
こんにちは。
産婦人科医で人工知能の研究をしているTommy(Twitter:@obgyntommy)です。
本記事ではPythonのライブラリの1つである pandas の計算処理について学習していきます。
pandasの使い方については、以下の記事にまとめていますので参照してください。
-

【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
データを取得したとき、そのまま使えるということはほとんどありません。
データの概要を知るために計算を行うこともありますし、機械学習で使うためには、データを計算して新しい特徴量を追加することもあります。
ここで本記事の学習到達目標です。
本記事の学習目標
- matplotlibの計算メソッドの修得
- 行・列・指定範囲の計算方法の修得
- 列同士の計算方法の修得
- pandasの算術メソッドの修得
- pandasのグループ化の方法
今回は、これらの計算がしっかりできるように習得していきましょう。
使用するデータのセッティングとseabornのインストール方法

本記事では、irisのデータを使って学習していきます。
irisのデータは scikit-learn もしくは seaborn のライブラリから得る事ができます。
seabornのライブラリでは pandasのDataFrameの形式でデータを取得できるので、今回はそのライブラリで取得したデータを使用します。
seabornをインストールする方法
早速seabornをインストールしましょう。
In[]
1 | pip install seaborn |
これを入力するだけで、seabornをインストールする事が出来ます。
データを読み込む方法
下記コードでデータを取得してください。
headメソッドでどういったデータか見ておきましょう。
In[]
1 2 3 | import seaborn as sns iris = sns.load_dataset("iris") iris.head() |
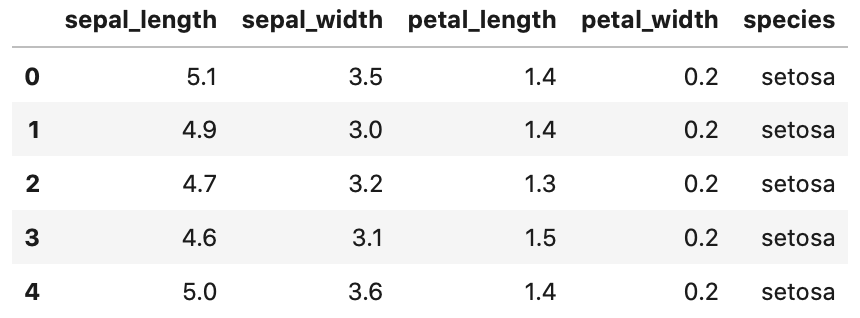
headメソッドで確認した、最初の5行のデータがこちらです。
Out[]
pandasの計算メソッド

pandasにはいくつか計算するためのメソッドが用意されています。
今回は、行や列に対して図のように合計や平均などを計算します。
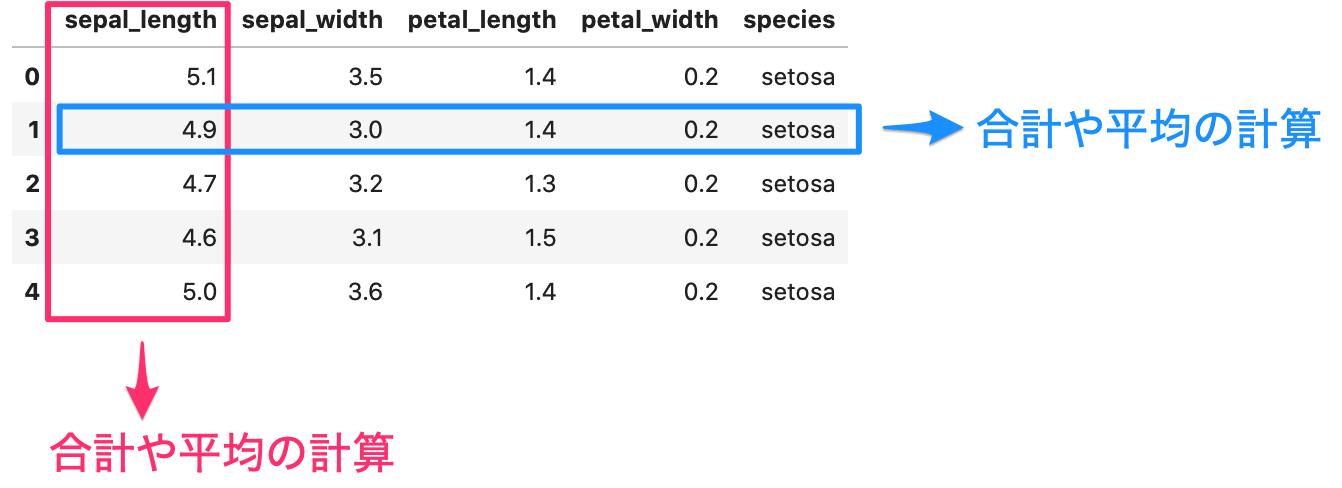
計算するメソッドの種類は下記の表になります。
sum(合計)
sumメソッドで合計を計算してみましょう。
パラメータに axis=0 (列), axis=1 (行)を与えることで、列か行の計算ができます。
パラメータを指定しない場合、初期値の 0 が使われて、列の合計になります。
In[]
1 | iris.sum() |
sumメソッドは数値は合計を計算しますが、文字データは連結します。
数値のみの計算をしたい場合は、パラメータに numeric_only=True と指定しましょう。
Out[]
1 2 3 4 5 6 | sepal_length 876.5 sepal_width 458.6 petal_length 563.7 petal_width 179.9 species setosasetosasetosasetosasetosasetosasetosaseto... dtype: object |
axis=1 を指定して、行方向の合計を算出してみましょう。
In[]
1 | iris.sum(axis=1) |
Out[]
1 2 3 4 5 6 7 8 9 10 11 12 | 0 10.2 1 9.5 2 9.4 3 9.4 4 10.2 ... 145 17.2 146 15.7 147 16.7 148 17.3 149 15.8 Length: 150, dtype: float64 |
次に、species (品種)の setosa だけで計算させてみましょう。
条件をつけてのデータの指定方法は、ここでは説明を簡単にしますが、iris [条件]とすることで、決まった条件のデータに絞れます。
ここでいう条件が iris[‘species’]==’setosa’ で、species 列の setosa と等しいものとなっています。
In[]
1 | iris[iris['species']=='setosa'].sum() |
Out[]
1 2 3 4 5 6 | sepal_length 250.3 sepal_width 171.4 petal_length 73.1 petal_width 12.3 species setosasetosasetosasetosasetosasetosasetosaseto... dtype: object |
他のメソッドも sum と同じなので、順にコードと結果を確認していきましょう。
mean(平均)
平均の計算をしてみましょう。
In[]
1 | iris.mean() |
Out[]
1 2 3 4 5 | sepal_length 5.843333 sepal_width 3.057333 petal_length 3.758000 petal_width 1.199333 dtype: float64 |
median(中央値)
中央値の計算をしてみましょう。
In[]
1 | iris.median() |
Out[]
1 2 3 4 5 | sepal_length 5.80 sepal_width 3.00 petal_length 4.35 petal_width 1.30 dtype: float64 |
max(最大値)
最大値の計算をしてみましょう。
In[]
1 | iris.max() |
文字列はアルファベット順で、最後尾のものが表示されています。
Out[]
1 2 3 4 5 6 | sepal_length 7.9 sepal_width 4.4 petal_length 6.9 petal_width 2.5 species virginica dtype: object |
min(最小値)
最小値の計算をしてみましょう。
In[]
1 | iris.min() |
文字列はアルファベット順の最初のものが表示されています。
Out[]
1 2 3 4 5 6 | sepal_length 4.3 sepal_width 2 petal_length 1 petal_width 0.1 species setosa dtype: object |
var(分散)
分散の計算をしてみましょう。
In[]
1 | iris.var() |
Out[]
1 2 3 4 5 | sepal_length 0.685694 sepal_width 0.189979 petal_length 3.116278 petal_width 0.581006 dtype: float64 |
std(標準偏差)
標準偏差の計算をしてみましょう。
In[]
1 | iris.std() |
Out[]
1 2 3 4 5 | sepal_length 0.685694 sepal_width 0.189979 petal_length 3.116278 petal_width 0.581006 dtype: float64 |
行、列、指定範囲の計算方法

次は、列や行の各データに対して計算をしていきます。
図のようなイメージになります。

または、下記図のような一部だけの計算です。
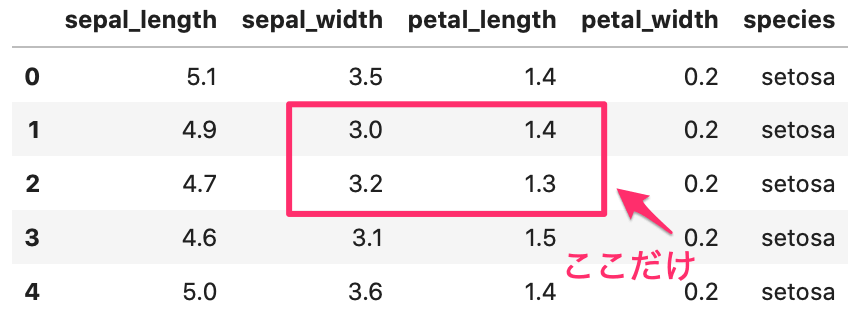
この列だけ、この範囲だけなどデータの範囲を指定して、その範囲に対して計算をします。
ブロードキャスト
pandas の計算も numpy 同様、ブロードキャストと呼ばれる考えがあります。
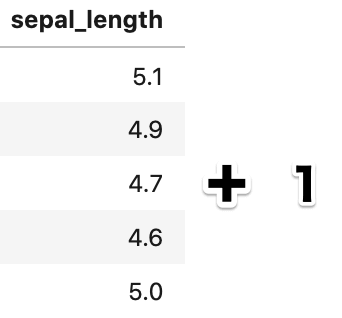
例えば、ある列にそれぞれ +1 をする計算をするとき、行数分の 1 を用意して足し算をする必要があります。
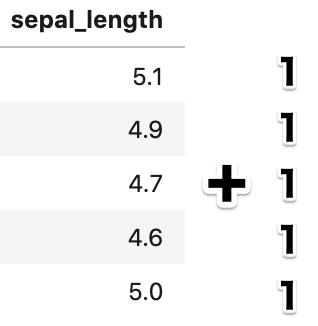
これでは、1 を足すたびに、行数分のデータを用意しなければいけませんが、これでは面倒です。
そのため、numpy や pandas にはブロードキャストと呼ばれる機能があり、
下記のように行数分のデータを用意しなくても、対象データ全部に対して、足し算などの計算ができるようになっています。
では実際に見ていきましょう。
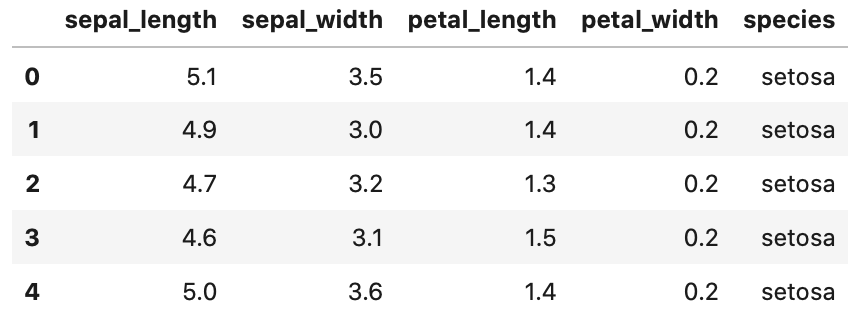
まずは、もう一度 headメソッド で最初の5列のデータを確認しましょう。
In[]
1 | iris.head() |
Out[]
四則演算
指定した、列やデータ範囲に対して、四則演算をすることができます。
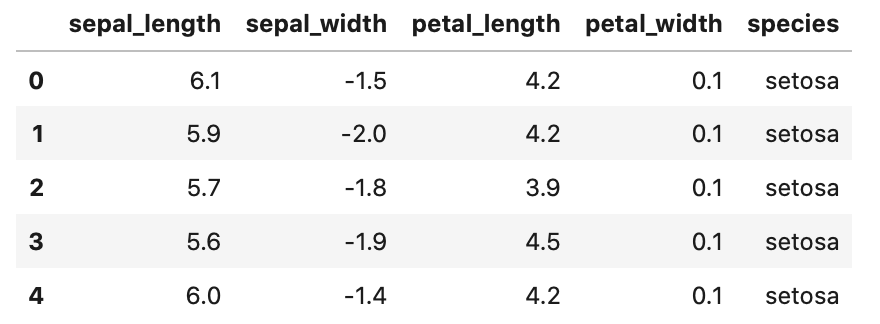
各列に下記の計算をしてみましょう。
sepal_lengthに+1sepal_widthに-5petal_lengthに*3petal_widthに/2
コードはこちらになります。
In[]
1 2 3 4 5 6 7 | iris['sepal_length']+=1 iris['sepal_width']-=5 iris['petal_length']*=3 iris['petal_width']/=2 # データ確認 iris.head() |
Out[]
こちらのコードでも同じ意味です。
1 2 3 4 | iris['sepal_length']=iris['sepal_length']+1 iris['sepal_width']=iris['sepal_width']-5 iris['petal_length']=iris['petal_length']*3 iris['petal_width']=iris['petal_width']/2 |
用途
この計算を何で使うんだろう?と思われた方もいるかもしれません。
機械学習などをする場合には、データを正規化、標準化といったことをします。
先ほど紹介した「計算メソッド」の mean や std の値と、今回の四則演算を使って計算することがあります。
行や指定範囲に対して、計算したい場合はどうすれば良いのか見ていきましょう。
データの範囲の仕方は色々ありますが、今回は iloc を使用します。
In[]
1 | iloc[開始行No: 終了行No, 開始列No:終了列No] |
1行目のデータを計算したいと思います。
列名の「species」は文字で計算できないので、1行目の4列目までを指定します。
In[]
1 2 3 4 5 | # データ読み直し iris = sns.load_dataset("iris") # 行データ指定 iris.iloc[0:1, 0:4] |
Out[]

ここで例えば、5を足してみましょう。
In[]
1 2 3 | iris.iloc[0:1, 0:4] += 5 # データ確認 iris.iloc[0:1, 0:4] |
Out[]

log(対数)
numpy のメソッドを使った計算もすることもできます。
sepal_width の値を log で計算してみましょう。
In[]
1 2 3 4 5 | import numpy as np iris['sepal_width'] = np.log(iris['sepal_width']) # データ確認 iris.head() |
Out[]
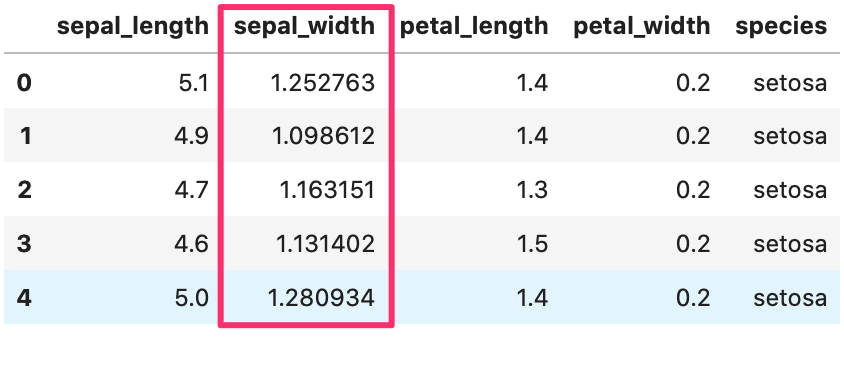
log の計算が行われていますね。
用途
log はデータの分布に偏りがあるときに、正規分布に近い分布にしたいときに使用します。
絶対値
絶対値を計算します。
今回使用するデータは負の値のものはないので、-1 を掛け算したものを使いましょう。
In[]
1 | -1*iris['sepal_width'] |
Out[]
1 2 3 4 5 6 | 0 -3.5 1 -3.0 2 -3.2 3 -3.1 4 -3.6 ... |
では、絶対値を計算しましょう。
numpy の abs メソッドを使います。
In[]
1 2 3 4 5 6 7 8 | # データ読み直し iris = sns.load_dataset("iris") import numpy as np iris['sepal_width'] = np.abs(-1*iris['sepal_width']) # データ確認 iris.head() |
きちんと絶対値になっているのが確認できますよね。
用途
線形回帰のロス計算とかで絶対値誤差算出などで使用します。
平方根
numpy の sqrt メソッドを使って、平方根を計算します。
In[]
1 2 3 4 5 6 7 8 | # データ読み直し iris = sns.load_dataset("iris") import numpy as np iris['sepal_width'] = np.sqrt(iris['sepal_width']) # データ確認 iris.head() |
Out[]
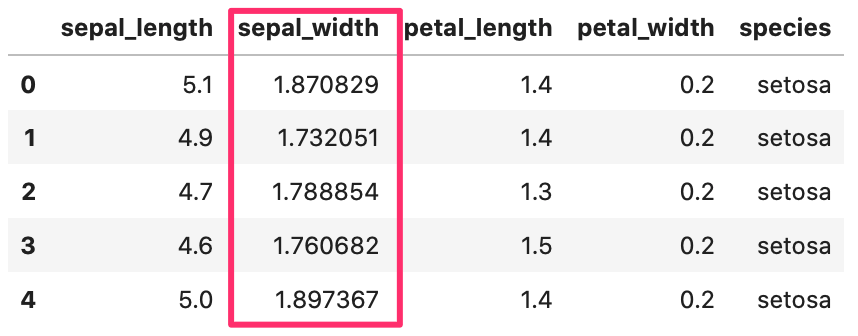
用途
ユークリッド距離の計算などで使います。
列同士で計算を行う方法

次は列同士の値を使って計算をしてみましょう。
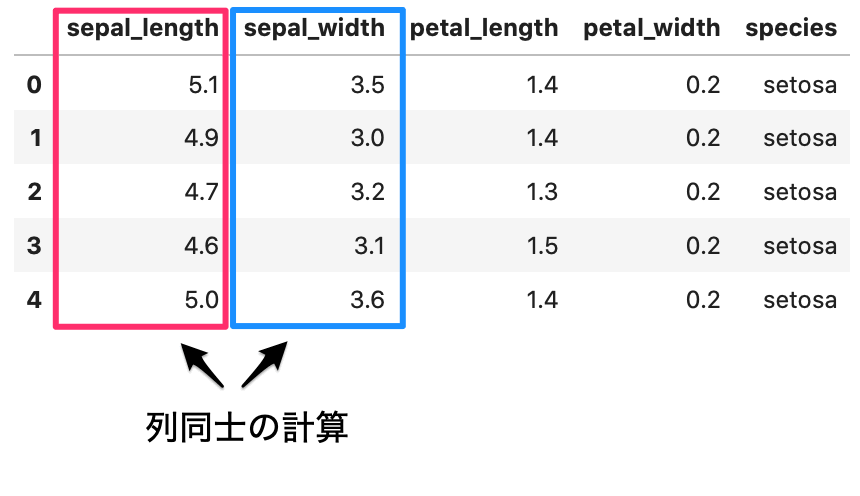
用途
列同士を計算することで、新しい特徴量を作ることが出来ます。
sepal の length と width を割って、sepal_ratio という列を作ってみましょう。
iris[‘列名’] = とすることで、新しい列が作られます。
In
1 2 3 4 5 6 7 | # データ読み直し iris = sns.load_dataset("iris") iris['sepal_ratio'] = iris['sepal_length'] / iris['sepal_width'] # データ確認 iris.head() |
Out[]
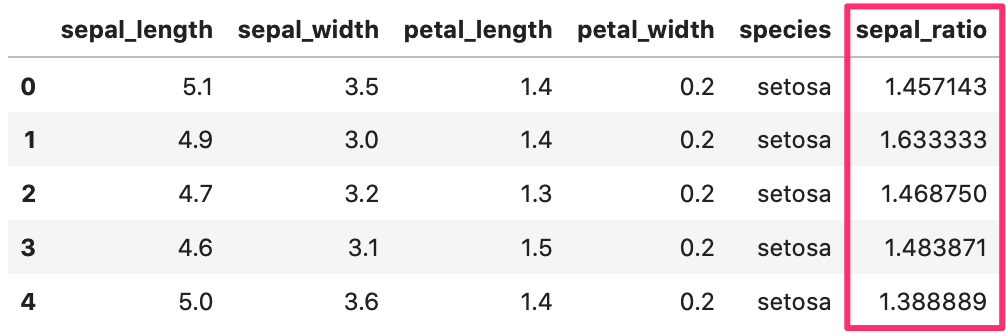
pandasの算術メソッド

pandasに用意されている、計算用のメソッドもあるので、紹介します。
メソッドには以下のものが用意されています。
| メソッド | 計算 |
| add | 足し算 |
| sub | 引き算 |
| div | 除算 |
| mul | 乗算 |
| mod | 剰余 |
| pow | べき乗 |
上記メソッドの基本的な使い方はそれぞれ同じなので、div(除算) についてピックアップして説明していきます。
1つの数値のみを計算する方法
sepal_length の全部の行に対して、divを使って、10で割ります。
In[]
1 2 3 4 5 6 7 | # データ読み直し iris = sns.load_dataset("iris") iris['sepal_length'] = iris['sepal_length'].div(10) # データ確認 iris.head() |
Out[]
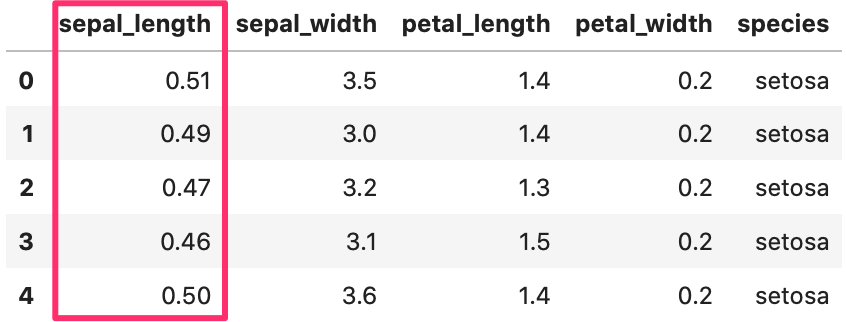
複数の値をまとめて計算する方法
sepal の length を10で割って、width を5で割ってみます。
DataFrameで2列を指定して、divメソッドには [10, 5] と2列分の数値を与えます。
In[]
1 2 3 4 5 6 7 | # データ読み直し iris = sns.load_dataset("iris") iris[['sepal_length', 'sepal_width']] = iris[['sepal_length', 'sepal_width']].div([10, 5]) # データ確認 iris.head() |
Out[]
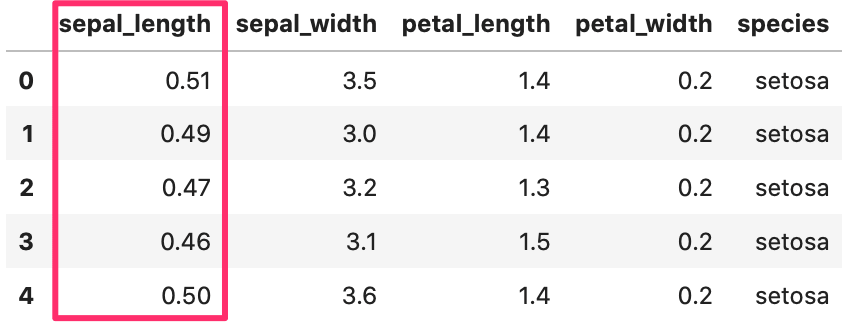
列データを計算
divメソッドには列のデータを渡すこともできます。
「列同士の計算」で紹介したことと同じ計算を div メソッドを使ってやってみます。
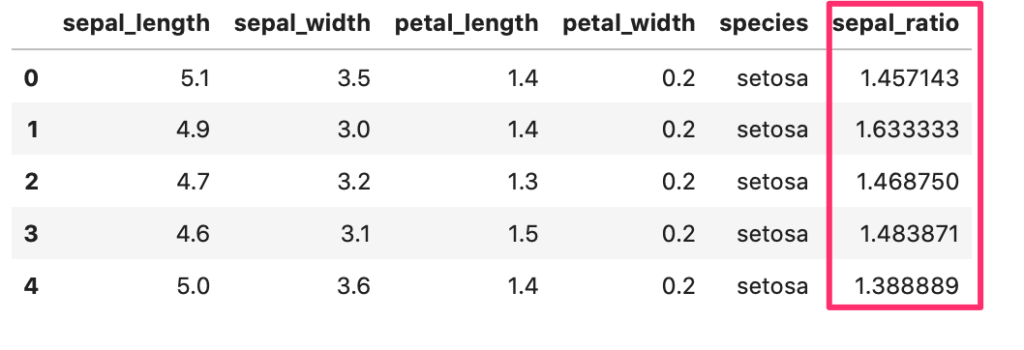
sepal_length 列からdivメソッドを使って、引数に sepal_width の列のデータを与えます。
新しい値は、sepal_ratio として新しい列に入れます。
In[]
1 2 3 4 5 6 7 | # データ読み直し iris = sns.load_dataset("iris") iris['sepal_ratio'] = iris['sepal_length'].div(iris['sepal_width']) # データ確認 iris.head() |
Out[]
applyを使った計算方法

applyメソッドを使うと、処理したい関数を作って、その関数で処理することができます。
公式の applyメソッド の案内は以下になります。
-
pandas.DataFrame.apply — pandas 3.0.2 documentation
続きを見る

species の文字列の列を setosa:1 、versicolour:2 、virginica:3 としてみましょう。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # データ読み直し iris = sns.load_dataset("iris") # species列を文字列から1,2,3に変換する関数 def func_sample(x): ret = 0 if x=='setosa': ret = 1 elif x=='versicolour': ret = 2 elif x=='virginica': ret = 3 return ret iris['species'] = iris['species'].apply(func_sample) # データ確認 iris.head() |
Out[]
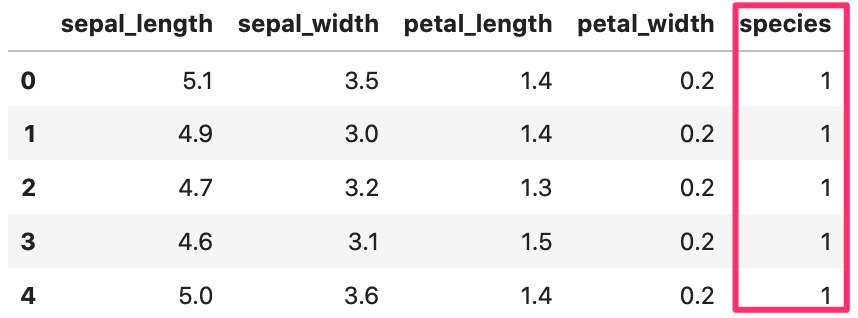
func_sample(x) の x には指定した範囲のデータ(今回は species 列のデータ)が順番に入ってきて、処理されます。
pandasでグループ化を行う方法

pandas は groupbyメソッド で、カテゴリごとにグループに分けて計算することができます。
最初の「計算メソッド」で各列の合計などを計算しました。
品種ごとで計算したい場合には、条件 species==’setosa’ と指定して、計算しても良いのですが、groupby で分ける方法も見ていきましょう。
groupby でグループ化する
irisデータを species でグループ化してみましょう。
In[]
1 2 3 4 5 6 7 | # データ読み直し iris = sns.load_dataset("iris") iris_group = iris.groupby('species') # 型の確認 type(iris_group) |
DataFrame が DataFrameGroupBy となりました。
これを使って、計算していきます。
グループ化後の計算例
「計算メソッド」で説明した、メソッドと同じです。
mean で平均を見てみましょう。
In[]
1 | iris_group.mean() |
Out[]
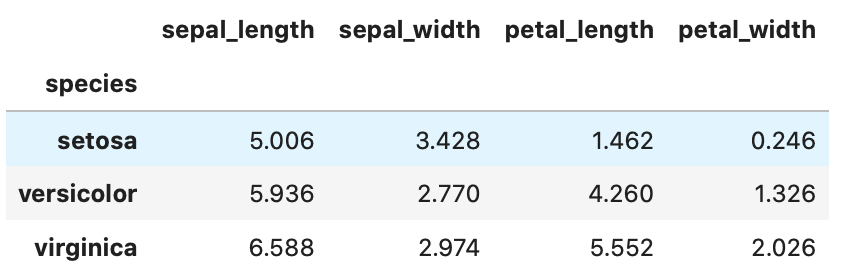
上記の様な結果になりましたでしょうか。
簡単に、品種ごとの平均値が出す事が出来ましたね。
他にも、std など以下の「計算メソッド」で紹介したメソッドも試してみてください。
また、pandas の使用方法については以下の記事にまとめています。一通りpandasの使い方を学習できた方は再度復習してみましょう。
-
【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る