

臨床研究のデザインの組み方がわからない。
機械学習を用いた診断方法・ソフトウェアを開発出来そうです。これからソフトウェアの診断法の性能を評価するための臨床試験を行いたいけど、どの様に進めて行けば良いのかわからない。
この記事の題名は「機械学習を用いた診断法についての臨床研究の進め方。」
としていますが、ここでいう「機械学習を用いた診断法についての臨床研究」とは、「機械学習を用いて開発した診断ツールの精度を評価する臨床研究」を意味しています。
そのため特に、これから機械学習を用いた診断ツールの開発を検討されている研究者や先生方、医療関係者に有用な記事になっています。
しかしこの記事は、診断法のための臨床研究を行うにはどの様なステップを踏めば良いのかをベースにまとめています。
そのため、機械学習を用いて開発した診断ツールの精度を評価するための臨床試験のためだけではなく、これから診断法についての臨床試験を行いたい、という臨床試験の初心者の方でも十分に参考になる内容になっていると思います。
では早速見ていきましょう。
機械学習を用いた診断法についての臨床研究の進め方【手順ありで解説】

機械学習を用いた診断法のための臨床研究の原理原則を考える【優れた診断方法とは何か】
まず、優れた診断方法とは何か、ということについて考えてみましょう。
優れた診断法とは、「患者さんに必要な医療的介入=アクションを起こすために有用な情報を例供してくれる診断法」と言えます。
例えば、緊急処置を要したり、稀な疾患、技術や経験を要して診断する疾患について、開発したある診断法の結果が「この診断が難しい診断である可能性が非常に高い」と示した場合にはこの診断法は「非常に優秀な診断法」と言えます。
研究において重要な事は、評価する疾患を有する可能性が高い、もしくは低いと判断してくれる評価法は非常に価値が高い、という点です。
また、疾患を有する可能性は確率として表現する事ができ、診断法の優劣を数値で客観的に評価する事ができます。
以下、「診断法を評価する」からの一部引用となります。
診断法評価の原理
- 「疾患を有するかどうか」100%正しい解答は分からない。
- そこで、現時点でもっとも確率の高い診断法をゴールド・スタンダード(以下続く)
- すなわち正確度の高い診断法を基準としてその結果と照らし合わせる。
臨床研究を行う上で、非常に有用な書籍があります。
僕自身もこの書籍を購入して、機械学習についての診断法を用いた臨床研究の取り組みを始めました。
「診断法を評価する」という書籍は診断法の研究について書かれた、非常に分かりやすい教科書ですので、これから診断法の臨床試験を行いたい方は一冊持っていて損はありません。
診断法の評価の仕方について
陽性・陰性などの結果として表現される診断法は感度・特異度
診断法のもっとも基本的な評価方法は「感度・特異度」です。
ここで、基本的な感度特異度の復習です。
- 「感度」:疾患のある人をどれだけ漏らさずに拾い上げれるかを示す指標
- 「特異度」:疾患のない人をどれだけ除くことができるかを示す指標
疾患を有するかどうかの100%確実に正しい指標は分からないため、ゴールデンスタンダードを設定する必要があります。
ゴールデンスタンダードを設定することで、ゴールデンスタンダードとなる診断方法の結果が100%正しいと解釈した上で、自身の診断方法と比較することができるからです。
ある診断方法の感度・特異度を求める場合には、以下の表のように特定の集団全員に対して、その診断方法とゴールデンスタンダードの診断方法の両方を行うことによって、両方の結果を照らし合わせます。
| ゴールデンスタンダード | |||
| 陽性 | 陰性 | ||
| 診断方法 | 陽性 | $x$ | $y$ |
| 陰性 | $z$ | $w$ | |
感度:疾患がある人の内、検査が陽性であった人の割合: $x/x+z$
特異度:疾患がない人の内、検査が陰性であった人の割合:$y/y+w$
ここで重要なことは、ゴールデンスタンダードの結果を100%正しい診断と解釈するということです。
感度・特異度を求める上での注意点
感度・特異度を求める上での注意点①
感度特異度を求める上での注意点のうちの一つに「標的集団(target population)」を決めて、その中からサンプリングを行う。
ということがあります。
例えば、一般健診で用いるレントゲン画像のスクリーニングのための「機械学習を用いたレントゲンを用いた診断支援ソフトウェアの開発」、という臨床研究を行いたいとします。
その際に、●●病院に通院中の500人に対してレントゲン撮影と、またそのソフトウェアを用いた検査を施行したとします。
しかしこの場合、問題があります。
一般健診の集団と●●病院に通院中の患者は異なる集団なわけです。
このために内的妥当性と外的妥当性に問題が出てきます。
- 内的妥当性:偏った結果になる
- 外的妥当性:一般健診に適用できない
一般健診からサンプリング(データを取り出す)した場合と、●●病院からサンプリングした場合には、異なる集団からサンプリングすることになるため、偏った結果が出てしまう可能性があるわけです。
このことを内的妥当性に問題を生じる、とかスペクトラムバイアス、と言います。これらのバイアスは選択バイアスに含まれます。
感度・特異度を求める上での注意点②
感度特異度を求める上での注意点として「対象者全員に対して、評価したい目的の診断法とゴールド・スタンダードの行う必要がある」ということです。
もし、ゴールド・スタンダードの検査を全ての対象者で行わない場合には結果に偏りが出てきてしまいます。
このバイアスのことを確認バイアス・または精査バイアスと言います。
結果が連続変数などの数値で得られる診断法はROC曲線・尤度比・層別尤度比で評価する。
陽性か陰性か、など2つに1つの結果が得られるものに対する診断法の評価には感度・特異度が評価方法が適しています。
しかし、数値など連続変数が結果として表される場合にはカットオフ値を用いて、カットオフ値よりも高い場合には陽性、カットオフ値よりも低い場合には陰性として、感度・特異度を用います。
カットオフ値を変えながら、その都度感度特異度を求めて両者の値をグラフ上にプロットして得られる曲線をROC曲線(receiver operator characteristic curve)と言います。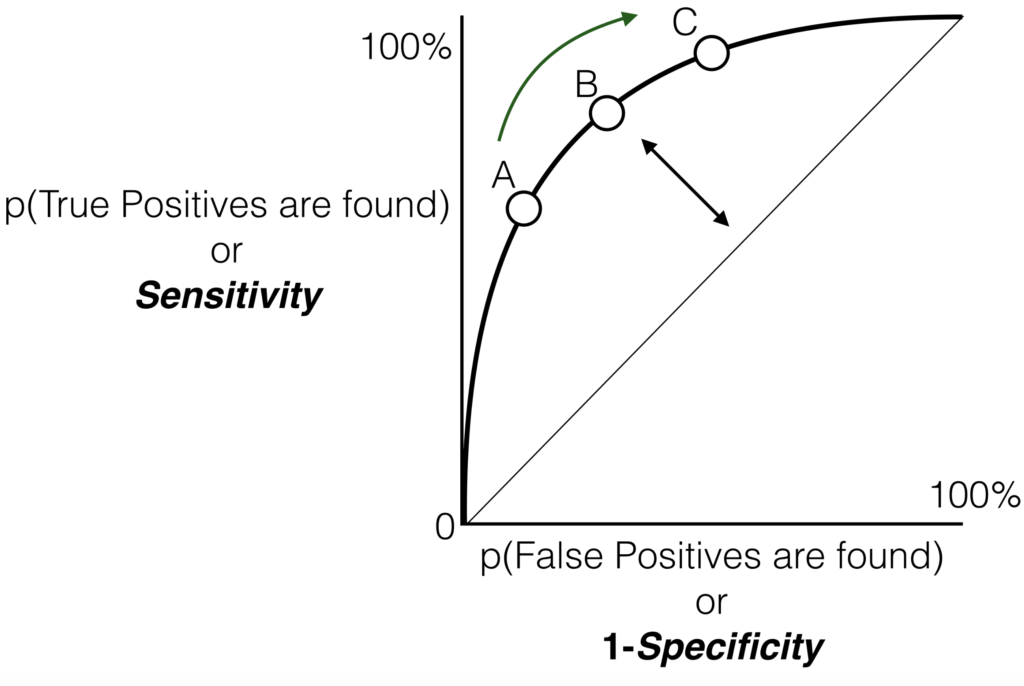 » Wikipedia 受信者操作特性( Receiver Operating Characteristic, ROC)より引用
» Wikipedia 受信者操作特性( Receiver Operating Characteristic, ROC)より引用
ROC曲線の下の部分の面積の大きさで診断法の識別能力を比較することができます。
大阪大学老年・腎臓内科のホームページではROC曲線についてわかりやすくまとめていますので、非常に参考になります。
尤度比・層別尤度比について
その他、出た結果のデータが連続変数である場合には、尤度比(likelihood ration(LR))や層別尤度比(カテゴリー別尤度比)の2種類があります。
これらの内容については少し難しくなり、書籍の「診断法を評価する」 で非常に詳しく記載されていますので確認してください。
診断法における臨床研究のポイント

機械学習によって開発された診断支援ツールだけではなく、全ての診断法の臨床試験にはポイントがあります。
臨床試験のデザインを考える際には、以下の点に留意しましょう。
診断に関する臨床研究のポイント
- 対象集団
- 目的検査
- ゴールデンスタンダード(至適基準)
- 診断性能
これらの内容について一つ一つ吟味していきましょう。
対象集団
機械学習であったとしても、臨床研究を行う上では対象集団の設定を明確にしておく必要があります。
例えば、
- どの施設に、
- どの様な経緯で来院して、
- どの様な症状を持って、
- 何の検査でどんな結果がある患者を対象としているのか。
これらの事を明確にする必要があります。
これらの内容は 臨床状況 = clinical settings と呼ばれます。
目的検査 index text
目的検査は臨床研究において、評価される検査のことです。
例えば、
- いつ
- 誰が
- どこで
- どの様に行なった検査なのか
これらの項目について評価する必要があります。
スタンダード reference standard
スタンダードは至適基準とも言われています。
診断性能を評価する際には、対象患者が病気を有するのか有していないのかを判断しないといけません。
それを判断するための手順(検査など)がスタンダードと言います。更に、スタンダードは設定する事が非常に重要です。
ここで復習ですが、ゴールデンスタンダードとは、対象疾患の有無に関する完璧な情報(感度100%、特異度100%)の事です。
しかし、不完全な分類しか得られない時には、reference standard と言います。
診断性能 diagnostic accuracy
診断性能は目的検査が目的疾患の有病、無病を識別する能力の事です。臨床検査において、この診断性能を評価するのはマストです。
診断性能とは、感度、特異度、尤度比やROC曲線で表すことができます。
機械学習の臨床研究に適した研究デザインは何か

機械学習を用いた診断ツールの精度に関する臨床研究に適した研究デザインとは何なのでしょうか。
結論からいうと、横断研究型のデザインを取る必要があります。ここで、横断研究型のデザインの位置づけについて以下の図を参照してください。
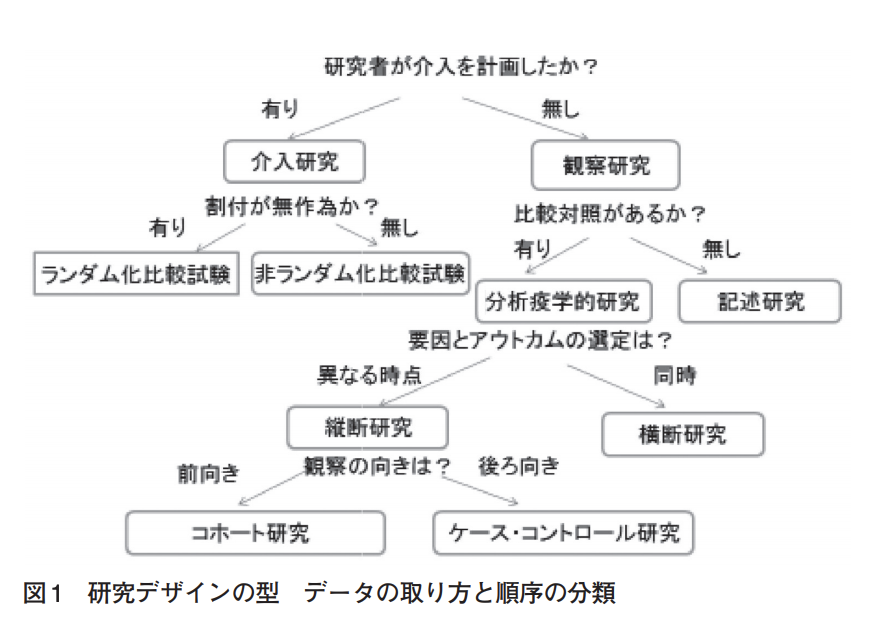
それでも縦断研究を選択し、ケースコントロール型の研究を行う場合には、ケースには診断の容易な患者を避けましょう。
コントロールには対象の疾患と共通の症状があるが、その疾患はないと分かっている患者を対象とするなど、医療者が日常的に遭遇する様な患者スペクトルに近所させる必要があります。
とはいえ、ケース・コントロール型のデザインは少々問題があります。その理由としては診断性能を過大評価しがちであるためです。
バイアスへの対応について

スペクトラムバイアス(患者スペクトルによるバイアス)
例えば、一般健診における子宮体癌スクリーニングのための血中腫瘍マーカーを開発するとします。その場合、標的母集団はあくまで一般健診受診者であり、サンプリングは一般健診受診者の中から選び出される必要があります。
もしサンプリングを、大学病院やがん専門の病院の外来通院中の患者さんに対して行うと、一般健診受診者からサンプリングした場合と異なる結果が出てきてしまいます。
異なる集団からサンプリングした事によって偏った結果が出る事をスペクトラムバイアスと言い、内的妥当性に問題を生じます。
研究対象の患者のback groundや特性(患者スペクトル)が、日常の臨床とは異なるために行ってくるバイアスのことをスペクトラムバイアス(患者スペクトルによるバイアス)と言います。このスペクトラムバイアスは、ケース・コントロール型の研究で起こりやすいです。
そのため、このバイアスを解決するためには、横断研究型のデザインをとる必要があると考えます。
統計解析で扱う主な変数は連続変数(continuous variable)、順序変数 (ordinal variable)、名義変数(nominal variable)の 3 つに分ける事ができます。
結果がこの変数のうちのどれに当てはまるかによって、診断法を評価する方法を検討します。»【第1章】統計の基礎知識1
選択バイアス
確認バイアス(verification bias)
確認バイアス(verificcation bias)とは精査バイアス(work-up bias)ともいう事ができます。確認バイアスは選択バイアスの一種です。
確認バイアスは有病と無病の確認がとられた患者だけを対象とした研究で生じます。確認バイアスを避ける方法は、全例でスタンダードを得る事です。
情報バイアス
解釈バイアス
解釈バイアスは情報バイアスの一種であり、機械学習を用いて作った診断ツールの精度を確認する臨床検査では、非常に重要なバイアスとなります。
その理由は臨床検査における検査内容にあります。
検査には、結果が数値で表せられるものと、画像診断の様に結果を得るために解釈の必要があるものがあります。
特にレントゲンを機械学習を用いた診断支援ツールで画像診断を行う、という時には要注意です。
画像の読影など検査結果を得るために、ある特定の医師の解釈が必要な場合、個人の主観が入る可能性があります。そのため、利用できる情報によってバイアスが生じる可能性があります。
解釈バイアスを避ける方法は、2 つあります。
1つ目には解釈する評価者に対してスタンダードの結果を盲目化しておく必要があります。
2つ目に注意すべきポイントは、検査結果以外の要素が診断性能に影響することにも注意が必要です。例えば、最も重要な要素は患者背景などの臨床情報です。
もしこの臨床情報を含めて全ての情報を盲目化する事ができない場合には、特殊な統計学的処理を行う必要があります。
機械学習の臨床研究におけるPECOの設定について
臨床研究のリサーチクエスチョンをPECOに落としこむ事が重要です。
ここで、診断研究におけるPECOについてまとめておきます。
診断研究におけるPECO
- P:診断が必要とされる患者
- E:目的検査を組み入れた診断
- C:既存の診断
- O:疾患の診断性能
例としては
肺炎疾患を持つ患者に対するレントゲン画像の機械学習を用いた診断研究のPECO
- P:肺炎疾患疑いの患者
- E:機械学習を用いたレントゲン画像診断
- C:医師によるレントゲンの画像診断
- O:機械学習を用いたレントゲンの画像診断の性能
ここでのポイントは、OがP(対象者)の直接的な臨床アウトカムではなく、診断性能となる点です。
これが機械学習を用いた診断研究の特徴的なところです。
その他にも間違えやすい点として、診断性能について評価を行う臨床研究は、要因(Exposure)が目的検査の陰性か陽性かで表現することができ、アウトカム(Outcome)は疾患の有無として表現をすることができそうですが、これは間違いです。
上記の例のように、標準検査による診断=既存の診断というコントロールを加えることによって、要因(Exposure)が目的検査を組み入れた診断となり、アウトカムが疾患の診断性能、という形に落とし込むことができます。
診断性能の評価研究の質の担保のために

診断性能に関する研究の質を高めるために作成されたガイドラインがあります。
それをSTARD(Standards for Reporting of Diagnostic Accuracy)声明と言います。
リンクで英文の原本に飛ぶ事ができますが、日本語に訳したSTARD声明の概略を記載しておきます。
STARDチェックリスト
- 診断性能の研究である事
- リサーチクエスチョン
- 適格基準・セッティング
- 対象者登録
- サンプリング(連続例かどうか)
- データ収集の手順
- スタンダードとそれを選択した根拠
- 検査手順の詳細
- カットオフ値または分類と、その根拠
- 検査実施者・結果判定者のトレーニング
- 結果判定のブラインド状態
- 診断性能の推定
- 実施した場合、再現性の推定
- 研究実施期間
- 対象の特徴(臨床的、人口統計的)
- 対象者の数(フローチャートを使用)
- 目的検査とスタンダードの時間間隔
- 目的とする疾患の重症度分類
- スタンダードの結果別の集計
- 有害事象
- 診断性能の推定値と信頼区間等
- 判定しにくい結果や欠測の扱い
- 検討した場合、サブグループの結果
- 検討した場合、再現性
- 研究結果の臨床的応用
1〜25に分類しましたが、これらを方法、結果、考察で分類してみましょう。
1〜25を分類
- タイトル:1
- イントロダクション:2
- 方法:3〜13
対象者:3〜6
検査:7〜11
解析:12、13
- 結果:14〜24
対象者:14〜16
検査結果:17〜20
診断性能:21〜24 - 考察:25 となります
機械学習を用いた診断法についての臨床研究において重要な点のまとめ

機械学習を用いた診断ツールを用いた臨床研究において重要事項のまとめです。
順を追ってcheckして行きましょう。
診断性能の評価
- 有病、無病にグループを分けて比較しても検査の有効性は評価できない。
- 検査の有効性の評価には必ず、感度・特異度などの診断性能の指標を用いる。
診断性能の評価研究におけるバイアス
- 検査の診断性能に特徴的なバイアスに注意をする。(スペクトラムバイアス、確認バイアス、解釈に伴うバイアスなど)
- STARDチェックリストに沿って診断性能研究の質を高める。[/tl]
診断性能の比較研究
- 目的検査と標準検査の診断性能を比較する研究デザインをとると結果の解釈が容易になる。
- 新しい検査のポジション3つを理解する(置き換え(replacement), 選別(triage), 追加(add-on))
診断から予後の改善へ
- 検査の性能と患者健康とを結びつきを整理する「検査の有効性の階層モデル」が開発されている。
- 検査の有効性の階層モデルは以下の6つある。それぞれがアウトカムになりうるので、理解する。(①技術性能、②診断の正確さ、③医療者へのインパクト、④治療へのインパクト、⑤健康へのインパクト、⑥社会的効率)
この流れに沿って、今一度、研究デザインについて考慮しましょう。
参考文献、参考書籍一覧

診断法に関する臨床試験の参考書籍
臨床試験に関する参考書籍はたくさんあるのですが、診断法に関する参考書籍はほとんどないですよね。
僕も相当探しましたが、「診断法を評価する」は非常にわかりやすくまとまっており、これから診断法の臨床試験の研究をされる方には非常におすすめです。
「診断法を評価する」は今回の記事を更に深掘りして記載していますし、これから臨床に進まれる研修医の方や医学生の方は持っておいて損はありません。
これらの書籍で臨床試験を取り組む考え方を学んだ上で臨床にのぞむと、普段から学会発表へのアイデアを臨床研究に持ち込むには非常に有用です。
臨床研究を始める前に、これらの書籍を抑えておくとよりスムーズに取り組むことが出来るでしょう。



参考文献一覧
参考文献
- Kalff V, Hicks R J, MacManus MP. et al. Clinical impact of (18) F fluorodeoxyglucose positron emission tomography in patients with non-small-cell lung cancer: a prospective study. J Clin Onccol. 2001; 19: 111-118.
- Schroder FH, Hugosson J, Roobol MJ, et al.; ERSPC Investigators. Screening and prostate-cancer mortality in a randomized European study. N Eng J Med 2009 Mar 26; 360:1320-1328.
参考になる臨床試験のためのガイドライン
- 無作為化比較試験を行うためのガイドライン:CONSORT(日本語ver.), CONSORT(英語ver.)
- 疫学研究を行うためのガイドライン:STROBE(日本語ver.) , STROBE(英語ver.)
- モニタリング及び監査に対する参考資料:JCTN(Japanese Cancer Trial Network)