
こんにちは。
産婦人科医で人工知能の研究をしているTommy(Twitter:@obgyntommy)です。
本記事ではPythonのライブラリの1つである pandas の計算処理について学習していきます。
pandasの使い方については、以下の記事にまとめていますので参照してください。
-

【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
データを加工していると、DataFrameを頻用します。
例えば、DataFrame を新しく作ることがありますし、また、numpy や dict などのデータから DataFrame を作ることもあります。
本記事では DataFrame の使い方を習得してを使いこなせるようになりましょう。
なお、Dataframeに関する公式ドキュメントは以下になります。
-
DataFrame — pandas 3.0.5 documentation
続きを見る

なお、pandas.Dataframeに関する公式ドキュメントは以下になります。
-
pandas.DataFrame — pandas 3.0.5 documentation
続きを見る

ここで本記事の学習到達目標です。
本記事の学習目標
- Dataframeの概要を知る
- 行名・列名を変更する際のメソッド
- 空のDataFrameを動的に追加する方法
- 空のDataFrameを高速に動的に追加する方法
今回は、これらの計算がしっかりできるように習得していきましょう。
DataFrame概要

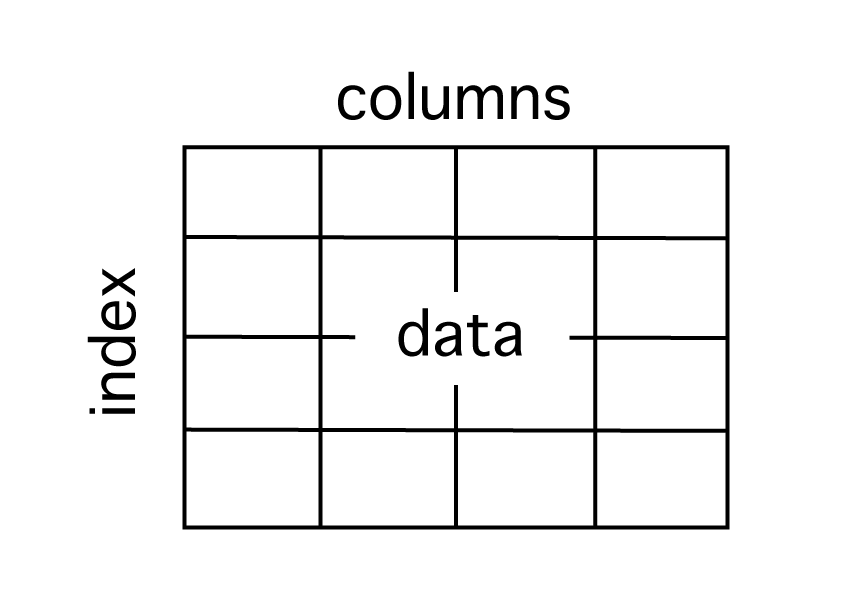
DataFrameはエクセルやデータベースのような2次元の表データです。
index(行)、columns(列)、data(データの値)で構成されています。
indexは行名(行ラベル)、columnsは列名(列ラベル)、dataは実際のデータの値を意味します。
data の代わりに value が用いられることもあります。
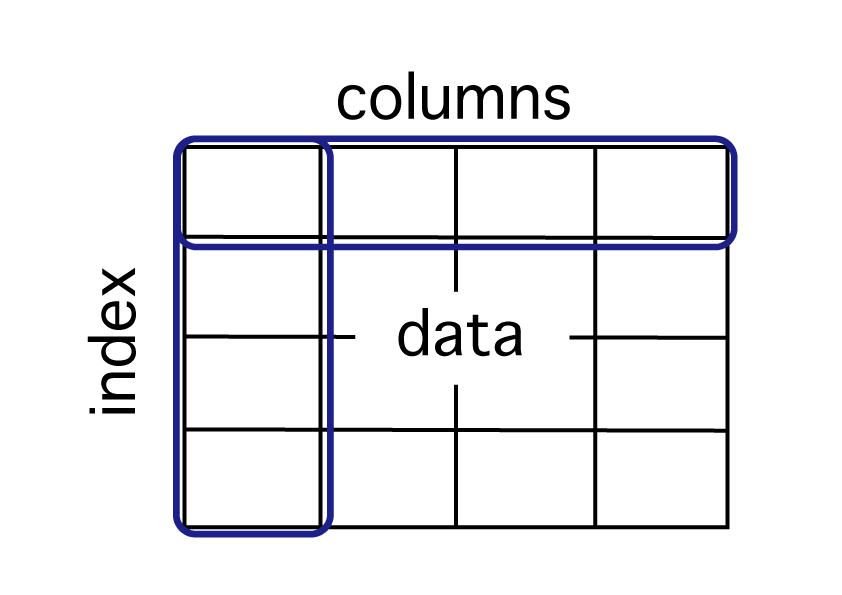
DataFrameとセットで出てくるのがSeriesです。
Series は行や列の1次元のデータで、index(行)、data(データの値)で構成されています。
図の青枠のように、1列、1行分のデータです。
DataFrameを作ってみる

さっそく、DataFrameを色々な方法で作ってみましょう。
繰り返しになりますが、DataFrameはindex、columns、dataの構成です。
これらのデータがあれば、 DataFrameが作れます。
このデータを与え方の違いによって作り方が異なります。
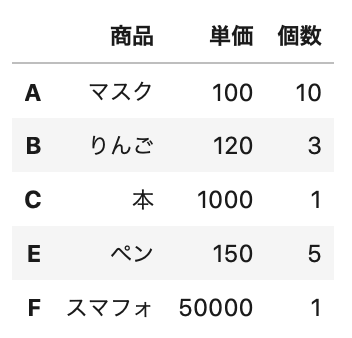
下記のようなデータを作っていきましょう。
先に、pandasのライブラリを読み込んでおいてください。
In[]
1 | import pandas as pd |
listから作る
listからDataFrameを作りましょう。
各構成を list で用意すれば、作ることができます。
それぞれの構成要素を用意してみましょう。
In[]
1 2 3 4 5 6 7 8 9 | # columnsとindex columns = ['商品', '単価', '個数'] index = ['A', 'B', 'C', 'E', 'F'] # data data = [['マスク', 100, 10], ['りんご', 120, 3], ['本', 1000, 1], ['ペン', 150, 5], ['スマフォ',50000, 1]] |
あとは、これをpd.DataFrameの引数に渡します。
In[]
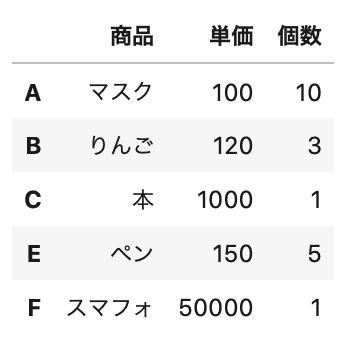
1 2 3 4 5 6 | # DataFrame作成 df = pd.DataFrame(data=data, columns=columns, index=index) # データ確認 df.head() |
Out[]
index、columns は省略しても作れます。
In[]
1 2 3 4 | # DataFrame作成 df = pd.DataFrame(data=data) # データ確認 df.head() |
自動で、0,1,2,…が割り当てられます。
index が 0, 1, 2… で良い場合は、省略することも多いです。
numpyから作る
numpyから作ってみましょう。
list と違いはありませんが、data を numpy にして、作ってみます。
In
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import numpy as np # columnsとindex columns = ['商品', '単価', '個数'] index = ['A', 'B', 'C', 'E', 'F'] # data data = np.array([['マスク', 100, 10], ['りんご', 120, 3], ['本', 1000, 1], ['ペン', 150, 5], ['スマフォ',50000, 1]]) # DataFrame作成 df = pd.DataFrame(data=data, columns=columns, index=index) # データ確認 df.head() |
同じ、結果になりますね。
dictから作る
dictで作ってみましょう。
dict は辞書型と呼ばれるもので、key 値とデータがセットになっているものです。
dict から作ると key 値が列名になります。
key 値を商品、単価、個数としています。
In[]
1 2 3 4 5 6 7 8 9 10 | # data data_dic = { '商品': ['マスク', 'りんご', '本', 'ペン', 'スマフォ'], '単価': [100, 120, 1000, 150, 50000], '個数': [10, 3, 1, 5, 1], } # DataFrame作成 df = pd.DataFrame(data=data_dic) # データ確認 |
Out[]
index が自動割り当てされていますね。
index が必要な場合は list で割り当てることが可能です。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 | index = ['A', 'B', 'C', 'E', 'F'] # data data_dic = { '商品': ['マスク', 'りんご', '本', 'ペン', 'スマフォ'], '単価': [100, 120, 1000, 150, 50000], '個数': [10, 3, 1, 5, 1], } # DataFrame作成 df = pd.DataFrame(data=data_dic, index=index) # データ確認 df.head() |
ただ、これだとデータの dict と index を別に持っていることになります。
データが別の場合、使いにくいですし、バグも出やすくなるでしょう。
どちらかというと、商品IDというデータが dict に含まれている方が自然です。
In[]
1 2 3 4 5 6 7 | # data data_dic = { '商品': ['マスク', 'りんご', '本', 'ペン', 'スマフォ'], '単価': [100, 120, 1000, 150, 50000], '個数': [10, 3, 1, 5, 1], '商品ID': ['A', 'B', 'C', 'E', 'F'], } |
このデータで DataFrame を作ります。
In[]
1 2 3 4 | # DataFrame作成 df = pd.DataFrame(data=data_dic) # データ確認 df.head() |
Out[]
商品IDが列としてデータになっているので、これをset_indexメソッドで「商品ID」列をindexにします。
In[]
1 2 3 4 | # 商品IDをindexに df = df.set_index('商品ID') # データ確認 df.head() |
Out[]
一応、indexになっているかも確認してみましょう。
In[]
1 | df.index |
Out[]
1 | Index(['A', 'B', 'C', 'E', 'F'], dtype='object', name='商品ID') |
商品IDが index になっています。
少し、ごちゃごちゃしてきますが、index も辞書で指定すると、一気に設定できます。
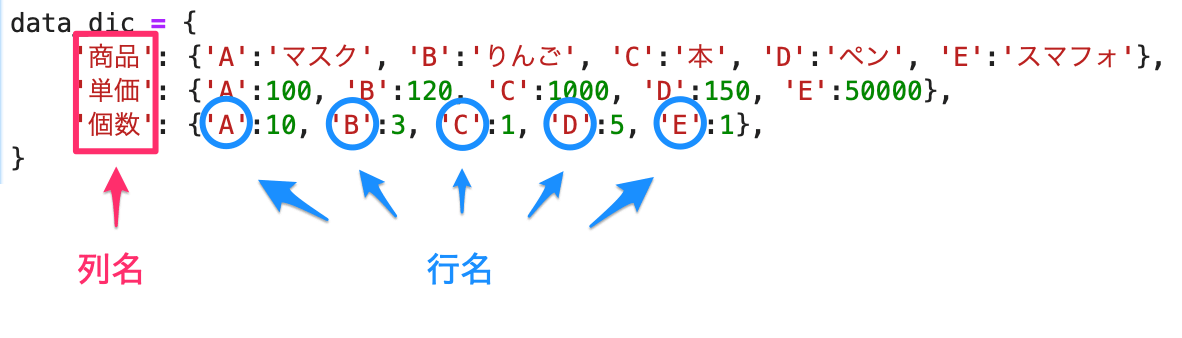
In[]
1 2 3 4 5 6 7 8 9 10 11 | # data data_dic = { '商品': {'A':'マスク', 'B':'りんご', 'C':'本', 'D':'ペン', 'E':'スマフォ'}, '単価': {'A':100, 'B':120, 'C':1000, 'D':150, 'E':50000}, '個数': {'A':10, 'B':3, 'C':1, 'D':5, 'E':1}, } # DataFrame作成 df = pd.DataFrame(data=data_dic) # データ確認 df.head() |
jsonから作る
jsonも辞書型に似ていますが、java script とかweb APIのやり取りで使う文字列です。
記述方法は dict と同じで {} が辞書、[] が配列になります。
dict でも説明した、商品IDを index にする方法と、columns と index を一気に設定する方法を説明します。
まず、商品ID列を用意したデータを使います。
*python で文字列を複数行で扱う時は、”””(ダブルコーテーション3つ)で囲みます。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 | data = """ { "商品ID":["A", "B", "C", "D", "E"], "商品":["マスク", "りんご", "本", "ペン", "スマフォ"], "単価":[100, 120, 1000, 150, 50000], "個数":[10, 3, 1, 5, 1] } """ df = pd.read_json(data) # 商品IDをindexに df = df.set_index('商品ID') #データ確認 df.head() |
Out[]
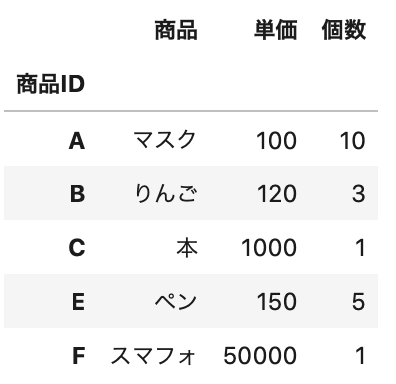
次は、columns と index を一気に指定します。
In[]
1 2 3 4 5 6 7 8 9 | data = """ { "商品":{"A":"マスク", "B":"りんご", "C":"本", "D":"ペン", "E":"スマフォ"}, "単価":{"A":100, "B":120, "C":1000, "D":150, "E":50000}, "個数":{"A":10, "B":3, "C":1, "D":5, "E":1} } """ df = pd.read_json(data) df.head() |
Out[]
行名、列名を変更するメソッドの扱い方

columns と index を変更するにはrenameメソッドを使います。
データは同じものを使っていくので、下記を都度読み直して、実行していってください。
In[]
1 2 3 4 5 6 7 8 9 | data = """ { "商品":{"A":"マスク", "B":"りんご", "C":"本", "D":"ペン", "E":"スマフォ"}, "単価":{"A":100, "B":120, "C":1000, "D":150, "E":50000}, "個数":{"A":10, "B":3, "C":1, "D":5, "E":1} } """ df = pd.read_json(data) df.head() |
Out[]
1つずつ行名・列名を変更する場合
列名を変更する場合は、パラメータ「columns」で変更します。
渡すデータは辞書型と同じ形式で、{‘変更前’: ‘変更後’} を渡します。
columns「商品」を英語の「product」にします。
In[]
1 2 | df = df.rename(columns={'商品':'product'}) df.head() |
Out[]
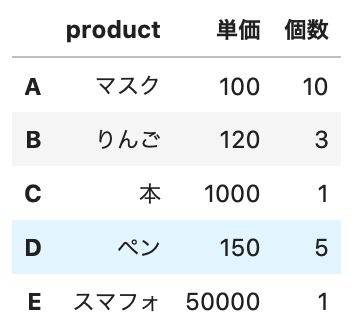
行名を変更する場合は、パラメータ「index」で変更します。
index「A」を小文字の「a」にします。
In[]
1 2 | df = df.rename(index={'A':'a'}) df.head() |
Out[]
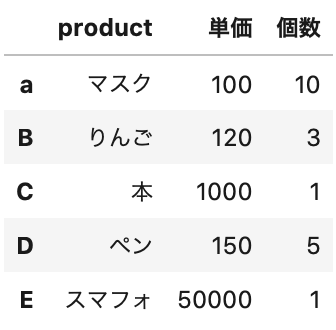
複数の行名・列名を変更する場合
まとめて変更する場合は、{‘変更前’: ‘変更後’, ‘変更前’: ‘変更後’, …} と増やしていきます。
columns をすべて英語に表記にしましょう。
In[]
1 2 | df = df.rename(columns={'商品':'product', '単価':'price', '個数':'num'}) df.head() |
Out[]
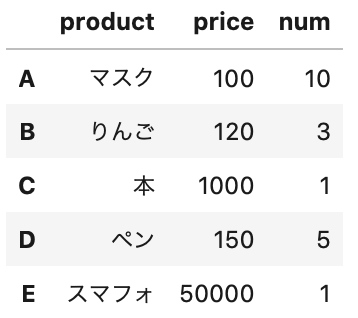
接頭に文字追加する場合
列名の頭に文字列追加していきましょう。
add_prefixメソッドを使います。引数に追加する文字列を渡します。
列名の頭に「 x_ 」を付けます。
In[]
1 2 | df = df.add_prefix('x_') df.head() |
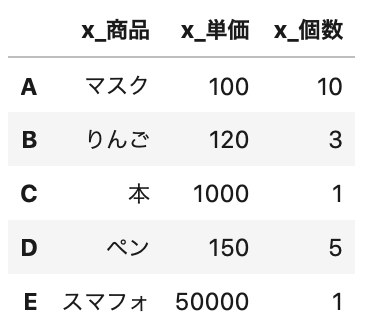
これは例えば、処理前、処理後のデータがあったときに、比較するために2つのDataFrameを1つにするとします。
その時、接頭、接尾に文字列を追加することでわかりやすくします。
接尾に文字追加する場合
列名の末に文字列追加していきましょう。
add_suffixメソッドを使います。引数に追加する文字列を渡します。
末尾に「 _y 」をつけましょう。
In[]
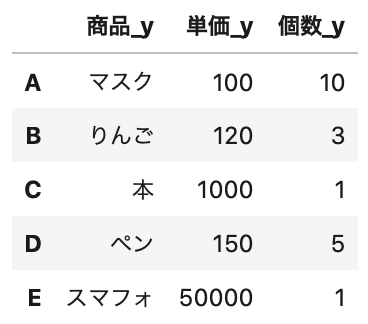
1 2 | df = df.add_suffix('_y') df.head() |
Out[]
空のDataFrameを動的に追加する

list などからデータを追加するのではなく、空の DataFrame を作って、for 文で1行ずつデータを追加してみましょう。
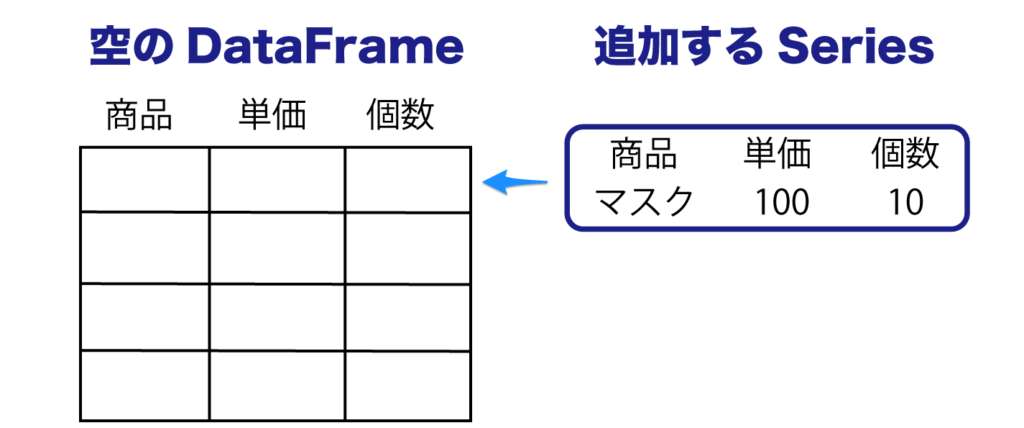
まず、空の DataFrame を作ります。
data を渡さず、列名だけ渡すことで作れます。
In[]
1 2 3 | # 空のDataFrame df = pd.DataFrame(columns=['商品', '単価', '個数']) df.head() |
Out[]

あとは、1行ずつデータを追加します。
DataFrameのappendメソッドを使って、引数にSeriesを渡すことで追加できます。
振り返りになりますが、Seriesはdataとindexを持つ1次元のデータです。
今回は、1行ずつのデータを作っては、追加します。
まず、1行分のSeriesデータを作ってみましょう。
In[]
1 2 | se = pd.Series(['マスク', 100, 10], index=df.columns) se |
Out[]

df.columns で列名を取得できるので、それを index として渡しています。
Series は1次元なので index を指定しますが、空の DataFrame には columns として入ります。
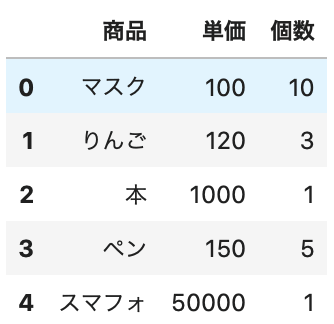
では、for文でデータを追加していきましょう。
appendメソッド に、ignore_index=True とすることで、index が自動で数値が割り当てられます。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 追加するデータ data = [['マスク', 100, 10], ['りんご', 120, 3], ['本', 1000, 1], ['ペン', 150, 5], ['スマフォ',50000, 1]] # for文でデータを順に追加 for product, price, num in data: # 1行のSeriesを作成 se = pd.Series([product, price, num], index=df.columns) # appendメソッドで追加 df = df.append(se, ignore_index=True) # データ確認 df.head() |
Out[]
空のDataFrameを動的に追加する(高速)

先ほどの append を使った方法は、何万行と追加すると処理が遅くなります。
何万行といったデータを動的に追加する場合には、いったん dict にデータを入れて、後で dict のデータを DataFrame にすると高速にできます。
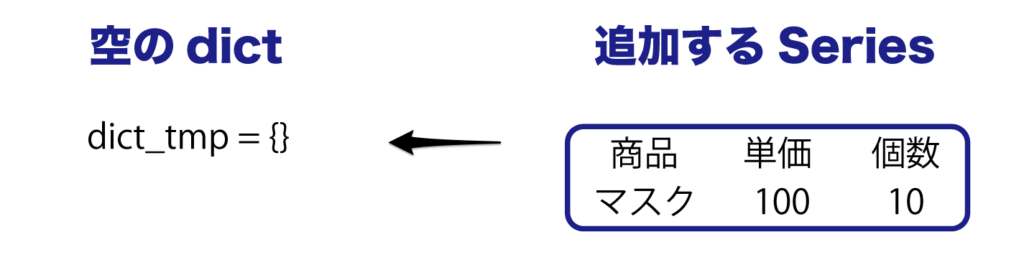
dict のキー値は 0, 1, 2… で追加していきます。
まず、1行ずつの Series データを dict に入れてみましょう。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | # 空のDataFrame df = pd.DataFrame(columns=['商品', '単価', '個数']) # 追加するデータ data = [['マスク', 100, 10], ['りんご', 120, 3], ['本', 1000, 1], ['ペン', 150, 5], ['スマフォ',50000, 1]] # 空のdict 一時的にSeriesのデータをいれる dict_tmp = {} # for文でデータを順に追加 for ind, (product, price, num) in enumerate(data): # 1行のSeriesを作成 se = pd.Series([product, price, num], index=df.columns) # dictに追加 dict_tmp[ind] = se dict_tmp |
0,1,2…をキーとして、値にSeriesのデータを入れました。

このデータを、from_dictメソッドで変換します。
パラメータ「orient」に’columns’、’index’を渡すことで、キー値がどちらで使う指定できます。
今回は、orient = ‘index’とします。
In[]
1 2 3 | df = df.from_dict(dict_tmp, orient="index") # データ確認 df.head() |
Out[]
これで、高速にDataFrameが作れました。
おまけ
どれだけ高速化、比較してみましょう。
append を使った方で、1000回ループします。
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # 空のDataFrame df = pd.DataFrame(columns=['商品', '単価', '個数']) # 追加するデータ data = [['マスク', 100, 10], ['りんご', 120, 3], ['本', 1000, 1], ['ペン', 150, 5], ['スマフォ',50000, 1]] start = time.time() # for文でデータを順に追加 for i in range(1000): for product, price, num in data: # 行のシリーズを作成 se = pd.Series([product, price, num], index=df.columns) # appendメソッドで追加 df = df.append(se, ignore_index=True) elapsed_time = time.time() - start print ("elapsed_time:{0}".format(elapsed_time) + "[sec]") # データ確認 df.head() |
Out[]
1 | elapsed_time:9.50581669807434[sec] |
高速な方法
In[]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | # 空のDataFrame df = pd.DataFrame(columns=['商品', '単価', '個数']) # 追加するデータ data = [['マスク', 100, 10], ['りんご', 120, 3], ['本', 1000, 1], ['ペン', 150, 5], ['スマフォ',50000, 1]] # 一時的なデータおきば dict_tmp = {} start = time.time() # for文でデータを順に追加 for i in range(1000): # for文でデータを順に追加 for ind, (product, price, num) in enumerate(data): # 行のシリーズを作成 se = pd.Series([product, price, num], index=df.columns) # appendメソッドで追加 dict_tmp[ind] = se elapsed_time = time.time() - start print ("elapsed_time:{0}".format(elapsed_time) + "[sec]") df = df.from_dict(dict_tmp, orient="index") # データ確認 df.head() |
Out[]
1 | elapsed_time:0.4443683624267578[sec] |
データによると思いますが、今回は約20倍くらいの差があります。
また、pandas の使用方法については以下の記事にまとめています。一通り本記事でpandasでDataframe使用する方法を学習できた方は再度復習してみましょう。
-
【Python】Pandasの使い方【基本から応用まで全て解説】
続きを見る
人気記事 【入門から上級レベルまで】人工知能・機械学習の独学におすすめの本25選
人気記事 無料あり:機械学習エンジニアの僕がおすすめするAI(機械学習)特化型プログラミングスクール3社