
こんにちわ。
この記事では、機械学習を行う際に必要なデータの前処理についての方法について実践を踏まえながら練習問題を通して学習していきます。
練習問題の題材としてはKaggleで無料で配布されている資料を使用します。Kaggleにあるcsvファイルをダウンロードし、jupyter notebookで作業を行う場所と同じフォルダにアップロードしてください。
機械学習を行うにあたり、データの抽出やデータの作成・整理は最も重要になります。臨床試験でも企業でのデータ処理の案件でもそうですが、データの作成次第で結果が大きく変わってくると言っても過言ではありません。
機械学習を始める前に必要なデータの調整のことを データの前処理 と言います。このデータの前処理は、機械学習でデータ分析を行う全ての行程のうちの鬼門とも言えます。
今回はkaggleのcompetitionで使用されたデータを用いてデータの前処理方法を行います。
使用するデータはKaggleのcompetitonのうち、House Prices:Advanced Regression Techniques と言われるものです。リンクよりデータをダウンロードして使用してください。
では早速データの下処理の仕方について学んでいきましょう。
機械学習のためのデータの前処理の方法の概要と手順

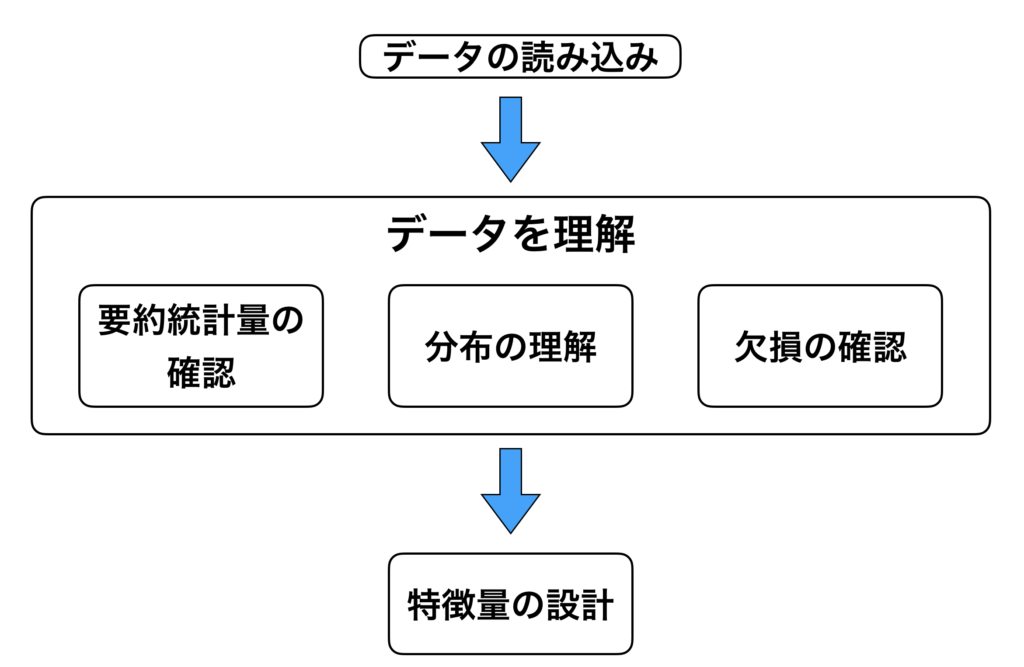
準備したデータの取り込みを行う。
準備した csv 形式の取り込みを行う。データの量や、どの様なアウトカムを導きたいのか、によって取り込むツールが変わってきます。
データの理解
次の工程として、「データの理解」をします。具体的には、カラムの定義や、欠損があるのか、ないのかなどの確認を行います。
特徴量の設定
データの理解が終了すれば、最後は「特徴量の設計」を行います。データをそのまま使用しても良い結果に繋がらない場合があるので、新たに特徴量を作るなど色々と試してみる必要があります。
機械学習のためのデータ前処理を行う【実演編】

STEP1:機械学習のデータ前処理に必要なモジュールの読み込み
まずは必要なモジュールの読み込みを行います。
in[]
1 2 3 4 5 6 7 8 | import matplotlib import matplotlib.pyplot as plt import numpy as np import pandas as pd matplotlib.style.use('ggplot') %matplotlib inline |
1 | pd.set_option('display.max_columns', 400) |
ここで、matplotlib.style.use('ggplot')というコードがありますが、matplotlib の style には 'ggplot' を含めて沢山のものがあります。
色々なスタイルのうちの一つとして考えてください。以下のサイトが参考になりますので、参照してください。
» matplotlibのstyleを考える
STEP2:機械学習のデータ前処理に必要なデータの読み込み
CSVファイル"kaggle_housing_price.csv"を読み込み、内容を確認します。ライブラリ pandas には read.csv という便利な機能がついているので、これを使用してcsvファイルを読み込みましょう。
in[]
1 2 3 | # データ読み込み dataset = pd.read_csv("kaggle_housing_price.csv") type(dataset) |
out[]
1 | pandas.core.frame.DataFrame |
in[]
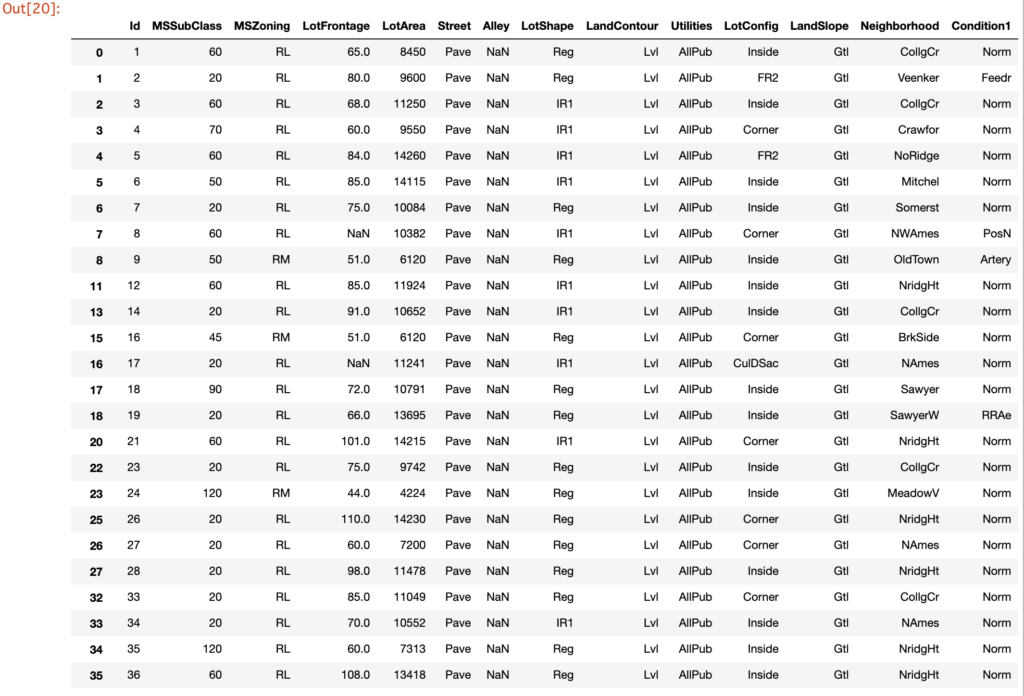
1 2 | # データを最初の5行だけ表示 dataset.head() |
out[]
DataFrameのshape プロパティで全データの行数と列数を取得できます。
» Pandas.DataFrame.shape
in[]
1 | dataset.shape |
out[]
1 | (1460, 81) |
STEP3:データの理解|機械学習のデータ前処理に必要な要約統計量を出力する
データの理解①:データの要約統計量の確認
これからデータを理解する作業にうつります。
データを理解するためには、データ数、平均や中央値、標準偏差などの統計量を確認し、データの要約統計量をまとめていきます。
DataFrameの describe() メソッドを使うと、様々な統計量の情報を要約して表示してくれますので便利です。
» Pandas.DataFrame.describe
in[]
1 2 | # 要約統計量を表示 dataset.describe |
out[]
ここでお気付きの方もいると思いますが、少し表がガタガタしていて汚いですよね。理由としては、 dataset.describe() ではなく dataset.desccribe と記載しているためです。
そのため、再度 dataset.describe() を入力し出力データを確認してみましょう。
in[]
1 2 | # 要約統計量を表示 dataset.describe() |
out[]
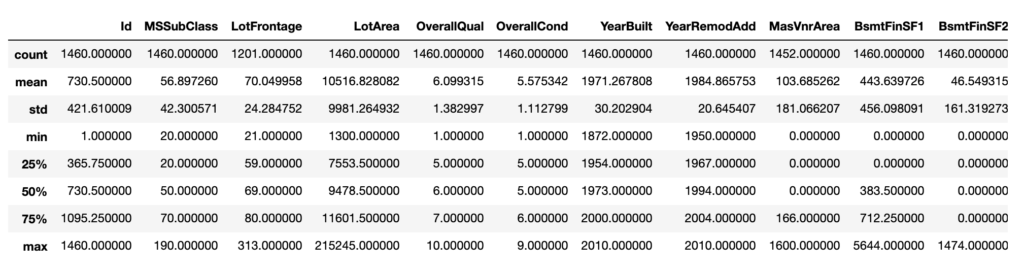
これで、ある程度綺麗な表として出力することができました。
メソッド .describe には引数 () をつけることを覚えておいてください。
それぞれの行の意味ですが、「conut」はレコード数で「mean」は平均です。「std」は標準偏差、つまりデータのばらつきの程度を表しています。「min」は最小値、「max」は最大値で、その間にある「25%」、「50%」、「75%」は、それぞれのパーセント点を意味します。
例えば、「25%」であれば、データを小さいものから大きいものに並べた時の25%目、つまり100個のデータがあれば、小さいものから25個目に来る値ということです。
これらのアウトプットを見ながら、データ理解の糸口にします。
データの理解②:特定のインデックス番号を抽出し表示する方法
in[]
1 2 | # インデックス番号0~10の行を抽出 dataset[0:10] |
out[]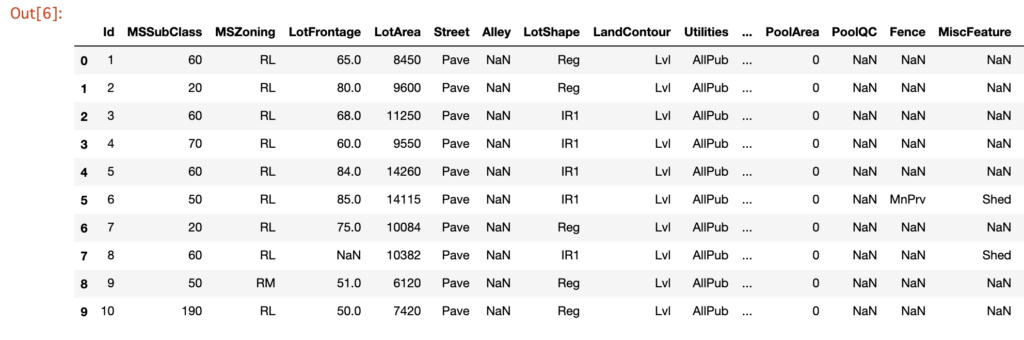
次に、特定の列名('SalePricce')を抽出し、最初の数列(5行)を表示する方法についてみていきましょう。
in[]
1 | dataset['SalePrice'].head() |
out[]

この様にSalePriceの列のみを抽出し、さらに .head() のメソッドを使用する事で最初の5行のみを表示する事が出来ました。
次に、特定の列名を2つ('SalePrice', 'LotArea')を抽出し10行目〜20行目を抽出する方法について見ていきましょう。
in[]
1 | dataset[['SalePrice','LotArea']][10:20] |
out[]
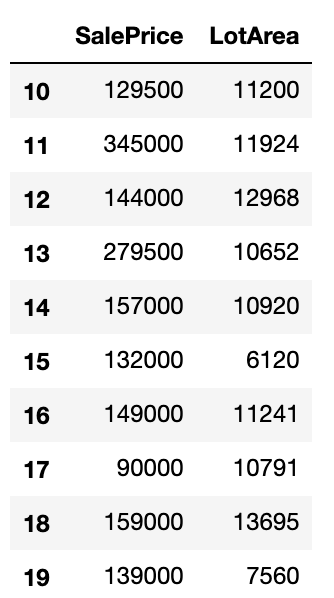
datasetの後に、[][]と2回[]が続きますが、これは慣れるしかありません。
非常に便利ですので、参考にしてください。
次に特定の行番号、列番号を指定して抽出する方法について見ていきましょう。
特定の行番号や列番号を指定して抽出する場合には .iloc というメソッドを使用します。以下のサイトがまとまっているので、参考にしてください。
» Pandasのloc, ilocの違い(※ Python3.0以上ではixはもう使用することは出来ませんので無視してください)
in[]
1 2 | # 行番号、列番号で抽出する dataset.iloc[0:5, [0,2,4]] |
out[]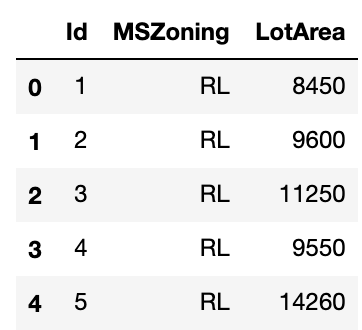
0列目、2列目、4列目に加えて0〜5行目を抽出した形になります。
次に、特定の行の名前、列の生を指定して抽出する方法を確認しましょう。
一つ上では特定の行、列の番号で抽出する作業を行いました。
今回は特定の行・列の名前で抽出する作業を行って見ましょう。
ここでは .loc を使用します。
» Pandasのloc, ilocの違い(※ Python3.0以上ではixはもう使用することは出来ませんので無視してください)
in[]
1 2 | # 行の名前、列の名前で抽出する dataset.loc[0:5, ['Id', 'MSSubClass','MSZoning','LotFrontage','LotArea']] |
out[]
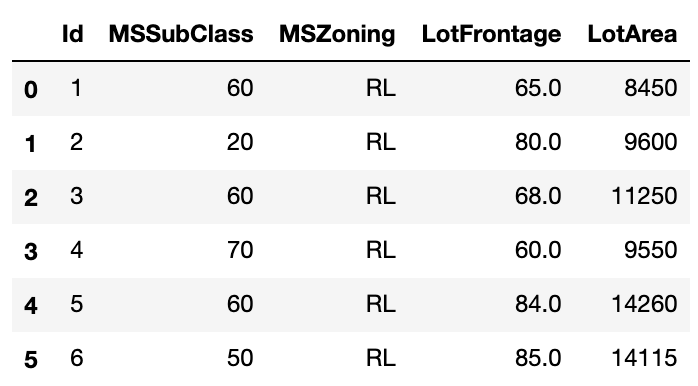
今回行の名前は0〜5なので番号表示しましたが、列と同様にstr型の場合には '' を用いて情報を抽出する事が出来ます。
特定の列を指定した状態で(例えば、'SalePrice'や'LotArea'など)、特定の行を抽出する方法を確認してみましょう。
in[]
1 2 | dataset.SalePrice[0:9] dataset.LotArea[0:10] |
out[]
[yoko2 responsive][cell] [/cell][cell]
[/cell][cell] [/cell][/yoko2]
[/cell][/yoko2]
STEP4:データ処理|カラム間の演算
PandasのDataFrameでは、列同士で足したり引いたり、更には新しい列までも加えることができます。
たとえば、df というDataFrameの変数があるとします。その中の x, y 列を利用して、df['z'] = df['x'] + df['y'] と記述することで、 z 列という新しい列を df に追加することが出来ます。
- dfは読み込んだデータセット名である必要があります。
- df = pd.read_csv(‘dataset.csv’)のような形で書くとdataset.csvというcsvファイルを読み込んでdfという名前にすることができます。
例えば以下の様に使用します。
1 2 3 | # "1stFlrSF"と"2ndFlrSF"を合計した"FlrSF_total"を新たな列として加える df=pd.read_csv('kaggle_housing_price.csv') df['FlrSF_total'] = df['1stFlrSF'] + df['2ndFlrSF'] |
STEP5:データ処理|ダミー変数の作成
列 SaleType は WD, New, COD など、合わせて9種類の値しかありません。このようなデータをもつ列は一般的に カテゴリ変数 と呼びます。
カテゴリ変数のデータは、ダミー変数 にしてあげましょう。たとえば SaleType ですと、
SaleType_WD:SaleTypeのデータがWDなら1、それ以外の場合は0SaleType_New:SaleTypeのデータがNewなら1、それ以外の場合は0SaleType_COD:SaleTypeのデータがCODなら1、それ以外の場合は0
このようにして、SaleType のデータの種類数に合わせて9個の新しい列を作成します。この9個の列には、1つが 1 で、残りは全て 0 が入っています。これがダミー変数です。
ダミー変数化するのに最も楽な方法は、Pandasの get_dummies() を使う方法です。
» Pndas.get_dummiesの使い方
in[] →×ダメな例
1 2 3 | # 列'SaleType'をダミー変数に展開したものを変数 dataset に上書きする。 pd.get_dummies(data = dataset, columns = ['SaleType']) dataset.head() |
ここで1行目のpd.get_dummies(data = dataset, columns = ['SaleType'])についてですが、このまま記載するとダミー変数化はできていますが、datasetを上書きしていないため、dataset の中身が更新されていません。
そのため、以下の様に記載する様にする必要があります。
in[] →正しい例
1 2 | dataset = pd.get_dummies(data = dataset, columns = ['SaleType']) dataset.head() |
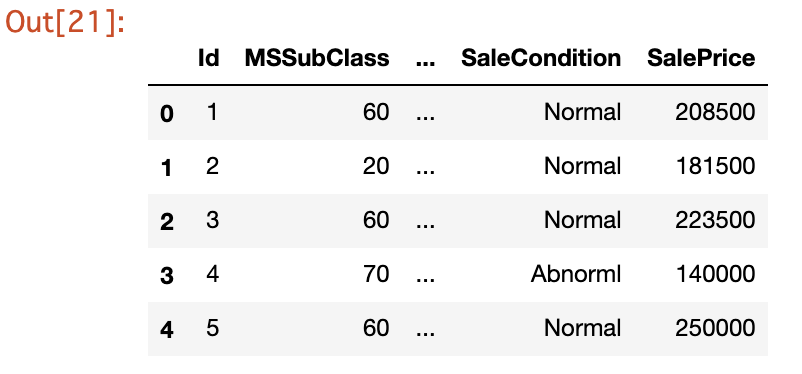
STEP6:データ処理|フィルタリング【特定の条件の列を抽出する】
特定の条件の行のみ抽出することができます。そのために、DataFrameの query() を使います。括弧の中に条件式を記述してください。
たとえば、LotArea が 15000以上 という条件にするなら、dataset.query('LotArea >= 15000') です。最後に .head()を追記すれば、今までどおり5件だけの取得になります。
» pandas.DataFrame.query
in[]
1 2 3 4 | # 'YearBuilt'が2000以降の物件のみを抽出し、最初の5件のみ表示 # 現在の最大表示列数の出力 import pandas as pd pd.get_option("display.max_columns") |
out[]5
in[]
1 2 3 | # 'YearBuilt'が2000以降、'GarageCars'が2以上の物件を抽出 import pandas as pd dataset.query('LotArea >= 2000'and'GarageCars >=2') |
out[]
'YearBuilt' が2000以上(以降)の物件のみを抽出し、最初の5行のみを表示する方法
in[]
1 2 3 | # その1 # 'YearBuilt'が2000以降の物件のみを抽出し、最初の5件のみ表示 dataset[dataset['YearBuilt']>2000].head() |
out[]
query を使用しても上記と同様の操作を行うことが出来ます。
in[]
1 2 3 | # その2 # 'YearBuilt'が2000以降の物件のみを抽出し、最初の5件のみ表示 dataset.query('YearBuilt > 2000').head() |
out[]
※ dataset.query('LotArea >= 15000 and MSSubClass >= 50') のように複数の条件を指定することも出来ます。
dataset.query('LotArea >= 15000 and MSSubClass >= 50')
※ ただし。LotArea とMSSClassの間はカンマ, ではなくて and にする必要があります。( .query の中は and です。)
in[]
1 2 3 4 5 6 7 8 | # 'LotArea'が2000以降、'GarageCars'が2以上の物件を抽出 # その1 dataset.query('LotArea >= 2000'and'GarageCars >=2').head() # 'LotArea'が2000以降、または'GarageCars'が2以上の物件を抽出 # その2 dataset.query('LotArea >= 2000|GarageCars >=2').head() |
out[]
データの可視化を行う

要約統計量やスライシングでデータを確認しただけでは理解が深まりにくいので、ここからはデータの可視化の方法を解説していきます。
データの分布を確認するための可視化の手法として、ヒストグラムという方法があります。ヒストグラムは、ある連続した変数についての分布の形を可視化するためのものです。
早速ヒストグラムを確認してみましょう。
【データ処理の結果】ヒストグラム
ヒストグラムは、連続変数の分布を確認する際に有効です。DataFrameの hist() が利用できます。詳しくは以下のサイトを参照にしてください。
» pandas.DataFrame.hist
ここで間違ったコードの書き方を記載します。
in[]
1 2 3 | # datasetの'SalePrice'をヒストグラムで表示 df=pd.read_csv('kaggle_housing_price.csv') hist = df.hist(bins=3) |
out[]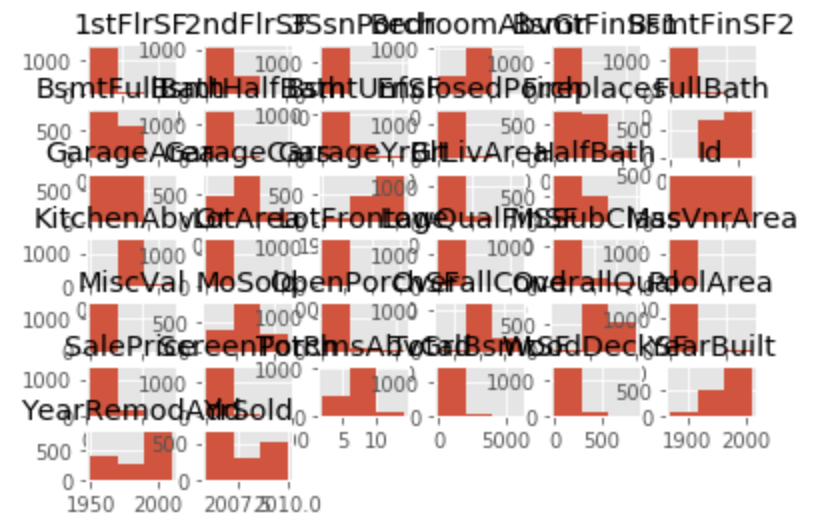
これだと、datasetの中のヒストグラムにできる変数全てがプロットされてしまいます。
df に read_csv で改めてデータを読み直していますが、最初に用いたdatasetで良いかと思います。
また、dataset.hist() としますとdatasetの中のヒストグラムにできる変数全てがプロットされてしまいます。dataset[‘Saleprice’]などで列名を絞って.hist()としますと綺麗にヒストグラムが作図できるかと思います。実際に行なってみましょう。
in[]
1 2 3 | # datasetの'SalePrice'をヒストグラムで表示 df=pd.read_csv('kaggle_housing_price.csv') hist = df.hist["SalePrice"] |
out[]
しかしこれでもまたもやErrorが出てしまいました。
結論としては、「dataset.hist()ではなく、dataset[‘SalePrice’].hist()とする必要があります。」実際に代入してみましょう。
in[]
1 2 3 | # datasetの'SalePrice'をヒストグラムで表示 df=pd.read_csv('kaggle_housing_price.csv') hist = dataset['SalePrice'].hist() |
out[]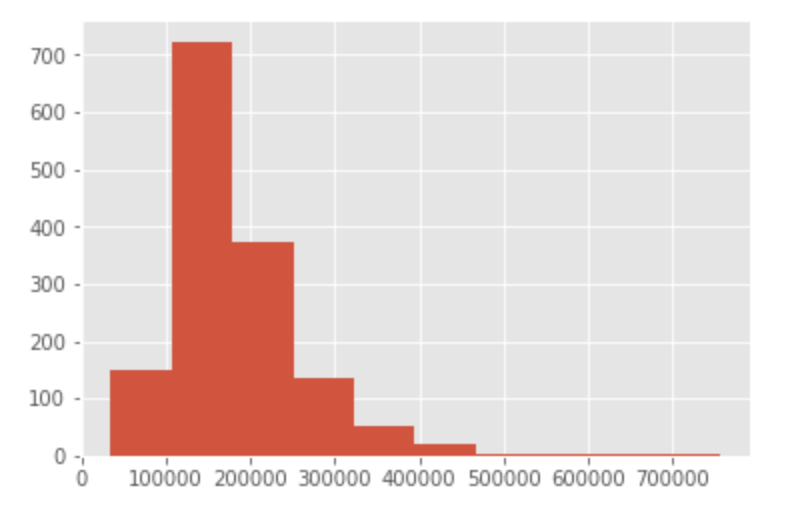
これでヒストグラムで表すことができました。dataset[‘SalePrice’].hist() の扱い方を覚えておきましょう。
ヒストグラムの見方は、横軸が物件の価格で、高さは該当するデータの頻度です。例えば、0ドルから、10,000,00 ドルの間に入るレコードは 18,000 レコードがある、という事が分かります。
【データ処理の結果】散布図
次に散布図です。散布図は、縦軸と横軸共に連続変数を持ってきて、2つの変数の関係性を理解するためのグラフです。
pandas では簡単に作る事ができます。DataFrameの plot() が使えます。pandas.DtaFrame.plot が参考になりますので参考にどうぞ。
in[]
1 2 3 4 5 6 7 8 9 10 11 12 | # datasetの'LotArea'と'SalePrice'を散布図で表示 lotarea = np.array(dataset["LotArea"]) saleprice = np.array(dataset["SalePrice"]) import numpy as np import matplotlib.pyplot as plt fig = plt.figure() plt.plot(lotarea, saleprice, 'k.') plt.xlabel("LotArea") plt.ylabel("SalePrice") plt.show() |
out[]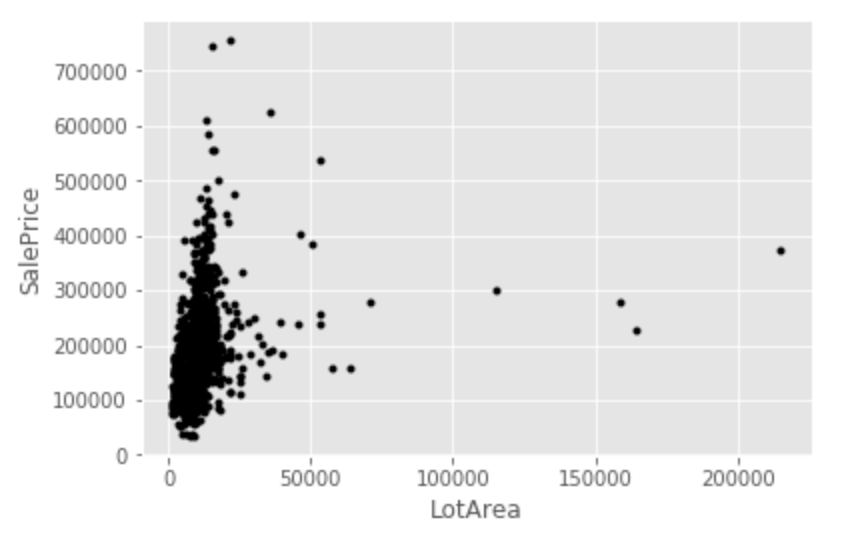
この散布図を見ると、LotAreaと価格の間に明らかな相関関係はなさそうですね。
【データ処理の結果】棒グラフ
次は、グループ集計と棒グラフの組み合わせです。棒グラフは大小や増減を比較する際に有効です。グループ集計には、pandasの groupby というメソッドを使用します。キーを指定して集計するのですが、今回は物件のセールの状態を示す「SaleCondition」というカラムをキーにしましょう。
groupbyに続いて aggregate 時うメソッドがありますが、これは SQL で言う所のSELECTの中身の様なものです。
ここでは価格の平均を計算する事にしています。最後の rest_index は、作成したデータフレームのインデックスを初期化します。
DataFrameの plot.bar() が使えます。plot.bar に関してはpandas.DataFrame.plot.barが参考になるかと。
また、Pandasのgroubyの使い方については Pandasのgroubyの使い方が参考になります。
in[]
1 2 3 4 5 6 7 | #'SalePrice'のSaleCondition毎の平均を変数 price_by_conditionに格納 price_by_condition = dataset.groupby('SaleCondition').aggregate({'SalePrice': np.mean}).reset_index() # price_by_conditionが持つ、棒グラフを表示する命令を実行 plt.bar(price_by_condition['SaleCondition'], price_by_condition['SalePrice']) |
out[]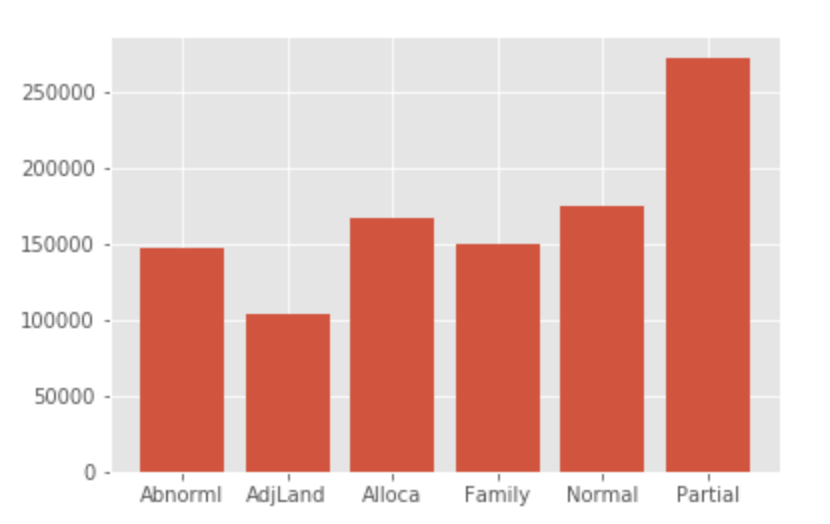
この棒グラフを確認すると、AdjLand は平均価格が低めで、Partialは高めになっています。このことから横軸は何かしら物件の状態を表していて、価格にも相関関係がありそうです。
【データ処理の結果】箱ヒゲ図 (Boxplot)
複数の変数の分布を比較する際に有効です。 (棒グラフでは平均の比較はできますが、分布全体の比較はできません)
DataFrameの boxplot() が使えます。
» pandas.DataFrame.boxplot
1 2 | # datasetの'SaleCondition'ごとに'SalePrice'をboxplotで表示 dataset.boxplot(column=['SalePrice'],by='SaleCondition') |
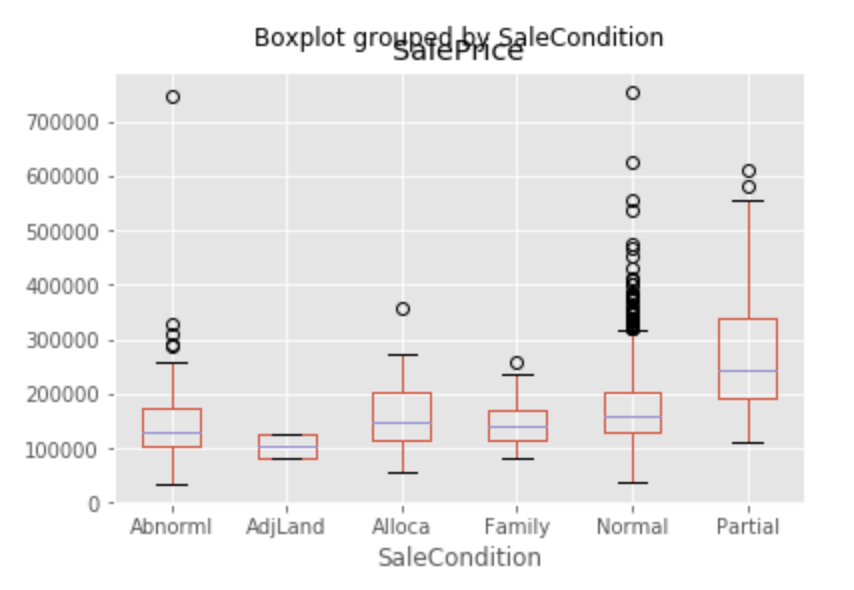
データ欠損値の確認
カリキュラムで利用した野球選手の年俸データは、きれいにしたデータでした。通常の集めたデータは、一部のデータが欠けていることがほとんどです。
欠けているデータを 欠損値 といいます。データに欠損値があると、演算でエラーが起きる場合があります。
欠損値の扱いは欠損が発生した原因により異なります。基本的には、精度に影響しないようなデータで埋めます。一例としては 0、平均値や中央値などです。
ある列が欠損値を持っているかどうかは Pandas の isnull() でわかります。pd.isnull(dataset['LotFrontage']) のように記述します。また、.sum()をつなげることで、その列で欠損値を持つ行数がわかります。
» pandas.insull
1 2 | # 列ごとに欠損値の有無を確認 pd.isnull(dataset['LotFrontage']) |

でもこれだけでは、欠損した箇所が何箇所あるのが非常に分かりにくいですよね。trueが欠損した部位になるのですが、このTrueの部分を1として足し合わせると、欠損した箇所がいくつか分かります。
in[]
1 2 3 4 5 6 7 8 9 10 11 12 | # 列ごとに欠損値の有無を確認し、欠損した箇所の合計を足し合わせる sum(pd.isnull(dataset['LotFrontage'])) dataset.shape # 列名を取得 Cols = dataset.columns for i in range(dataset.shape[1]): null_num = sum(pd.isnull(dataset.iloc[:,i])) #[:,i]全ての行のi列目を取得するという事 if null_num>0: print(Cols[i], null_num) |
out[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | 259 (1460, 89) LotFrontage 259 Alley 1369 MasVnrType 8 MasVnrArea 8 BsmtQual 37 BsmtCond 37 BsmtExposure 38 BsmtFinType1 37 BsmtFinType2 38 Electrical 1 FireplaceQu 690 GarageType 81 GarageYrBlt 81 GarageFinish 81 GarageQual 81 GarageCond 81 PoolQC 1453 Fence 1179 MiscFeature 1406 |
特徴量の設計
データの正規化
データ正規化の方法として、特徴量の値を変換して適当な値の範囲におさめる、というものがあります。正規化の方法の代表例としては、以下の2種類があります。
Z-score normalization
標準化とも言います。平均が0、標準偏差が1になるように、各特徴量の値を変換します。
Min-max normalization
狭義に正規化とも呼ばれます(広義には標準化も正規化です)。最小値が0、最大値が1になるように、各特徴量の値を変換します。
» sklearn.preprocessing.MinMaxScaler
各々のデータ正規化の方法についてはQittaでまとまっているページがあるので、参考にどうぞ。
» Feature Scalingはなぜ必要か
まとめ|機械学習のためのデータ処理は慣れればカンタン

いかがでしたでしょうか。
今回は機械学習を行う際のデータの前処理の仕方について、一から手順を追って解説していきました。データを処理には様々な方法があり、特にスライスの方法については【Python】文字列シーケンスについての記事と合わせて復習するとより理解が深まると思います。(データ処理の際にスライスは頻用します)
また可視化を行う際に、箱ひげ図や棒グラフの描き方、散布図の描き方の方法や、データの欠損値の確認方法などを学習しました。
この練習問題を通じて、データの前処理の方法を理解して頂ければと思います