
こんにちは。
今回は機械学習アルゴリズ(予測モデル)の作成を行う際に最初にやるべき事となる、データの準備の方法【手順】の解説を行います。
データの題材として「プロ野球選手の年俸の予測」を使って行いましょう。
プロ野手の成績のデータをインポートし、データに含まれている項目から、データ翌年の年俸を予測するモデルを作ります。
仮定するモデルは、「野手の前年度の成績により、翌年の年俸を予測する」モデルです。
さらに具体的には、プロ野球データから必要なデータを抽出して、2017年シーズンでの年俸からと2018年の年俸を推定します。
では早速行ってみましょう。
プロ野球選手の年俸予測の事前準備

早速プロ野球選手の年俸予測を行うための事前準備を行なって見ましょう。プロ野球データFreakより必要なラベルのデータを抽出してデータを揃え、csv形式のファイルで保存します。保存したcsvファイルの名前を baseball.csv としています。
baseball.csv のファイルをjupyter notebookにアップロードしましょう。
自身で演習を行うjupyter notebookと同じフォルダに保存する様にして下さい。
なお、データ分析を行う際にはPythonでデータサイエンスを参考にすると非常に分かりやすかったです。
またこのサイトの他にもプロ野球選手の年俸の推定を行なっているサイトがありましたので、参考にして頂ければと思います。
» 【Qitta】Pythonでデータ分析やってみた(ピッチャーの年俸は何で決まるか)
機械学習に置いてもっとも重要なことはこのデータ作成の部分です。コードを記載する箇所はほとんど慣れの様なものがあるので、機械的に進んでいきますが、データがおかしいとスムーズに進みません。
データ作成を行う際のラベルの項目やデータの調整の仕方、データの数値化について下準備を行うことが重要です。
プロ野球選手の年俸を予測【手順あり】

では早速具体的なコードをjupyter notebook上に記載していきましょう。以下の手順で進めていきます。
ライブラリ・データをjupyter notebookにインポートする
まず必要なライブラリをインポートしていきます。
必要なライブラリの一覧まとめです。
pandas: 表を操作するためのライブラリnumpy: 数列を計算するためのライブラリmatplotlib: グラフを描画するためのライブラリ
ということで、これらのライブラリをインポートしましょう。
In[]
1 2 3 | import numpy as np import matplotlib.pyplot as plt import pandas as pd |
次にグラフを表示させるために以下の記述を加えます。
In[]
1 | %matplotlib inline |
これでライブラリはインポートされて揃いました。次にデータのインポートを行います。
関数であるpd.read_csv()を使用して、ファイルbaseball.csvから表を読み込みます。
» 【Python】オブジェクト指向プログラミングの基本【分かりやすく解説】
1 | baseball_dataset = pd.read_csv("baseball.csv") |
続いてdataset.head()で、データセットの最初5行を表示させます。すると以下の様に表示されます。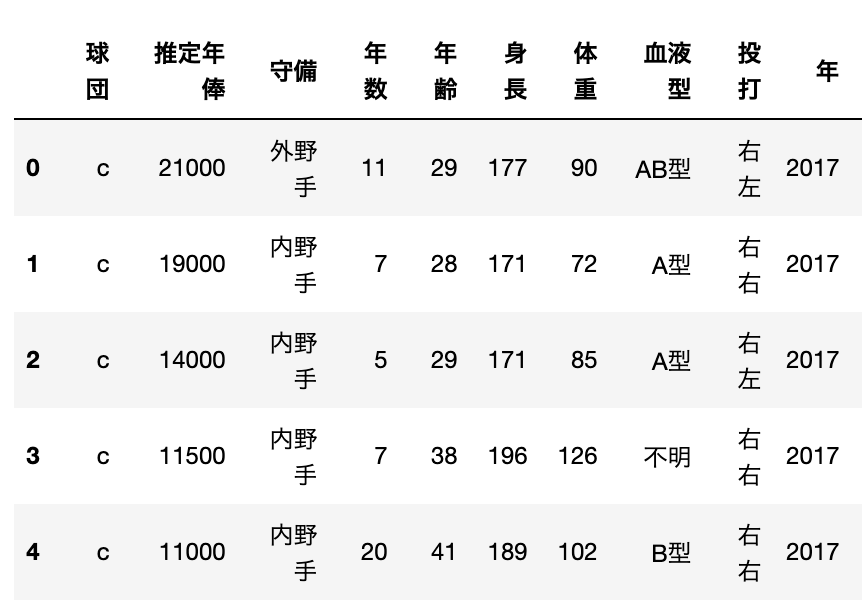
データ収集の際に必要なラベル(項目)はもちろん、作成されたデータによって異なります。
皆さんのデータはどの様に表示されましたでしょうか。
野球選手の打点と年俸の関係を可視化する

それでは、野球選手の年俸に相関関係がありそうな特徴量を抽出してみましょう。
代表的な特徴量としては「打点」などがありますので、以下の手順で「打点」と「推定年俸」の関係をグラフにしてみましょう。
打点と推定年俸の関係性をグラフ化する。
打点の値はdataset_baseball["打点"]、というように、するとオブジェクトを取得することができます。
辞書の扱い方については以下の記事を参照にして下さい。
またnp.array()で、表から「打点」と「推定年俸」のデータを配列として抽出します。
In[]
1 2 | baseball_points = np.array(baseball_dataset["打点"]) baseball_salary = np.array(baseball_dataset["推定年俸"]) |
次に、野球選手の「打点」を $x$ 軸、推定年俸を $y$ 軸となるように、plt.plot()を使用して散布図として描きます。
以下の入力で可能です。この際に plt.plot() の使用方法ですが、引数の() の中には plt.plot($x$, $y$, '色.') として記入します。'r. ' は赤色の r です。
In[]
1 2 3 4 5 6 | fig = plt.figure() plt.plot(baseball_points, baseball_salary, 'r.') plt.xlabel("Points") plt.ylabel("Salary") fig.savefig("images/baseball_points_vs_baseball_salary_scatter.png") plt.show() |
※ .savefig は作成した図をbaseball_points_vs_baseball_salary_scatter.pngという名前でimagesフォルダに保存する と言う意味があります。
※ .savefig については公式サイトを公式にしてみましょう。
※ このコードの流れは【Qiita】matplotlibで作成したプロットを画像ファイルに保存する方法にも記載されていますので、併せて参考にしてください。
ここで、描かれた散布図を表してみます。この様に描図されました。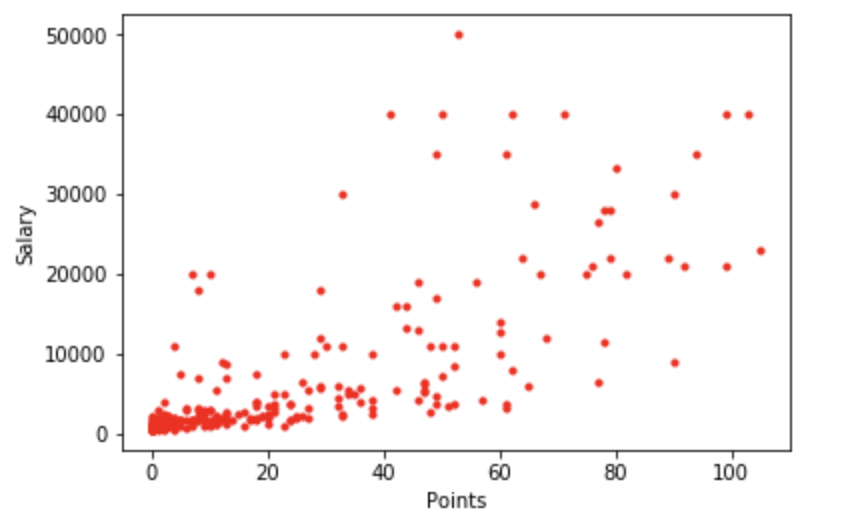
綺麗な散布図として描図する事ができました。皆さんは如何でしょうか。
まとめ:Pythonで野球選手の年俸を推定してみる

今回は機械学習のアルゴリズム(予測モデル)を作成する際に置いて最も初期に行う必要がある「データの準備」に関する解説を行いました。
さらに少し踏み込んでデータの可視化まで行いました。
描図された散布図空は野球選手の打点と年俸には何らかの関係がありそうな事が分かりますが、本来であればデータを準備した後にはデータの可視化を行う前にデータの前処理を行う必要があります。
今回は試しにデータの可視化までの解説を行いました。
この部分については以下の記事で紹介しています。
-

機械学習のためのデータの前処理の方法を詳しく解説【手順あり】
続きを見る
データの準備が完了したら次回がデータの前処理、モデル作成と続きます。