ごとの分布に分けてグラフ化する
品種ごとに分けてグラフにしてみましょう。
品種ごとにデータを分ける場合は、iris[条件][対象列名] とします。
例えば、speciesが setosa のデータを取得する場合、iris[‘species’]==’setosa’ を条件に入れます。
In[]
1 | iris[iris['species']=='setosa']['sepal_width'] |
では、3品種のデータをヒストグラムにしてみましょう。
3つのデータをグラフにする場合は、そのまま3回実行します。
In[]
1 2 3 4 5 6 7 | import seaborn as sns sns.set() iris = sns.load_dataset("iris") sns.distplot(iris[iris['species']=='setosa']['sepal_width']) sns.distplot(iris[iris['species']=='versicolor']['sepal_width']) sns.distplot(iris[iris['species']=='virginica']['sepal_width']) |
Out[]
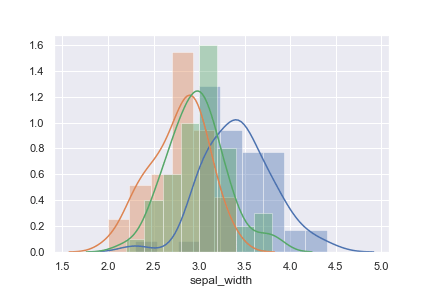
3種のデータをヒストグラムにした分布
上図を見てみると、3つの品種ごとに山の中心ずれていることがわかります。
このグラフでも、sepal_width は品種を判断するのに使えそうなデータであることがわかります。
散布図
散布図は、二つのデータが相関関係にあるかどうかを確認します。
irisのデータを使って、各値の相関関係を見ましょう。
散布図はいくつか方法があるので順番に紹介していきます。
seaborn.scatterplot
scatterplotはシンプルな散布図です。
パラメータが多いですが、よく使いそうなのは下記の6つです。
| data | 対象のデータ。DataFrame型 |
| x | x軸のデータにする列名 |
| y | y軸のデータにする列名 |
| hue | グルーピングする列名 |
| style | マーカーを変えてプロットするグループの列名 |
| size | マーカーサイズを変えてプロットするグループの列名 |
sepalのwidthとlengthの関係を見てみましょう。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() iris = sns.load_dataset("iris") sns.scatterplot(x='sepal_width', y='sepal_length', hue="species", data=iris, style="species") |
Out[]
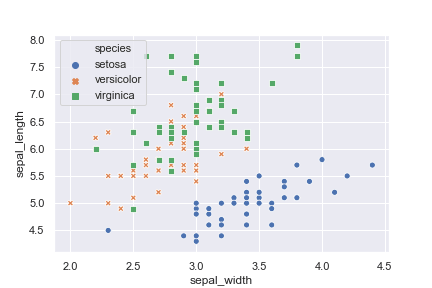
sepalのwidthとlengthの散布図の関係
sepalのwidthとlengthには相関がありそうですね。
また、種別ごとにプロットされる位置が違うので、データとしての違いが出ているのがわかります。
jointplot
joinplotというメソッドでも散布図が描画でき、$X$ 、$Y$ 軸のデータにヒストグラムを描画します。
よく使いそうなパラメータは4つあります。
| data | 対象のデータ。DataFrame型 |
| x | x軸のデータにする列名 |
| y | y軸のデータにする列名 |
| kind | グラフの表示方法 5つ scatter : 散布図 reg: 散布図と回帰直線 resid: 回帰直線からの残差 kde: カーネル密度推定の等高線 hex: 六角形のヒートマップ |
これはグループ分けするhueパラメータがありませんので、種別は1つずつ表示します。
そのため、dataにはiris[iris[‘species’]==’setosa’]と条件をつけてデータを与えます。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() iris = sns.load_dataset("iris") sns.jointplot(x='sepal_width', y='sepal_length', data=iris[iris['species']=='setosa']) |
kindのパラメータを変更すると色々なグラフになります。
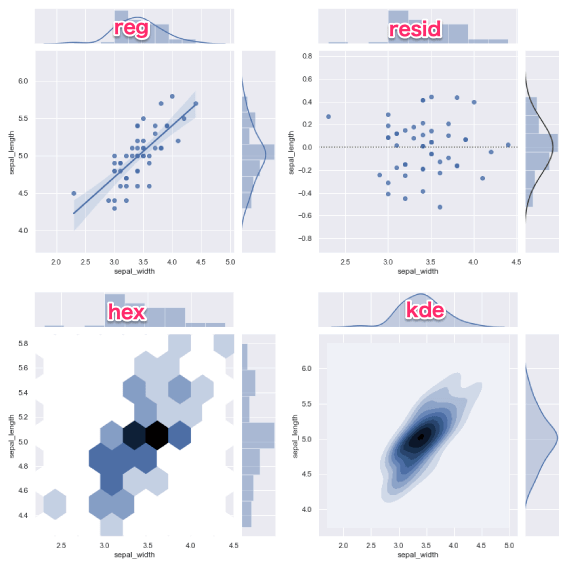
ヒートマップ
ヒートマップはマトリックス図の値を色で値の高低を表現します。
各データの相関係数を確認する場合などに使います。
今回はirisデータの相関係数をヒートマップで表現します。
相関係数はpandas.DataFrameの corr メソッドで算出できます。
In[]
1 | iris.corr() |
Out[]
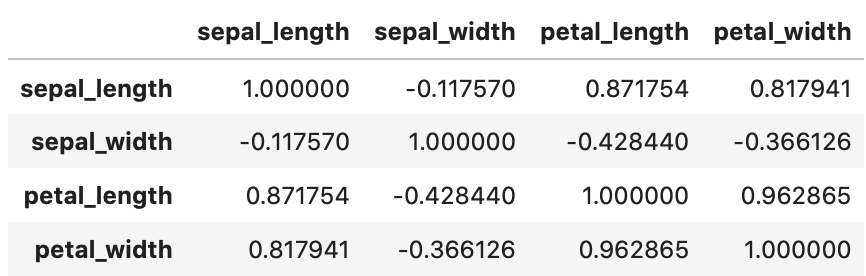
irisデータの相関係数
ヒートマップの描画は、seabornではheatmapメソッドを使います。
よく使いそうなパラメータは8つあります。
| data | 対象データ |
| vmin | 色の下限値 |
| vmax | 色の上限値 |
| center | カラーマップを中央に配置する値 |
| cmap | 色の種類。matplotlibのcolormap |
| annot | マトリックス図に値の表示 |
| fmt | annot=true時の表示するデータのフォーマット |
色の上下限を-1.0〜1.0にして相関係数のヒートマップを描画します。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() iris = sns.load_dataset("iris") sns.heatmap(iris.corr(), vmin=-1.0, vmax=1.0, annot=True, fmt=".1f") |
Out[]
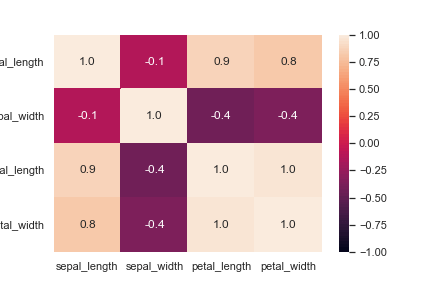
irisの相関係数のヒートマップ
ボックスプロット
ボックスプロット(箱ひげ図)はカテゴリごとのデータのばらつきや、中心値のずれ具合などを確認することができます。
seabornでは、boxplotメソッドを使用します。
使いそうなパラメータは6つです。
| x | X軸で使用するデータの列名 |
| y | Y軸で使用するデータの列名 |
| hue | 軸をさらにカテゴリで分ける列名 |
| data | 対象データ |
| order | グラフの並び順をlistで指定 |
| hue_order | hueで指定したカテゴリの並び順をlistで指定 |
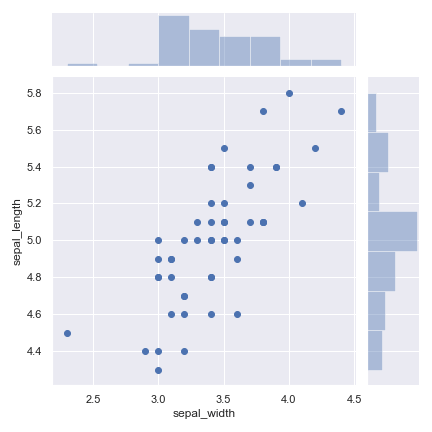
species ごとの sepal_width の値を見てみます。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() iris = sns.load_dataset("iris") sns.boxplot(x='species', y='sepal_width', data=iris) |
Out[]
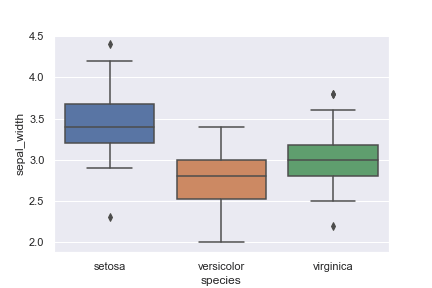
irisデータの箱ヒゲ図
ヒストグラムでは少しわかりにくかったですが、sepal_width が species ごとに差があることがわかります。
バイオリンプロット
バイオリンプロットはボックスプロットをカーネル密度分布で表現したようなものです。
seabornでは、violinplotメソッドを使用します。
使いそうなパラメータは6つあります。
| x | X軸で使用するデータの列名 |
| y | Y軸で使用するデータの列名 |
| hue | 軸をさらにカテゴリで分ける列名 |
| split | hueを2つのレベルで指定した場合、バイオリンを半分で分ける |
| data | 対象データ |
| order | グラフの並び順をlistで指定 |
| hue_order | hueで指定したカテゴリの並び順をlistで指定 |
ボックスプロットと同様に、species ごとの sepal_width の値を見てみます。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() iris = sns.load_dataset("iris") sns.violinplot(x='species', y='sepal_width', data=iris) |
Out[]
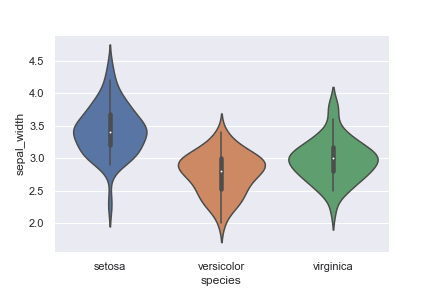
irisデータの相関係数をバイオリンプロットで表示
折れ線
seabornの折線グラフは、matplotlibのplotのようなものがないので、近いpointplotを使ってみます。
irisもtitanicも折線グラフには向かないデータなので、実際のウイルスの感染者数を抜粋したデータを使います。
データは下記で作ります。データ作っているだけなので、コピペで実行してください。
In[]
1 2 3 4 5 6 7 | patient = pd.DataFrame(columns=['No', 'negative', 'serious']) list_negative = [1, 1, 1, 2, 5, 35, 83, 111, 148, 158, 167, 177, 194, 239, 313] list_serious = [ 0, 0, 0, 0, 0, 1, 3, 3, 5, 6, 7, 7, 8, 10, 14] for i in range(len(list_negative)): tmp_se = pd.Series([i+1, list_negative[i], list_serious[i]], index=patient.columns ) patient = patient.append( tmp_se, ignore_index=True ) patient.head() |
patientというDataFrameができます。
それぞれ、列名のnegative(陽性)、serious(重症)は患者数を表しています。
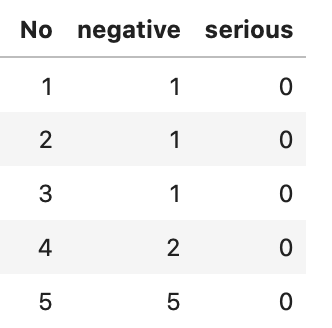
列のnegative(陽性)、serious(重症)は患者数
あとは、このデータを pointplot で negative 、serious の数を折れ線グラフにします。
pointplotのパラメータで使いそうなのは7つ。
今回のデータにグループ分けしたいデータはないので、hueは使いません。
| x | X軸で使用するデータの列名 |
| y | Y軸で使用するデータの列名 |
| hue | データをグループ分けする列名 |
| data | 対象データ |
| order | グラフの並び順をlistで指定 |
| hue_order | hueで指定したカテゴリの並び順をlistで指定 |
| color | グラフの色 |
In[]
1 2 3 4 5 | import seaborn as sns sns.set() sns.pointplot(x='No', y='negative', data=patient, color='orange') sns.pointplot(x='No', y='serious', data=patient, color='red') |
Out[]
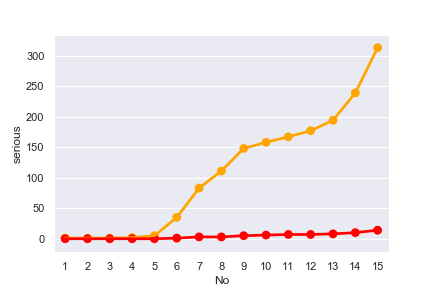
egative、seriousの数を折れ線グラフ
pointplot は $X$ 軸のカテゴリごとに $Y$ 軸の値をばらつきとともにみるグラフなので、素直に、matplotlibのplotメソッドを使ってもOKです。
In[]
1 2 3 4 | ax = plt.gca() ax.plot(patient['negative'].values) ax.plot(patient['serious'].values) plt.show |
Out[]
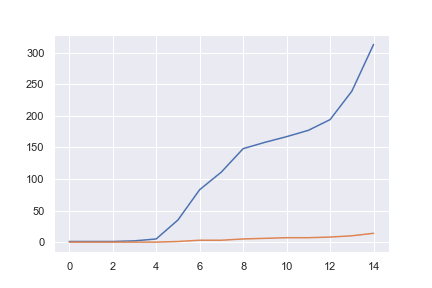
irisデータの相関係数をmatplotlibのplotメソッドで表示
グラフを複数表示する方法

pariplot
散布図の紹介では、sepal_width と sepal_length の関係のみを確認しましたが、一気に全部見ることができれば便利です。
seabornには、グラフを一気に複数表示してくれるメソッドがあります。
今回は、pairplotを使ってみます。
| data | 対象データ |
| hue | グルーピングする列名 |
| hue_orderlist | hueで指定したカテゴリの並び順をlistで指定 |
| vars | 対象のデータの列名をlistで指定 |
| kind | プロット種類。scatter or reg |
irisデータを全て渡して、speciesでグルーピングします。
In[]
1 2 3 4 5 | import seaborn as sns sns.set() iris = sns.load_dataset("iris") sns.pairplot(data=iris, hue="species") |
Out[]
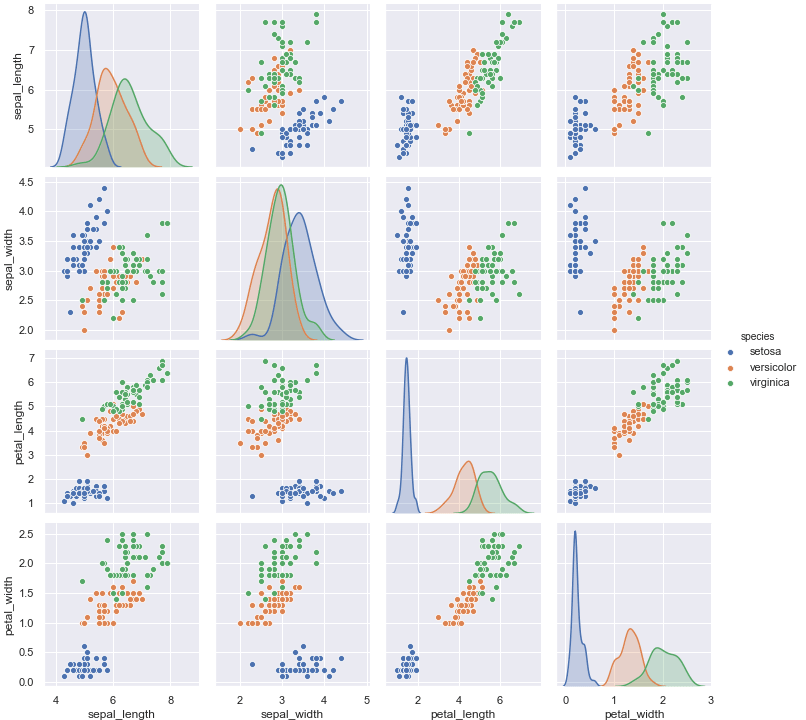
散布図を複数表示する
どうでしょう。一気にお互いの変数の相関関係と種別ごとのデータの分布の差がわかります。
しかも、使い方も簡単です。
Axes
matplotlibのAxesを使うことで、seabornでも複数のグラフを表示できます。
まず、plt.subplotsでグラフ表示するaxesを複数作ります。
In[]
1 | fig, axes = plt.subplots(行数, 列数, figsize=(幅, 高さ)) |
下記のようなイメージになります。
axesの中には列数、行数で指定した配列分axes(グラフ)が入っています。
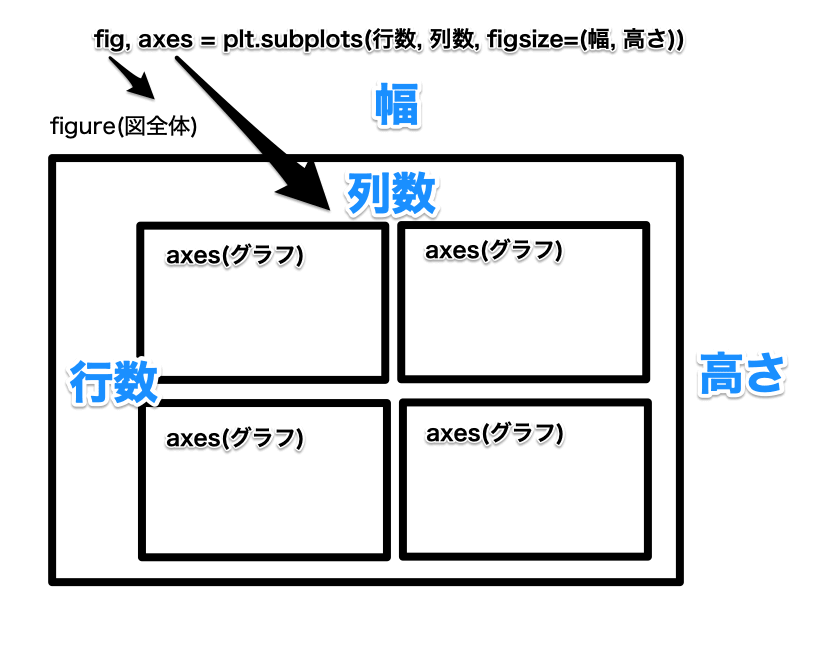
figureの列数、行数、幅、高さの関係
では、titanicで使った棒グラフを並べて表示してみましょう。
グラフの引数にax=axes[列No, 行No]を指定するだけです。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import seaborn as sns import matplotlib.pyplot as plt sns.set() titanic = sns.load_dataset("titanic") # subplots(行, 列, figsize=(幅, 高さ)) fig, axes = plt.subplots(2, 2, figsize=(15, 10)) sns.countplot(x='survived', data=titanic, ax=axes[0,0]) sns.countplot(x='survived', hue='class', data=titanic, ax=axes[0,1]) sns.barplot(x='class', y='survived', data=titanic, ax=axes[1,0]) sns.barplot(x='class', y='survived', hue='sex', data=titanic, ax=axes[1,1]) plt.savefig('seaborn_graph20') |
Out[]
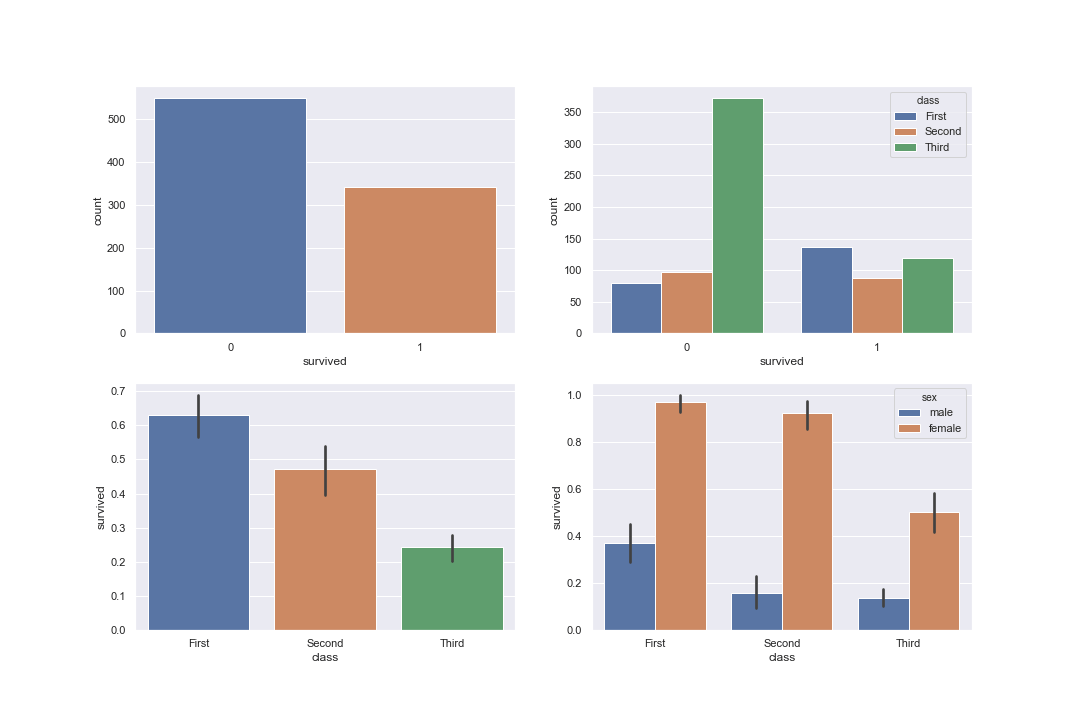
seabornで複数のグラフを表示
今回は以上となります。お疲れ様でした。
また、seabornについての課題を用意していますので、学習し終わった方は挑戦してみて下さい。
-

【Python】seabornの練習問題【Kaggleに挑戦】
続きを見る