
こんにちは。産婦人科医のとみー(Twitter:@obgyntommy)といいます。
私はふだんは産婦人科の臨床に携わりつつ、画像系の機械学習の研究をしています。
研究の過程で「説明可能なAI」について学習し、"LIMEやSHAP"について使い方や実装方法などをまとめました。
以下に「説明可能なAI」について分かりやすい記事がありましたので、ご紹介させて頂きます。
説明可能なAIとは、米国のDARPAの研究が発端の概念で、モデルの予測が人間に理解可能であり、十分信頼に足る技術、またはそれに関する研究のことを指します。
たとえば医療業界のように、診断の理由を患者さんに説明しなけらばならない場合には、説明可能で解釈性の高いモデルが必要です。このような業界にもAIの導入が進み始めている近年、説明可能なAIの必要性も増してきています。
そんななか、2019年11月21日にGoogleも「Explainable AI(外部サイト)」というツールを発表しました。そこで、本稿ではそもそも説明可能なAIとは何なのかを概観した後、GoogleのExplainable AIに触れながら、Googleがどのように説明可能なAIを実現しようとしているのか見ていきたいと思います。
そもそもAIのには「ブラックボックス性」というものが指摘されています。
機械学習ではこれまでに公開してきた記事のように、内部での計算過程を可視化することができます。
一方で、ブラックボックス性というのは文字通り、内部の構造や処理の過程が不明な装置や仕組みとなります。
AIのブラックボックス性という言葉が使われる理由としては、機械学習モデルの内部で行っている計算が非常に複雑でシンプルには理解することが難しいからと思われます。
そのため、機械学習の際の複雑な計算を(直感的な)解釈ができるような形にすることができれば「AIのブラックボックス性」解消につながるだろうという考えです。
これを実現するための仕組みが「説明可能なAI」です。
なお、この記事の対象者は機械学習の初学者〜中級者の方です。
そのため、前線で活躍されている方には有益ではありません。
この記事では、まずは説明可能なAIについて簡単に理解して頂き、次に実際にどの様な例で使用するのかということをGoogle Colaboratoryで手を動かして頂ければ幸いです。
Google Colaboratoryの使い方は以下の記事でまとめています。
-

Google Colaboratoryの使い方【完全マニュアル】
続きを見る
また、実際にLIMEやshapをGoogle Colaboratoryで行った試行例は以下になります。実際にPythonのコードを動かして頂く事も可能です。
-
Google Colab
続きを見る

誤りがあった場合にはお問い合わせフォームにまでご連絡いただけましたら幸いです。
こちらのスライドに沿って解説させて頂きます。
LIMEとSHAPを用いた具体的な実装方法について
この章から、LIMEやSHAPを用いて、実際の細胞画像対してセグメンテーションを行う流れを解説させて頂きます。
この記事で扱うデータセットは、乳がん患者から採取した細胞の情報(半径や滑らかさ)から悪性なのか良性なのかを判断するためのデータセットになります。
実装の流れとしては、ネット上でも良く取り扱われている他のチュートリアルとほぼ同様に、以下の流れで進めます。
実装の流れ
- データセットの読み込みと内容確認
- データの前処理
- 機会学習モデルの作成
- LIME, SHPを用いた解釈性(特徴量影響度)の確認
- LIMEを用いた特徴量影響度の確認
- SHPを用いた特徴量影響度の確認
また、画像のアップロードや画像の処理やモデルのトレーニングを行う際に長い時間を要しますので、十分な時間を確保した上で以下を実行お願いします。(実際に、以下のコード実行は2時間ほどかかりました。)
また、モデルのトレーニングを行う場合はGPUの使用をお勧めします。
Google Colabを使う場合は上部『ランタイム』タブから『ランタイムのタイプを変更』を選択し、ハードウェアアクセラレータをGPUに変更をお願いします。
breast cancerデータセットの読み込みと内容確認
skleanのライブラリから「breast cancer」のデータセットを読み込みます。
breast cancerのデータセットは乳がん患者から採取した細胞の情報(半径や滑らかさ)から悪性なのか良性なのかを判断するためのデータセットになります。
breast cancerデータセットの中身を確認します。
In[]
1 2 3 | from sklearn.datasets import load_breast_cancer data_breast_cancer = load_breast_cancer() data_breast_cancer |
Out[]
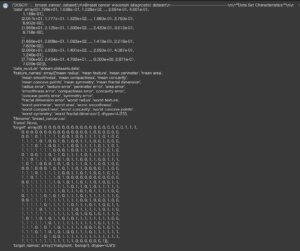
このデータセットの中身はpythonの辞書型になっていますので、取得したい対象のキーを以下のように指定することによって、対象の中身(バリュー)を取得できます。
以下のコードでは正解ラベルの取得を行なっています。
In[]
1 | data_breast_cancer["target"] |
Out[]
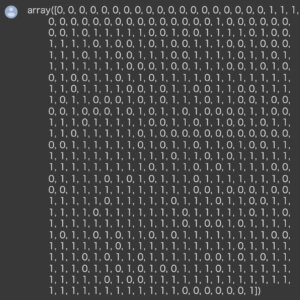
データの前処理
次に $X$ を特徴量、$y$ を正解ラベルとし前処理を行なっていきます。
まずは正解ラベルの前処理を行います。元のデータは0, 1という整数型のデータになっています。0はmalignantで悪性、1はbenignで良性となります。
上のデータをデータフレーム化します。
In[]
1 2 3 | import pandas as pd y_all = pd.DataFrame(data_breast_cancer["target"],columns=["target"]) y_all.head() |
Out[]
続いて、特徴量の前処理を行います。特徴量の名前は feature_names 、値はdataキーに含まれていますのでそれを用います。
In[]
1 2 | X_all = pd.DataFrame(data_breast_cancer["data"],columns=data_breast_cancer["feature_names"])d X_all.head() |
Out[]

続いて、全てのデータを学習用と評価用に分割します。これにはsklearnの train_test_split メソッドを使います。
学習用データと評価用データの数の割合ですが、今回は2:1とします。
※ 2:1でなければならないというわけではなく、一般的には評価用データ数が全体の2-4割程度にすることが多いです。
In[]
1 2 | from sklearn.model_selection import train_test_split X_train, X_eval, y_train, y_eval = train_test_split(X_all, y_all, test_size=0.33, random_state=0) |
以上で学習用、評価用データセットの作成のための前処理が完了しました。
機械学習モデルの作成
続いて機械学習モデルの作成をしていきましょう。今回は高精度であり逆にモデル自体では解釈困難な xgboost というアルゴリズムを使います。
In[]
1 | import xgboost as xgb |
続いてモデルの学習を行います。
今回はハイパーパラメータチューニングの過程は省略します。
今回は2値分類問題でありますので、objectibeは' binary:logistic '、モデルのタイプはClassifierになります。 評価指標はAUCを設定しておきます。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | watchlist = [(X_train.values, y_train.values.ravel()), (X_eval.values, y_eval.values.ravel())] xgb_classifier = xgb.XGBClassifier( objectibe='binary:logistic', learning_rate=0.01, reg_lambda=0.5, reg_alpha=0.5, colsample_bytree=0.8, subsample=0.8) xgb_classifier.fit( X_train.values, y_train.values.ravel(), eval_metric='auc', early_stopping_rounds=100, verbose=10, eval_set=watchlist,) |
Out[]
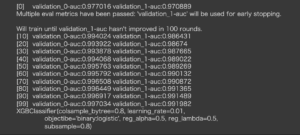
トレーニングが終了しました。
評価データにおいてAUCが0.99ほどになっているので、とても高い分類予測性能があるモデルと見なせるかと思います。
注意点
※ 注意点として、特徴量の影響度の解釈を行う場合はモデルの予測性能が十分高いことを事前に確認してください。特に予測性能が低いモデルで解釈を行うと、間違った示唆をしてしまうリスクがあります。
LIME,shapを用いた解釈性(特徴量影響度)の確認
それでは以上で作成した機械学習モデルの予測結果の解釈をLIME,shap2つの方法で行っていきましょう。
LIMEを用いた特徴量影響度の確認
それではまずLIMEによる特徴量重要度の確認から行っていきましょう。
LIMEはpythonにはライブラリが用意されておりますので、そちらを使って確認をしていきます。まずはライブラリのインストールを行います。
In[]
1 | !pip install lime |
Out[]
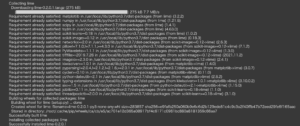
続いてどのデータ点に対して解釈を行うか決定する必要があります。
今回は評価データ X_eval の5番目のデータ(インデックス=4)に対して解釈を行うことにします。
In[]
1 2 3 | index = 4 df_target = X_eval.iloc[index,:] df_target |
Out[]
続いてLimeのライブラリを使っていきましょう。
典型的な使い方としては lime.lime_tabular.LimeTabularExplainer で explainer というインスタンスを作成します。
discretize_continuous という引数について説明しておきます。
デフォルトは True で True の場合はすべての非カテゴリ機能は四分位数に離散化されます。
これにより連続値の大小を比較しやすくできます。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 | import lime import lime.lime_tabular explainer = lime.lime_tabular.LimeTabularExplainer( X_train.values, mode='classification', feature_names=X_train.columns, class_names=['malignant', 'benign'], verbose=True, discretize_continuous=True ) |
続いて、上で指定したデータ点を入力しLIMEによる特徴量の影響度の出力を行います。
引数に xgb_classifier.predict_proba とありますが、これは先ほど作成したモデルの予測を確率値で出力する関数になります。
num_features は影響度の高い特徴量をいくつ表示させるかを指定しています。
In[]
1 2 | exp = explainer.explain_instance(df_target.values, xgb_classifier.predict_proba, num_features=30) exp.show_in_notebook() |
Out[]
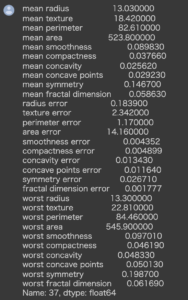
Interceptは回帰式での切片の値です。
Prediction_local は近似したLIMEのモデルの予測値、Rightは xgboost の予測値になります。
中央図の文字が切れてしまっているので,これを以下のようにリストで表示することができます。
In[]
1 | exp.as_list() |
Out[]
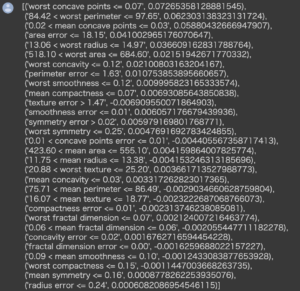
中央図は影響度の高い特徴量順に上から並んでおり、値はその特徴量が予測結果をどれだけ押し上げたか(押し下げたか)を示しています。
例えばworst concave pointsは0.07結果を良性に向けて押し上げているとみなすことができます。
これにより定量的に特徴量がどの程度結果に影響を及ぼしているかの解釈が出来ています。
補足ですが、以下のように先ほどの切片の値とすべての特徴量の影響度合いを全て足すことによって、近似したLIMEのモデルの予測値と合致することが分かります。
In[]
1 | sum([x for _,x in exp.as_list()])+0.4816 |
Out[]
1 | 0.8314487218210884 |
SHAPを用いた特徴量影響度の確認
それでは今度はSHAPによる特徴量の影響度の確認をします。
SHAPもpythonにはライブラリが用意されておりますので、そちらを使って確認をしていきます。まずはライブラリのインストールを行います。
In[]
1 | !pip install shap |
Out[]

まず TreeExplainer というクラスに対し先ほど作成した分類モデルを入力しインスタンスを作成します。
そのインスタンス( explainer )にSHAP値を算出したいデータを入力することによってSHAP値を算出することができます。
In[]
1 2 3 4 5 | import shap shap.initjs() explainer = shap.TreeExplainer(model=xgb_classifier) shap_values = explainer.shap_values(X=df_target) |
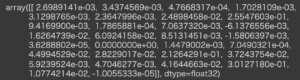
算出されたSHAP値を確認しましょう。
In[]
1 | shap_values |
Out[]
shapライブラリには summary_plot という可視化機能がありますので、そちらを使ってみます。
In[]
1 | shap.summary_plot(shap_values, feature_names=df_target.index) |
Out[]
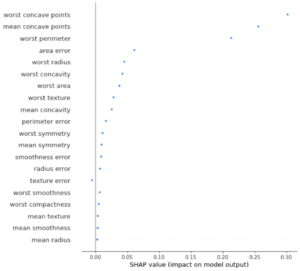
上から影響度が高い特徴量が並んでいます。
また force_plot という機能で影響度の高い特徴量を数個ならべて予測値がどう動いたかを可視化できます。
In[]
1 2 3 4 5 | shap.initjs() shap.force_plot(base_value=explainer.expected_value, shap_values=shap_values, features=df_target.index ) |
Out[]

まとめ
SHAPの場合もworst concave pointsが予測結果に大きく影響を及ぼしていることが分かります。
その次のmean concave points,worst perimeterですが、LIMEの順番と異なっています。
これはLIMEとshapで手法が異なっているためであり、どちらの手法が正しいというよりかは、どちらの特徴量も比較的影響度が高いとみなして評価を行うのがよいと思います。
補足
以上のSHAP値はシグモイド関数にかける前の値に対して算出されています。
よって、SHAP値に対してはシグモイド関数をかけることにより予測値に変換できます。
以上LIMEとSHAPでいつものデータセットで実装してみました。