
こんにちは。
産婦人科医で人工知能の研究をしているTommy(Twitter:@obgyntommy)です。
本記事ではPythonのライブラリの1つである pandas を利用してcsv/tsvファイルを読み込む方法について学習していきます。
pandasではCSVを読み込んだり、書き込む事を頻用しますが、結果的にご自身がが思う様には出来ていない場合があります。
- 文字化けしている。
- 書き込んだら変な列(index列)が足されている
- 列名がずれててうまく読み込めない
こういったトラブルにもしっかり対応できるようになっていきましょう。
pandasを利用したcsvの読み込み方法については以下の公式ドキュメントに記載されています。
-
pandas.read_csv — pandas 3.0.1 documentation
続きを見る

また、pandasを利用した表の読み込み方法については以下の公式ドキュメントに記載されています。
-
pandas.read_table — pandas 3.0.1 documentation
続きを見る

pandasの使い方については、以下の記事にまとめていますので参照してください。
-

【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
ここで本記事の学習到達目標です。
本記事の学習目標
- pandas を利用したCSV, TSVファイルの読み込み方
- pandas を利用したデータの書き込み方
今回は、これらの計算がしっかりできるように習得していきましょう。
データの準備

pandasのデータの読み込み
まず、pandas 読み込みましょう。
下記を実行してください。
In[]
1 2 | # pandasの読み込み import pandas as pd |
対象データの確認
データは本記事で用意した下記のデータを使います。
実行して、パスを設定しておきましょう。
In[]
1 2 3 4 5 6 | # データパス data_path1 = 'https://obgynai.com/csv_sample/sample1.csv' data_path2 = 'https://obgynai.com/csv_sample/sample2.csv' data_path3 = 'https://obgynai.com/csv_sample/sample3.csv' data_path4 = 'https://obgynai.com/csv_sample/sample4.csv' data_path5 = 'https://obgynai.com/csv_sample/sample3.tsv' |
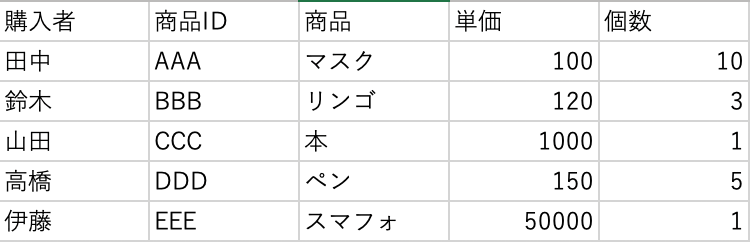
sample1.csv
以下の表はエクセルで作った、日本語のCSVで1列目に列名があるデータになります。
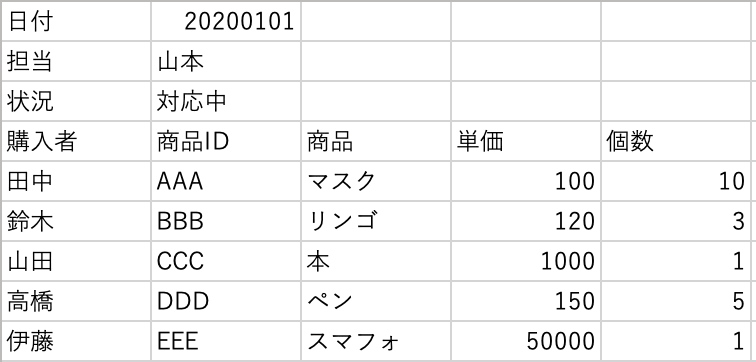
sample2.csv
以下の表はsample1.csv の表で、3行ほど他のデータが混じっていて、4行目からデータが始まっています。
sample3.csv
以下の表は、sample3.csv の表で、sample1.csv の列名がない場合となります。

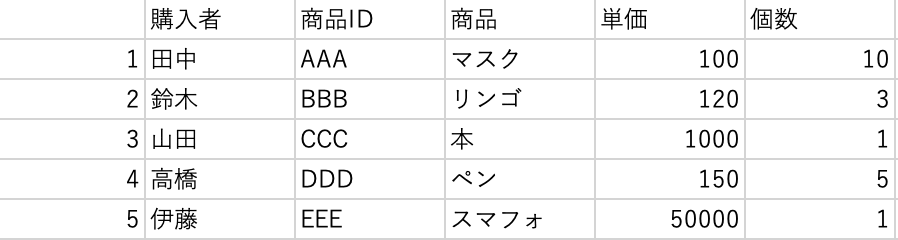
sample4.csv
sample4.csv は sample1.csv に index(行名)をつけたもので、行名は1,2,3,4,5としています。
index は数値に限らず、文字列でもOKです。
sample1.tsv
sample1.csv がカンマ区切りではなく、タブ区切りになっているデータ。
データの読み込み

pandasでCSVを読み込むときには、read_csvメソッドを使います。
文字コードの使い方
色々データを扱うと、日本語のCSVを読み込む機会も多いでしょう。
文字コードを encoding で適切に指定しないとエラーが出たり、文字化けすることがあります。
さっそく、sample1.csv を読んでみましょう。
In[]
1 | df = pd.read_csv(data_path1) |
エラーが出ます。
Out[]
1 | UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8d in position 0: invalid start byte |
encoding を指定しないと一般的な utf-8 になりますが、対応していないようです。
エクセルで出力されるファイルは「shift-jis」若しくは「cp932」を指定します。
これらの違いが気になる方 はANSI について参照ください。
今度は、パラメータを encoding=’cp932’とします。
In[]
1 2 3 | # df = pd.read_csv(data_path1, encoding='shift-jis') df = pd.read_csv(data_path1, encoding='cp932') df.head() |
これで無事に読み込む事が出来ました。
header(列名)がある場合のデータの読み込み方
ヘッダーがあるデータのsample1.csvを無事読み込めました。
他にも、列名を指定して読み込んだり、データの開始位置がずれているデータについてもみていきます。
列名を指定してファイルを読み込む方法
次は、sample1.csv を列名を指定して読み込みます。
データはなんでも詰め込まれて入っている場合が多いです。
read_csv でパラメータ「 usecols 」を指定することで、必要な列のみを取得できます。
対象の列名は、usecols に [‘列名’, ‘列名’, …] とリスト型で指定します。
In[]
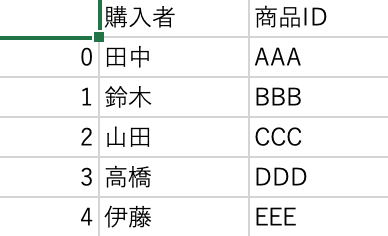
1 2 | df = pd.read_csv(data_path1, encoding='cp932', usecols=['購入者', '商品ID']) df.head() |
Out[]

列名の位置がずれているファイルを読み込む方法
データを取り扱う際には、色々なフォーマットを使用します。
「sample2.csv」では最初の3行に日付などのおまけのデータが入っていて、使いたいデータは4行目から始まっています。
この場合は開始位置をパラメータ「header」で開始行を指定します。
開始行は0から数えるので、今回は header=3 を指定します。
In[]
1 2 | df = pd.read_csv(data_path2, encoding='cp932', header=3) df.head() |
Out[]
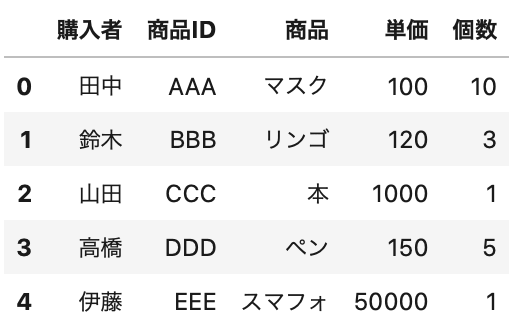
最初の3行を飛ばして、読み込めているのが確認出来ますね。
header(列名)がない場合のファイルを読み込む方法
列名がないデータもよくあります。
列名のない「sample3.csv」を読み込んでみます。
列名がない場合には、パラメータ「header」を None とします。
In[]
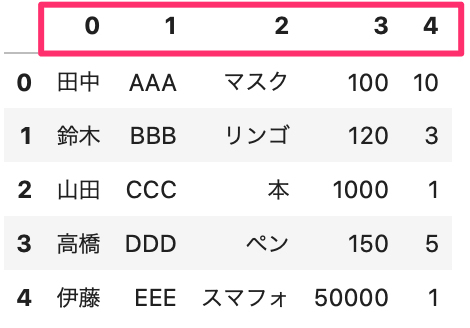
1 2 | df = pd.read_csv(data_path3, encoding='cp932', header=None) df.head() |
この場合、列名は 0, 1, … と自動で数字が割り当てられます。
Out[]
列を指定してファイルを読み込む方法
header がなくても、usecols を使うことで、読み込む列を指定できます。
指定する列は、自動で割り振られる数値を [0, 1] のように指定します。
In[]
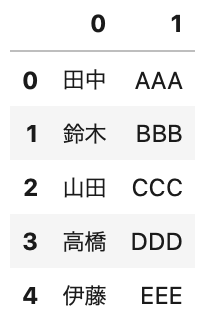
1 2 | df = pd.read_csv(data_path3, encoding='cp932', header=None, usecols=[0, 1]) df.head() |
Out[]
列名を付与してファイルを読み込む方法
列名がただの数値では、わかりにくいですね。
そんな時は、パラメータ「names」に列名をタプルやリスト型で指定できます。
In[]
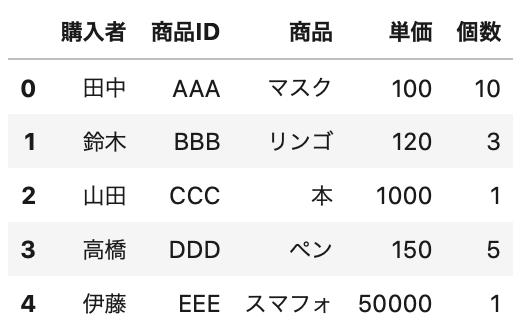
1 2 3 | df = pd.read_csv(data_path3, encoding='cp932', header=None, names=['購入者', '商品ID', '商品', '単価', '個数']) df.head() |
Out[]
index(行名)がある場合
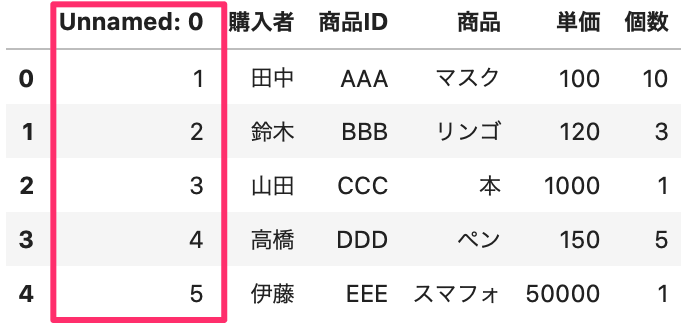
次に、sample4.csv の index がついているCSVファイルを読み込みます。
1行目は自動で header とされますが、1列目は列データとして取り扱われます。
これでは、1列目を index として使えません。
In[]
1 2 | df = pd.read_csv(data_path4, encoding='cp932') df.head() |
Out[]
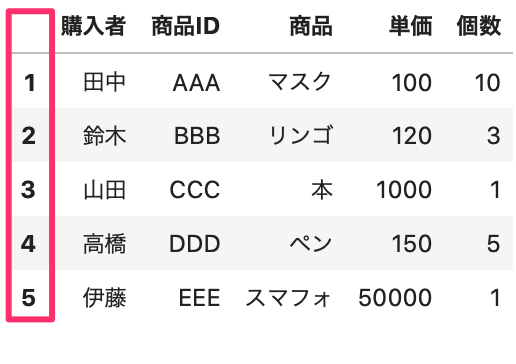
これを、index と指定するには、パラメータ「index_col」を使用します。
1, 2 , 3 列目は 0, 1, 2 とカウントするので、index_col=0 として1列目を index とします。
In[]
1 2 | df = pd.read_csv(data_path4, encoding='cp932', index_col=0) df.head() |
Out[]
index(行名)を指定して読み込む方法
指定した列のデータを取得したい場合、列名を指定していましたが、
指定した行のデータを取得したい場合では、読み込みたくない行名を指定します。
その場合、パラメータ「skiprows」に除外したい行名をタプルやリストにして渡します。
今回は、index が 1, 2, 3, 4, 5 と指定されている状態で確認していきましょう。
まず、index が 1 のもの以外を読み込む場合で確認してみましょう。
In[]
1 2 | df = pd.read_csv(data_path4, encoding='cp932', index_col=0, skiprows=[1]) df.head() |
Out[]
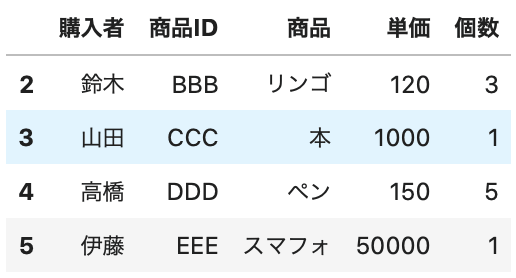
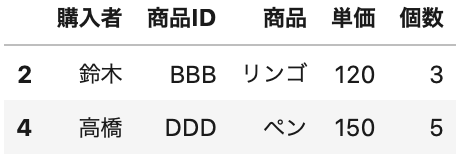
これでは、実用性がないので、1つとびでデータを取得したい場合もやってみましょう。
range メソッドで、(1, 3, 5 ) というタプルを作って、偶数行の 2, 4 だけ読み込みます。
In[]
1 2 3 | skip_rows = range(1,6,2) # (1, 3, 5) df = pd.read_csv(data_path4, encoding='cp932', index_col=0, skiprows=skip_rows) df.head() |
Out[]
tsvファイルの読み込み
csv ではありませんが、カンマ区切りではなく、タブ区切りの tsvファイル も読み込んでみましょう。
tsvファイル は自然言語処理をするときのデータで見ることがあります。
ファイルは sample1.csv をタブ区切りにした、sample1.tsv を使います。
read_table
read_tableを使って読み込むことができます。
read_csv では区切り文字「 , 」、read_table では区切り文字「 \t 」を使用して読み込みます。
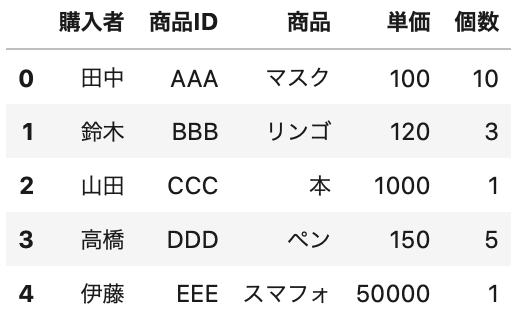
In[]
1 2 | df = pd.read_table(data_path5, encoding='cp932') df.head() |
Out[]
区切り文字を指定
read_csv でも、パラメータ「 sep 」で区切り文字を指定できます。
タブを表す文字は「 \t 」なので、これを sep に渡します。
In[]
1 2 | df = pd.read_csv(data_path5, encoding='cp932', sep='\t') df.head() |
ファイルに書き込みを行う方法

CSVは読み込むだけでなく、新しいデータを作ったら、CSVに書き込むこともあります。
引き続き、CSVの書き込み処理についてみていきましょう。
書き込むための元データは sample1.csv を使って、そのまま書き込んで行きましょう。
まず、データを読み込んでおきましょう。
In[]
1 | df = pd.read_csv(data_path1, encoding='cp932') |
読み込んだデータをパラメータ指定せずに書き込んでみましょう。
書き込むには、to_csvメソッドを使用します。
引数にはファイル名やフルパスを渡します。
In[]
1 | df.to_csv('output.csv') |
ファイル名を指定した場合、pythonコードを動かしているフォルダに保存されます。
保存場所がわからない方は、下記コードで保存場所を確認できます。
In[]
1 2 | import os print(os.getcwd()) |
では、結果をエクセルで確認してみます。
どうでしょう?期待しているデータと違う気がします。
読めませんし、左に1列追加されています。
Out[]
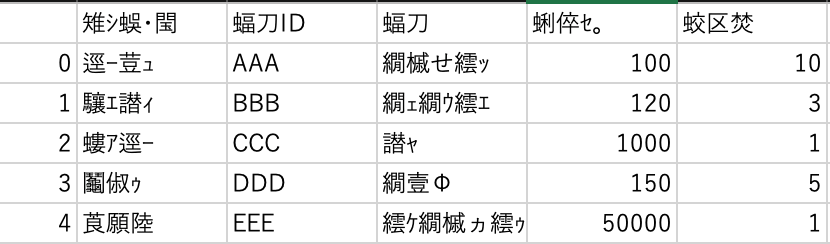
けっして、バグでデータが壊れたわけではありません。
試しに、出力した「output.csv」を読み直してみましょう。
In[]
1 2 | df = pd.read_csv('output.csv') df.head() |
Out[]
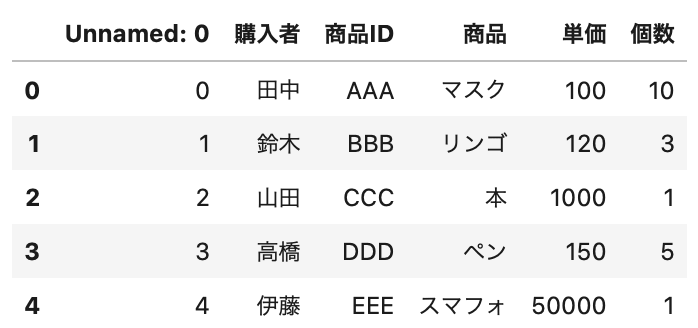
ちゃんとデータが読めています。
読めていますが、誰かにデータを渡した場合には、データを見ることができないかもしれません。
しっかり、CSVの書き込みについて習得していきましょう。
文字コード
データはエクセルで共有することがあるかもしれません。
その場合は、文字コードを指定して出力しましょう。
文字コードは読み込みと同じです。encoding=’cp932’ を渡します。
In[]
1 | df.to_csv('output.csv', encoding='cp932') |
エクセルで開くと文字化けせずに読み込めています。
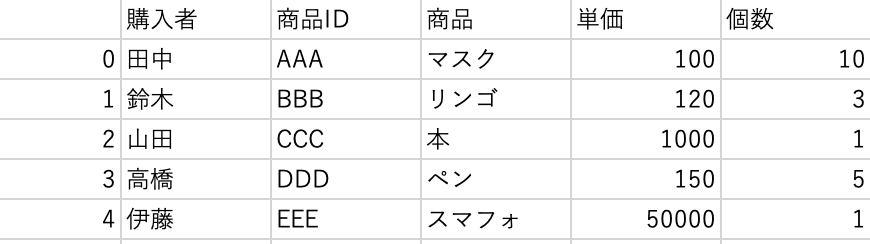
エクセルで共有しない場合は、文字コードは指定しなくて良いです。
indexの有無
文字化けは治りましたが、左に列が追加されて出力されています。
これは、DataFrame では index のデータがあり、それが出力されています。
出力するしないは、パラメータ「index」を使います。
- True:出力する
- False:出力しない
となります。
In[]
1 | df.to_csv('output.csv', encoding='cp932', index=False) |
Out[]
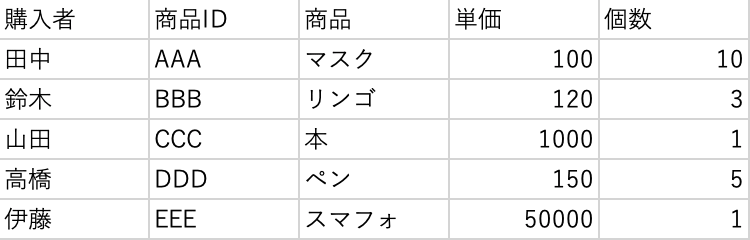
headerの有無
headerが不要な場合は、パラメータ「header」を使います。
- True:出力する
- False:出力しない
となります。
In[]
1 | df.to_csv('output.csv', encoding='cp932', header=False) |
Out[]

データを書き込む際に "列の指定" する方法
書き込む列を指定する場合は、パラメータ「columns」に対象列名をリストで渡します。
In[]
1 | df.to_csv('output.csv', encoding='cp932', columns=['購入者', '商品ID']) |
Out[]
データを書き込む際に "区切り文字" をつける方法
CSVはカンマ区切りですが、カンマ以外も指定できます。
タブ( \t )区切りで出力してみましょう。
パラメータ「 sep 」に’ \t ’を渡します。
In[]
1 | df.to_csv('output.csv', encoding='cp932', sep='\t') |
テキストエディタでタブ区切りになっているのが確認できます。

CSVの "書き込みモード" について
CSVの書き込みモードは3つあります。
書き込みモードの種類
| モード | 内容 |
| w(初期値) | 新規、上書き |
| x | 新規 |
| a | 追加 |
mode 」で指定します。ファイル名を output_append.csv に変更して、2回出力してみましょう。
In[]
1 2 | df.to_csv('output_append.csv', encoding='cp932', mode='a') df.to_csv('output_append.csv', encoding='cp932', mode='a') |
Out[]
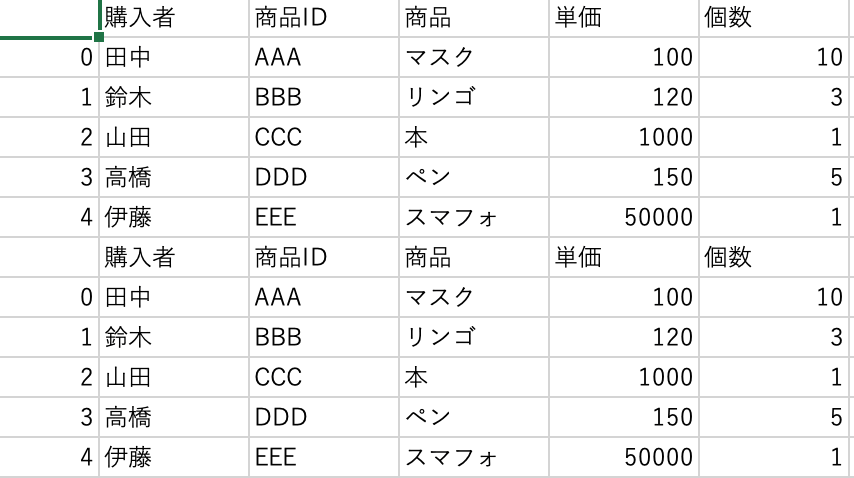
データがファイルの末尾に追加されていますが、2回目も header が含まれていますね。
これでは、データが汚いので、ファイルがある場合は、header=False とした方が良さそうです。
ファイルの有無は下記で確認できます。
In[]
1 | os.path.exists('output_append.csv') |
下記のようなコードをすると、ファイルがない場合は、header を False とすることができます。
In[]
1 2 | df.to_csv('output_append.csv', encoding='cp932', mode='a', header=not os.path.exists('output_append.csv')) |
また、pandas の使用方法については以下の記事にまとめています。一通り本記事でpandasでCSV/TSVファイルを読み込む方法を学習できた方は再度復習してみましょう。
-
【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る